字体爬虫
查看字体映射
直接用浏览器人工看:
<!DOCTYPE html>
<html>
<head>
<style type="text/css">
@font-face { font-family: test; src: url(mpepc5unpb.woff); }
div {
font-family: test;
font-size: 80px;
text-align: center;
margin: 200px 0;
}
</style>
</head>
<body>
<div>
0123456789
</div>
</body>
</html>
上文中我们利用了浏览器,这里我选择使用 SDL。
#include <stdio.h>
#include <SDL2/SDL.h>
#include <SDL2/SDL_ttf.h>
#include <SDL2/SDL_image.h>
int main(void)
{
if(TTF_Init() == -1) {
printf("error: %s\n", TTF_GetError());
return 1;
}
TTF_Font *font = TTF_OpenFont("test.woff", 50);
if(font == NULL) {
printf("error: %s\n", TTF_GetError());
return 1;
}
SDL_Color black = { 0x00, 0x00, 0x00 };
SDL_Surface *surface = TTF_RenderText_Solid(font, "0123456789", black);
if(surface == NULL) {
printf("error: %s\n", TTF_GetError());
return 1;
}
IMG_SavePNG(surface, "test.png");
return 0;
}
SDL 渲染速度非常快,结果也很清楚,用来 OCR 应该足够了。
图形识别这一块我并没有什么太多经验,但是没关系,感谢开源世界。我们 Google OCR, 很容易就会找到一个看起来很厉害的库 tesseract。
项目本身是 C++ 的,我们可以直接用 C++ 调用。但是因为后面我打算使用 Go 写一个完整的关注人数爬虫,所以这里我们使用 Go 来调用。
安装 Go 的绑定 gosseract,然后使用如下代码来试试:
package main
import (
"fmt"
"github.com/otiai10/gosseract/v2"
)
func main() {
