Java 基础
常用类型
String
字符串不变性
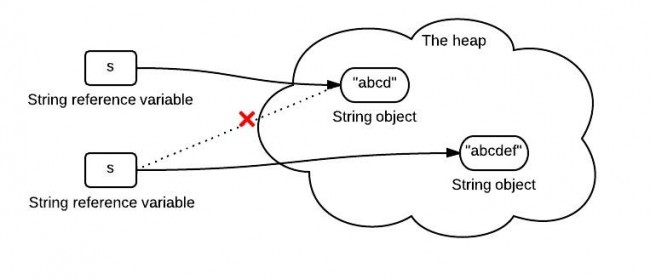
String是所有语言中最常用的一个类。我们知道在Java中,String是不可变的、final的。 Java在运行时也保存了一个字符串池(String pool),这使得String成为了一个特别的类。
String Immutability。对于下面的代码:
String s = "abde";
s = s.concat("ef");
不可变性的优点
String类不可变性的好处:
- 只有当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约 很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。但如果字符串是 可变的,那么String interning将不能实现(译者注:String interning是指对不同的 字符串仅仅只保存一个,即不会保存多个相同的字符串。),因为这样的话,如果 变量改变了它的值,那么其它指向这个值的变量的值也会一起改变。
- 如果字符串是可变的,那么会引起很严重的安全问题。譬如,数据库的用户名、密码都是 以字符串的形式传入来获得数据库的连接,或者在socket编程中,主机名和端口都是以 字符串的形式传入。因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以 钻到空子,改变字符串指向的对象的值,造成安全漏洞。
- 因为字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享。 这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。
-
类加载器要用到字符串,不可变性提供了安全性,以便正确的类被加载。譬如你想加载
java.sql.Connection类,而这个值被改成了myhacked.Connection,那么会对你的 数据库造成不可知的破坏。 - 因为字符串是不可变的,所以在它创建的时候hashcode就被缓存了,不需要重新计算。 这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是 HashMap中的键往往都使用字符串。
以上就是我总结的字符串不可变性的好处。
常用Unicode转义
Java 中Unicode转义以 \u开头,网上转来的字符串可能是其他程序生成的。
比如"在Java中转义为\u0022而Python中为 \x22。
这样的文本转为Java字符串的方法是开关替换为\u00然后再用CommonLangs工具转为
字符串:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.4</version>
</dependency>
import org.apache.commons.lang3.StringEscapeUtils
String ue = x.replaceAll("""\\x""", """\\u00""")
StringEscapeUtils.unescapeJava(ue)
Integer
valueOf(String)的特殊行为
结果缓存
Integer.valueOf("127")==Integer.valueOf("127") // true
Integer.valueOf("128")==Integer.valueOf("128") // false why ?!!
valueOf会返回一个Integer(整型)对象,当被处理的字符串在-128和127(包含边界)
之间时,返回的对象是预先缓存的。
这就是为什么第一行的调用会返回true。-127这个整型对象是被缓存的(所以两次
valueOf返回的是同一个对象)。
第二行的调用返回false是因为128没有被缓存,所以每次调用,都会生成一个新的整型
对象,因此两个128整型对象是不同的对象。
重要的是你要知道在上面的比较中,你实际进行比较的是integer.valueOf返回的对象引用 ,所以当你比较缓存外的整型对象时,相等的判断不会返回true,就算你传个valueOf的值 是相等的也没用。想让这个判断返回true,你需要使用equals()方法。
开箱转换
Integer.parseInt("128")==Integer.valueOf("128") // true
parseInt()返回的不是整型对象,而是一个int型基础元素。这就是为什么最后一个判断会
返回true,第三行的判断中,在判断相等时,实际比较的是128 == 128,所以它必然是
相等的。
一个unboxing conversion(一种比较时的转换,把对对象的引用转换为其对应的原子类型
)在第三行的比较中发生了。因为比较操作符使用了==同时等号的两边存在一个int型
和一个Integer对象的引用。这样的话,等号右边返回的Integer对象被进一步转换成了
int数值,才与左边进行相等判断。
所以在转换完成后,你实际比较的是两个原子整型数值。这种转换正是你在比较两个原子 类型时所期待看到的那样,所以你最终比较了128等于128。
二进制位操作
前缀:
- 十进制:直接写数字即可
- 二进制:0b或0B开头;如:0b01011000 代表十进制 88
- 八进制:0 开头;如:0130 代表十进制 88 (1x64+3x8)
- 十六进制:0x或0X开头;如:0x58 代表 88 (5x16+8)
后缀:
- 0x?? 若小于127 则按byte算,大于则按int类型算
- 0xFF默认为int类型
- 若声明为long添加后缀:L或l:如:0xFFL 或 0xFFl
- 带小数的值默认为double类型;如:0.1
- 若声明为float添加后缀:f 或 F:如:0.1F
- 若声明为double添加后缀:d或D:如:1D
数值的二进制赋值:
scala> Integer.toBinaryString(33) res0: String = 100001
数值的二进制显示:
scala> Integer.toBinaryString(33) res0: String = 100001
按32位更加整齐地显示:
scala> String.format("%32s", Integer.toBinaryString(33)).replace(" ", "0");
res1: String = 00000000000000000000000000100001
基本操作
-
位与 :
a & b -
位或 :
a | b -
位异或 :
a ^ b -
位取反 :
~a -
左移补0 :
a << n -
符号右移 :
a >> n -
无符右移补0 :
a >>> n
无符号byte类型
Java没有无符号字节类型,所以只能用32位的int去掉前24位当作byte来用。
通常是与8位全都是1的值0xFF进行位与操作,这样就只保留最低8位的值,
正好一个字节:
scala> 33 & 0xFF
res2: Int = 33
scala> String.format("%32s", Integer.toBinaryString(33 & 0xFF)).replace(" ","0");
res4: String = 00000000000000000000000000100001
通过拼接实现无符号类型
short类型有两个字节:
- 无符号short范围是\(0 ~ 65535\)
- 带符号short范围是\(-32768 ~ 32767\)
因为Java只有符号类型,所以常常遇到明明一个无符号short可以解决问题不得不用四个字节 的int来存。