client := gosseract.NewClient()
defer client.Close()
client.SetImage("test.png")
client.SetWhitelist("0123456789")
text, _ := client.Text()
fmt.Println(text)
}
然后我们很顺利地就得到了结果,开源万岁!🎉
加上请求断点
如果试了用假数据也就是96809和字体 ID mpepc5unpb来搜索,都没有任何结果。
只能说我们的运气不太好,这里情况实在太多了,有可能返回的值经过了一定的处理比如
base64或者rot13,也有可能是多接口返回然后再拼接组装。我们没办法进一步验证,
只能放弃这条路。
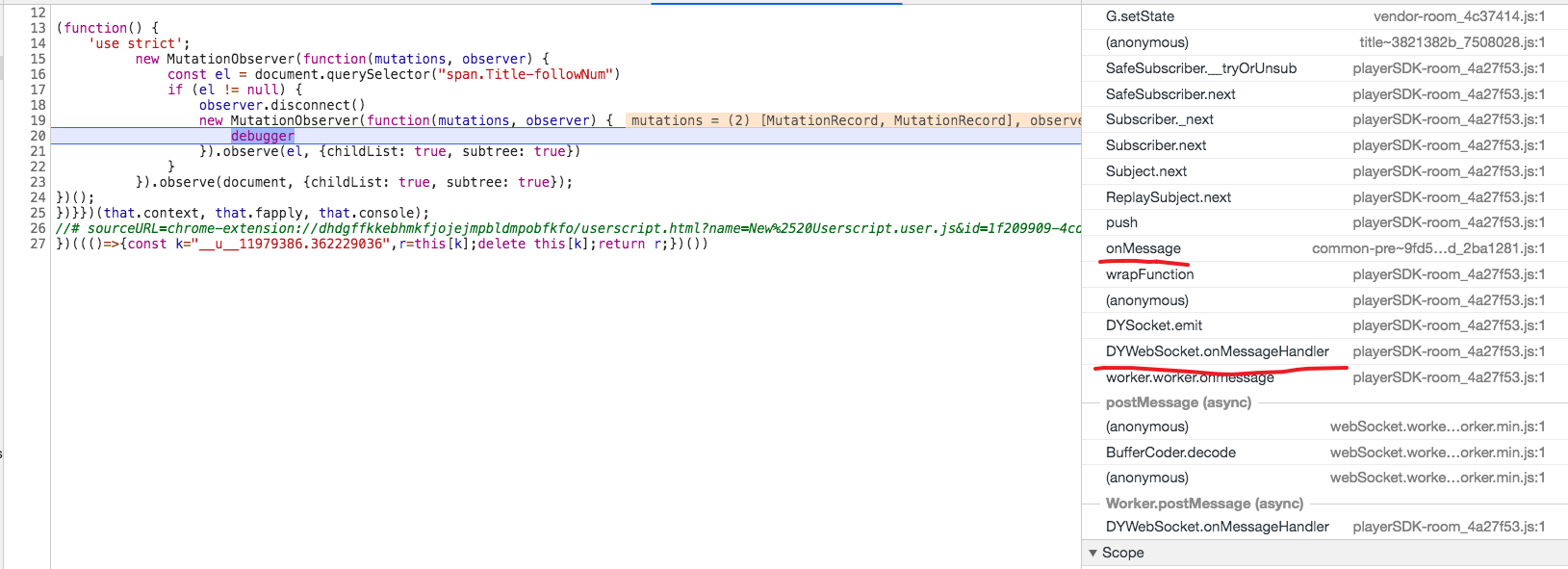
换个思路,请求到了数据以后,JS 代码一定会调用相关 API 去修改 DOM, 能不能监听到这个动作?在它修改 DOM 的时候打上断点,这样就可以通过调用栈知道是哪段 JS 在做此操作,然后顺腾摸瓜找到对应的接口。
答案是是可以的,通过使用MutationObserver我们可以任意监听 DOM 的修改事件。
new MutationObserver((mutations, observer) => {
const el = document.querySelector("span.Title-followNum")
if (el != null) {
observer.disconnect()
new MutationObserver((mutations, observer) => {
debugger
}).observe(el, {childList: true, subtree: true})
}
}).observe(document, {childList: true, subtree: true})
通过 Tampermonkey 加载上面的代码,刷新,等待断点的触发。
websocket协议解析
从上面的调用栈可以看出,数据来源自 WebSocket。 去 Network 面板中看一下,果然是这样。
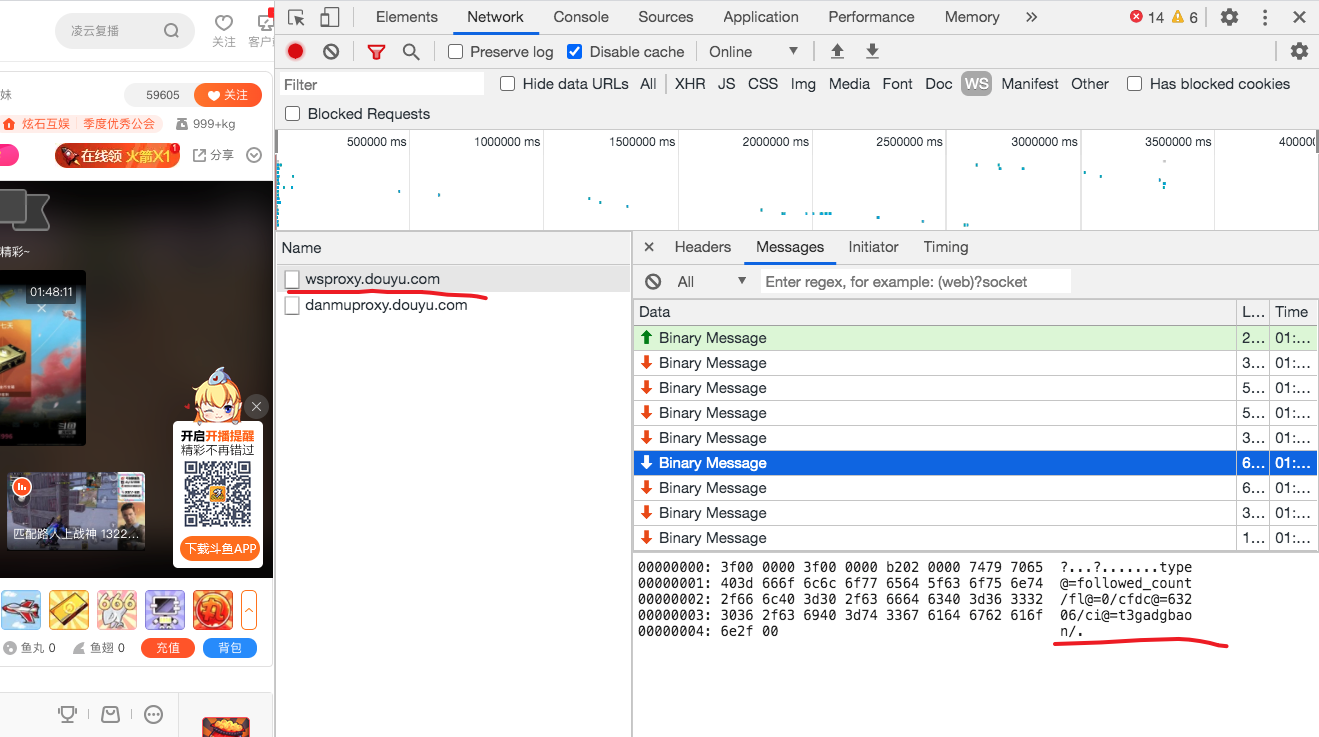
这个消息格式很好理解,我们可以猜到cfdc@=63206表示字符为63206,ci@=t3gadgbaon
表示字体 ID 是t3gadgbaon,和 DOM 对照一下,确实如此。
至此我们的数据源问题解决了一半,我们知道了数据是来自 WebSocket 发送的响应。 但是,如何程序化去获取这个响应?
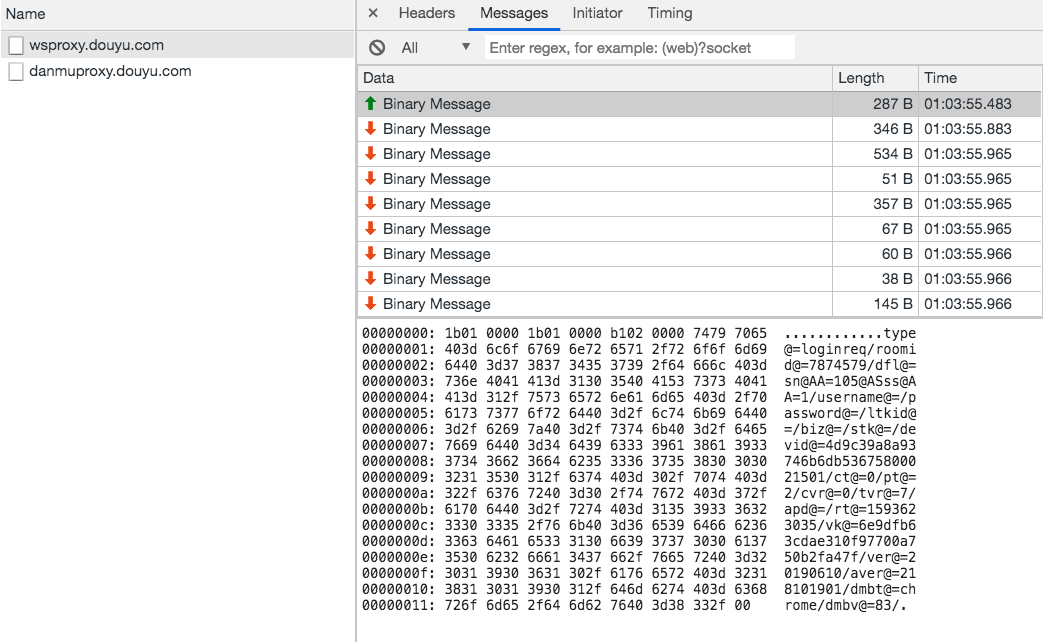
虽然是二进制消息,但是可以看到消息主体都是可读的文本,很明显,斗鱼这里是自己实现了一个内部协议格式。
开头 12 个自己字节暂时不清楚什么含义,然后紧跟着一段键值对数据,使用@=连接键和值,使用/分割,最后跟上/\x00。
多查看几个直播间以后,对于开头的 12 个字节,我们不难分析出前四个字节和消息长度有关,
使用Little Endian,中间四个字节和前四个字节相同,而最后四个字节是固定值0xb1020000。
上面的消息长度是 287 个字节,而0x0000011b= 283,所以,长度编码的值实际上是整个消息的长度减去 4。
这里设计其实挺奇怪的,长度信息比实际长度少了四个字节,同时开头又多了四个字节的冗余数据, 怎么看怎么都像是设计失误,第二个四字节是多余的。对于一个协议来说,作为外部人员, 我们是永远无法弄清楚有些问题的成因的。可能这四个字节有其他用处,可能就是设计失误, 也有可能一开始没有这四个字节,后来因为 bug 不小心加上了,然后为了后向兼容,就一直带上了。
现在我们来看具体的键值对:
type@=loginreq roomid@=7874579 dfl@=sn@AA=105@ASss@AA=1 username@= password@= ltkid@= biz@= stk@= devid@=4d9c39a8a93746b6db53675800021501 ct@=0 pt@=2 cvr@=0 tvr@=7 apd@= rt@=1593623035 vk@=6e9dfb63cdae310f97700a750b2fa47f ver@=20190610 aver@=218101901 dmbt@=chrome dmbv@=83
这些参数中,type, roomid, devid 都很好理解,dfl, ver, aver, dmbt,
dmbv 这些看起来像是不重要的信息携带字段。
rt 很容易发现是一个秒级时间戳,现在唯一剩下的就是 vk 这个字段。
我们可以通过修改字段值的方式来大致判断字段的作用和重要性。
如果我们原封不动的使用这个请求体(在检查器中右键选择 Copy message... -> Copy as hex) 请求斗鱼的 WebSocket 服务,会发现一开始是有正常响应的,但是过几分钟后就报错了。
const WebSocket = require("ws")
const ws = new WebSocket("wss://wsproxy.douyu.com:6672/")
ws.on("open", () => {
ws.send(Buffer.from("1b0100001b010000b102000074797065403d6c6f67696e" +
"7265712f726f6f6d6964403d373837343537392f64666c403d736e4041413" +
"d31303540415373734041413d312f757365726e616d65403d2f7061737377" +
"6f7264403d2f6c746b6964403d2f62697a403d2f73746b403d2f646576696" +
"4403d34643963333961386139333734366236646235333637353830303032" +
"313530312f6374403d302f7074403d322f637672403d302f747672403d372" +
"f617064403d2f7274403d313539333632333033352f766b403d3665396466" +
"6236336364616533313066393737303061373530623266613437662f76657" +
"2403d32303139303631302f61766572403d3231383130313930312f646d62" +
"74403d6368726f6d652f646d6276403d38332f00", "hex"))
})
ws.on("message", payload => {
console.log(payload.toString())
})
很明显,斗鱼会校验 rt 的值,如果服务器时间和 rt 时间超过一定间隔,那么会返回错误,这是一个很常见的设计。
如果我们修改了一下 vk,也会得到一个错误,这说明 vk 是类似签名的东西,而不是什么信息携带字段,服务端会校验它的有效性。
对于 dfl, ver, aver, dmbt, dmbv 这些字段,我们会发现随便修改都不会影响结果,说明我们的之前的猜测是正确的。
所以,现在剩下的问题就是要搞清楚 vk 的签名规则,这个只能从源码入手。
网络请求调用栈
Chrome 检查器中对于每个网络请求都会显示它的Initiator,也就是这个请求是什么代码发起的。
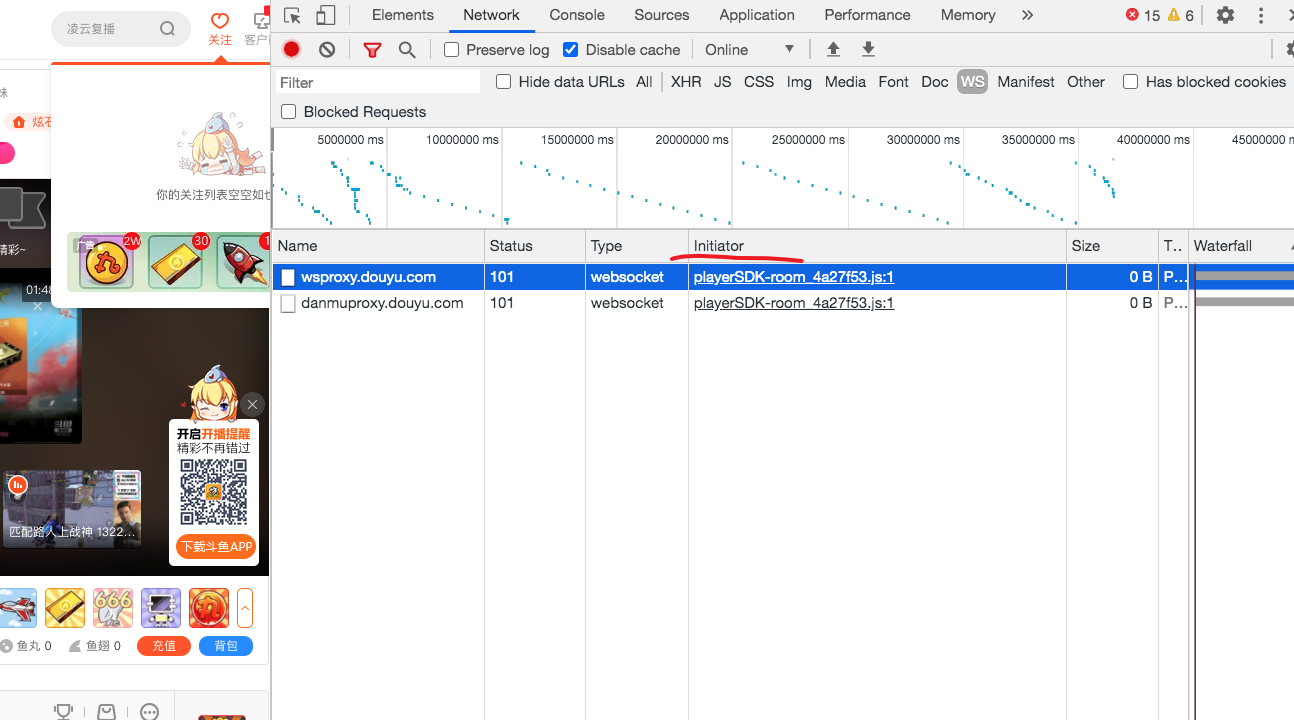
鼠标放上去可以看到完整的调用栈。
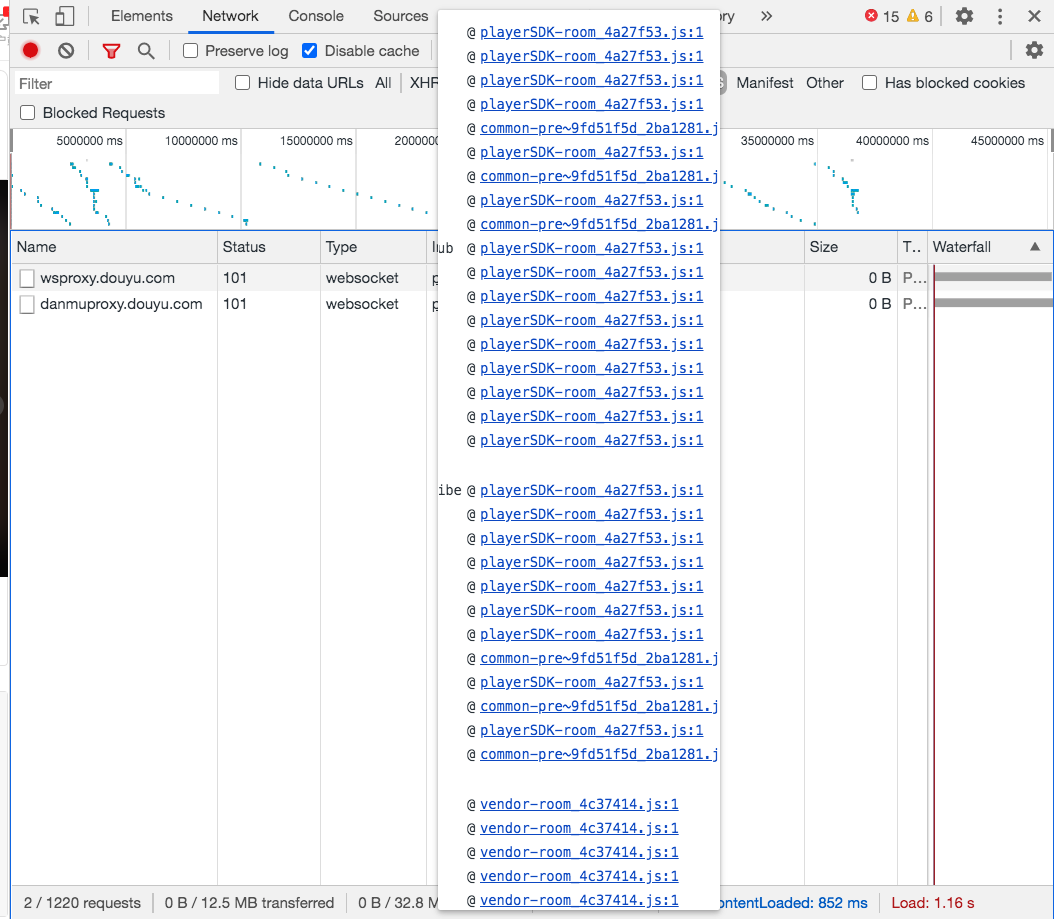
我们的思路是找到发送消息的地方,打上断点,通过调用栈往上找。
所以打开最上面的playerSDK-room_4a27f53.js文件,搜索关键字 send,很容易找到下面这段代码。
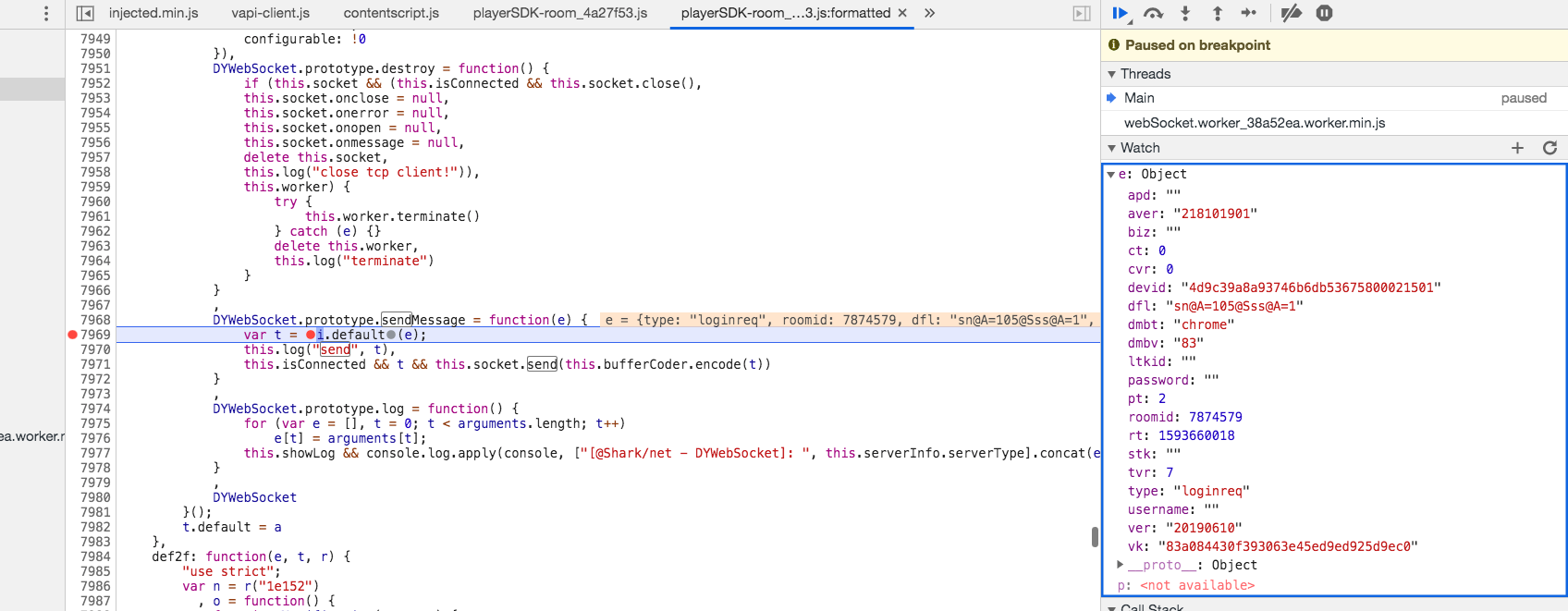
通过断点我们可以看出,登录消息就是通过这里发送的,因为e是登录的消息体。
展开调用栈,会发现有一个函数叫做userLogin,点进去。
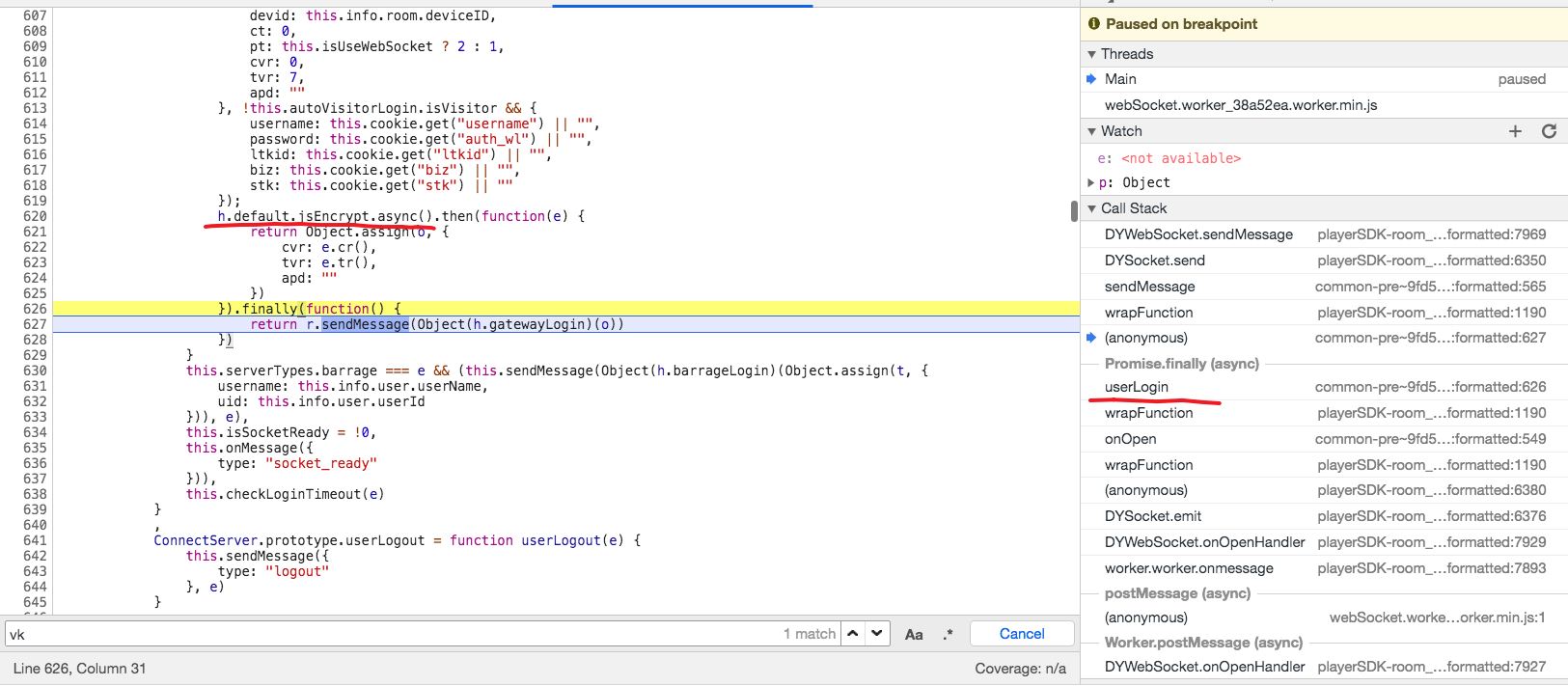
可以发现我们来到了common-pre~9fd51f5d.js文件,可以猜到h.default.jsEncrypt.async()这段代码应该就是签名相关的代码。
我们可以断点进这个函数,然后继续找。或者,我们直接搜索vk。
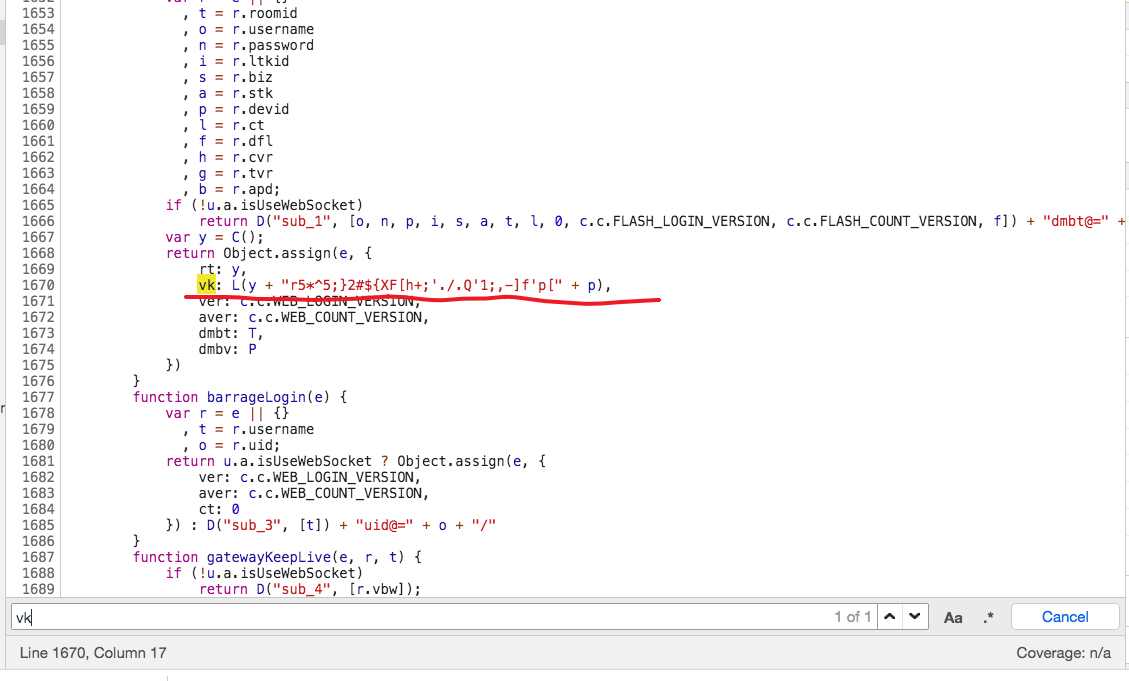
然后我们就发现vk的值等于L(y + "r5*^5;}2#${XF[h+;'./.Q'1;,-]f'p[" + p)。
到这里就简单了,通过断点可以发现y就是rt,p是devid,而L是一个求md5值的函数。
所以vk的签名算法是vk = md5(rt + "r5*^5;}2#${XF[h+;'./.Q'1;,-]f'p[" + devid)
现在整个消息体的结构我们都清楚了,我们试着构造消息体请求斗鱼服务器看看能不能得到响应。
const encode = obj => Object.keys(obj).map(k => `${ k }@=${ obj[k] }`).join("/")
const decode = str => {
return str.split("/").reduce((acc, pair) => {
const [key, value] = pair.split("@=")
acc[key] = value
return acc
}, {})
}
const crypto = require("crypto")
const md5Hash = crypto.createHash("md5")
const md5 = payload => {
return md5Hash.update(payload).digest("hex")
}
// 4-byte length, 4-byte length, 0xb102, 0x0000
const getPayload = obj => {
const arr = [0, 0, 0, 0, 0, 0, 0, 0, 0xb1, 0x02, 0x00, 0x00]
const objEncoded = encode(obj) + "/\x00"
arr.push(...objEncoded.split("").map(c => c.charCodeAt(0)))
const payload = Buffer.from(arr)
const dv = new DataView(payload.buffer, payload.byteOffset)
const length = payload.length - 4
dv.setUint32(0, length, true)
dv.setUint32(4, length, true)
return payload
}
ws.on("open", () => {
// 这个随便填写一个
const devID = "4d9c39a8a93746b6db53675800021501"
const rt = (new Date().getTime() / 1000) >> 0
const obj = {
type: "loginreq",
roomid: roomID,
devid: devID,
rt: rt,
vk: md5(rt + "r5*^5;}2#${XF[h+;'./.Q'1;,-]f'p[" + devID),
}
const payload = getPayload(obj)
ws.send(payload)
})
ws.on("message", payload => {
const data = decode(payload.slice(12).toString())
if(data.type === "followed_count") {
console.log(data)
} else {
console.log(data.type)
}
})
字体反爬实现方法
讲完了进攻,现在我们来看看如果我们站在防守方,需要使用这种技巧来反爬,该怎么做?
字体反爬的核心是随机生成一个映射,根据映射生成字体,然后返回字体和假数据给到前端。
这个时候我们就需要了解一下字体的文件格式了。常见的字体格式有ttf,otf,woff。
其中woff是一个包装格式,里面的字体不是 ttf 就是 otf 的,所以真正的存储格式只有两种,ttf 和 otf。
这两种格式很明显都是二进制格式,没法直接打开看。但是,幸运的是,字体有一个格式叫做ttx,是一个 XML 的可读格式。
我们的基本思路是:
- 裁剪字体:根据一个基础字体裁剪掉我们不需要的字符,比如斗鱼这种情况,我们只需要数字即可
- 将字体转换成 ttx 格式打开
- 找到字符和图形的映射
- 修改这个映射
- 再导出字体为 ttf
这里我们使用 fonttools 这个强大的 Python 库来进行后续的操作。
我们以开源字体 Hack 为例。
我们先来裁剪字体。安装好 fonttools 以后会默认安装几个工具,其中之一是 pyftsubset,这个工具就可以用来裁剪字体。
$ pyftsubset hack.ttf --text="0123456789" WARNING: TTFA NOT subset; don't know how to subset; dropped
上面的 warning 不用介意,运行完毕之后我们得到了hack.subset.ttf,这个便是裁剪后的字体,只支持渲染 0 ~ 9。
接下来转换字体为可读的 ttx 格式。同样,fonttools 自带了一个工具叫做 ttx,直接使用即可。
$ ttx hack.subset.ttf Dumping "hack.subset.ttf" to "hack.subset.ttx"... Dumping 'GlyphOrder' table... Dumping 'head' table... Dumping 'hhea' table... Dumping 'maxp' table... Dumping 'OS/2' table... Dumping 'hmtx' table... Dumping 'cmap' table... Dumping 'fpgm' table... Dumping 'prep' table... Dumping 'cvt ' table... Dumping 'loca' table... Dumping 'glyf' table... Dumping 'name' table... Dumping 'post' table... Dumping 'gasp' table... Dumping 'GSUB' table...
我们会发现目录下多了一个hack.subset.ttx文件,打开观察一下。
很容易就可以发现,cmap 标签中定义了字符和图形的映射。
<cmap>
<tableVersion version="0"/>
<cmap_format_4 platformID="0" platEncID="3" language="0">
<map code="0x30" name="zero"/><!-- DIGIT ZERO -->
<map code="0x31" name="one"/><!-- DIGIT ONE -->
<map code="0x32" name="two"/><!-- DIGIT TWO -->
<map code="0x33" name="three"/><!-- DIGIT THREE -->
<map code="0x34" name="four"/><!-- DIGIT FOUR -->
<map code="0x35" name="five"/><!-- DIGIT FIVE -->
<map code="0x36" name="six"/><!-- DIGIT SIX -->
<map code="0x37" name="seven"/><!-- DIGIT SEVEN -->
<map code="0x38" name="eight"/><!-- DIGIT EIGHT -->
<map code="0x39" name="nine"/><!-- DIGIT NINE -->
</cmap_format_4>
...
</cmap>
0x30也就是字符0对应name="zero"的 TTGlyph,TTGlyph 中定义了渲染要用的数据,也就是一些坐标。
<TTGlyph name="zero" xMin="123" yMin="-29" xMax="1110" yMax="1520">
<contour>
<pt x="617" y="-29" on="1"/>
<pt x="369" y="-29" on="0"/>
<pt x="246" y="165" on="1"/>
<pt x="123" y="358" on="0"/>
<pt x="123" y="745" on="1"/>
<pt x="123" y="1134" on="0"/>
<pt x="246" y="1327" on="1"/>
<pt x="369" y="1520" on="0"/>
<pt x="616" y="1520" on="1"/>
<pt x="864" y="1520" on="0"/>
<pt x="987" y="1327" on="1"/>
<pt x="1110" y="1134" on="0"/>
<pt x="1110" y="745" on="1"/>
<pt x="1110" y="-29" on="0"/>
</contour>
...
</TTGlyph>
那么怎么制作混淆字体的方法就不言而喻了,我们修改一下这个 XML,
把TTGlyph(name="zero")标签的 zero 换成 eight 然后把TTGlyph(name="eight")
标签的eight换成zero,保存文件为fake.ttx。
导出 ttx 到 ttf 依然是使用 ttx 工具。
$ ttx -o fake.ttf fake.ttx Compiling "fake.ttx" to "fake.ttf"... Parsing 'GlyphOrder' table... Parsing 'head' table... Parsing 'hhea' table... Parsing 'maxp' table... Parsing 'OS/2' table... Parsing 'hmtx' table... Parsing 'cmap' table... Parsing 'fpgm' table... Parsing 'prep' table... Parsing 'cvt ' table... Parsing 'loca' table... Parsing 'glyf' table... Parsing 'name' table... Parsing 'post' table... Parsing 'gasp' table... Parsing 'GSUB' table...
使用上文提到的 HTML 使用fake.ttf渲染 0 ~ 9,可以看到,我们成功地制作了一个混淆字体。
genfont.py是我使用 Python 编写的脚本,可以自动生成任意数量的混淆字体。
#!/usr/bin/env python
# 生成用于数字混淆的字体文件用于反爬
# 即字体对于数字的渲染时错误的,例如数字 1 会渲染成 5
# ./genfont.py <font-file> <count>
# 生成字体在 result/generated 目录中
import sys
import os
import subprocess
from pathlib import Path
import random
from bs4 import BeautifulSoup
import copy
import hashlib
names = ["zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine"]
# must contain glyphs with name "zero" "one" .. "nine"
def check_font(ttx):
for name in names:
if ttx.find("TTGlyph", attrs={"name": name}) is None:
return False
return True
def gen(ttx):
mapping = names[:]
random.shuffle(mapping)
target = copy.copy(ttx)
for name in names:
target.find("TTGlyph", {"name": name})["id"] = name
for idx, name in enumerate(names):
tmp = target.find("TTGlyph", attrs={"id": mapping[idx]})
tmp.attrs = {}
for k, v in ttx.find("TTGlyph", attrs={"name": name}).attrs.items():
tmp[k] = v
content = target.prettify()
name = hashlib.md5(content.encode("utf8")).hexdigest()[:10] + "." + "".join([str(names.index(x)) for x in mapping])
print(f"Generate temporary ttx: {name}.ttx")
target_ttx_path = os.path.join("result", "tmp", f"{name}.ttx")
with open(target_ttx_path, "w") as f:
f.write(content)
target_ttf_path = os.path.join("result", "generated", f"{name}.ttf")
print(f"Generate target ttf: {target_ttf_path}")
subprocess.run(f"ttx -o {target_ttf_path} {target_ttx_path}", shell=True, check=True)
def run(font_file, count):
ttx_name = os.path.splitext(font_file)[0] + ".ttx"
ttx_path = os.path.join("result", "tmp", ttx_name)
if not Path(ttx_path).exists():
print("Convert ttf to ttx..")
subprocess.run(f"ttx -o {ttx_path} {font_file}", shell=True, check=True)
with open(ttx_path) as f:
ttx = BeautifulSoup(f, "xml")
if not check_font(ttx):
print("font must contain glyphs with name 'zero', 'one', 'two' .. 'nine'")
exit(1)
for _ in range(count):
gen(ttx)
if __name__ == "__main__":
if len(sys.argv) < 3:
print(f"usage: ./genfont.py <font-file> <count>")
exit(1)
# create necessary dirs
os.makedirs(os.path.join("result", "generated"), exist_ok=True)
os.makedirs(os.path.join("result", "tmp"), exist_ok=True)
run(sys.argv[1], int(sys.argv[2]))
使用 hack.subset.ttf 为基础生成 20 个混淆字体
$ ./genfont.py hack.subset.ttf 20 .... $ ls result/generated # 结果存储在这个目录中 0018fb8365.7149586203.ttf 267ccb0e95.8402759136.ttf 08a9457ab9.3958406712.ttf 281ef45f09.2154786390.ttf 1bbdd405ca.9147328650.ttf 788e0c7651.8790526413.ttf 1f985cd725.6417320895.ttf 5433d36fde.1326570894.ttf 2d56def315.8962135047.ttf 6844549191.3597082416.ttf 6bd27a4bac.0658392147.ttf a422833064.8416930752.ttf 6e337094a4.0754261839.ttf c7f0591c38.5761804329.ttf 9a0e22d6ad.9173452860.ttf d3269bd2ce.0384976152.ttf 9a407f17c1.8379426105.ttf f97691cc25.1587964230.ttf 44a428c37d.3602974581.ttf ffe2c54286.6894312057.ttf
文件名的形式为fontID.mapping.ttf。比如 0018fb8365.7149586203.ttf 这个字体会将 0 渲染为 7。