如果一定要节省内存空间,那可以把无符号short在二进制层面拆分成两个字节。 这样内存占用和一个无符号的short是一样的。
int n = 0xFF60 ; // 00000000,00000000,11111111,01100000 // 拆成两个byte byte n1 = (byte) n & 0xFF ; // 00000000,00000000,00000000,01100000 byte n2 = (byte) (n >> 8) & 0xFF ; // 00000000,00000000,00000000,11111111 // 还可以再拼回来 val ret = (n1 & 0xFF) | (n2 & 0xFF) << 8; // 11111111,01100000
把每一位作为一个FLAG
static byte a = 0b00000001; static byte b = 0b00000010; static byte c = 0b00000100; static byte d = 0b00001000; byte x = 0b00000000; // 设置FLAG 位或 x = (byte) (x | a); // 取消FLAG 位与标志的反 x = (byte) (x & ~a); // 检查FLAG 位或后是否等于标志 (x & a) == a; // 相同于 (x & a) != 0;
需要注意若对应的a使用了符号位则需要使用0xFF先清理自动补充的符号位。
因为与、或、非等操作默认会将参数转化为int类型进行;
所以会出现自动补充符号位的情况。
序列化
Serializable接口
-
凡是被
static修饰的字段是不会被序列化的 -
凡是被
transient修饰符修饰的字段也是不会被序列化的
public class Student implements Serializable {
private String name;
private Integer age;
private Integer score;
// ... 其他省略 ...
}
public static void serialize( ) throws IOException {
Student student = new Student();
student.setName("CodeSheep");
student.setAge( 18 );
student.setScore( 1000 );
ObjectOutputStream objectOutputStream =
new ObjectOutputStream( new FileOutputStream( new File("student.txt") ) );
objectOutputStream.writeObject( student );
objectOutputStream.close();
System.out.println("序列化成功!已经生成student.txt文件");
System.out.println("==============================================");
}
public static void deserialize( ) throws IOException, ClassNotFoundException {
ObjectInputStream objectInputStream =
new ObjectInputStream( new FileInputStream( new File("student.txt") ) );
Student student = (Student) objectInputStream.readObject();
objectInputStream.close();
System.out.println("反序列化结果为:");
System.out.println( student );
}
Serializable是一个空接口,序列化逻辑是在ObjectOutputStream
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
serialVersionUID号
-
serialVersionUID是序列化前后的唯一标识符 -
默认如果没有人为显式定义过
serialVersionUID,那编译器会为它自动声明一个
Externalizable接口
Externalizable接口它是Serializable接口的子类,
用户要实现的writeExternal()和readExternal()方法,
用来决定如何序列化和反序列化。因为序列化和反序列化方法需要自己实现,
因此可以指定序列化哪些属性,而transient在这里无效。
public UserInfo() {
userAge=20;//这个是在第二次测试使用,判断反序列化是否通过构造器
}
public void writeExternal(ObjectOutput out) throws IOException {
// 指定序列化时候写入的属性。这里仍然不写入年龄
out.writeObject(userName);
out.writeObject(usePass);
}
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
// 指定反序列化的时候读取属性的顺序以及读取的属性
// 如果你写反了属性读取的顺序,你可以发现反序列化
// 的读取的对象的指定的属性值也会与你写的读取方式
// 一一对应。因为在文件中装载对象是有序的
userName=(String) in.readObject();
usePass=(String) in.readObject();
}
数组
声明时不能指定大小:type [] var;或type var []
创建时指定大小:new type var[size]
字面量:{item1, item2, ... }
int[] intArray; //creating array without initializing or specifying size
int intArray1[]; //another int[] reference variable can hold reference of an integer array
int[] intArray2 = new int[10]; //creating array by specifying size
int[] intArray3 = new int[]{1,2,3,4}; //creating and initializing array in same line.
Java中数组可以轻易的转换成ArrayList。ArrayList一个基于索引的集合,它是作为数组的 备选方案。ArrayList的优点是可以改变容量大小,只需要创建个更大的数组然后拷贝内容 到新数组,但你不能改变数组的大小。
List 转数组:
List<String> mails = new ArrayList<>();
String [] mailArr = {};
if (mails.size() > 0) {
mailArr = new String[l.size()];
mails.toArray(mailArr);
}
arrayCopy
Java API同样提供了一些便捷方法通过java.utils.Arrays类去操作数组,通过使用Arrays 你可以排序数组,你可以做二分搜索。
java.lang.System类提供了实用方法拷贝元素到另一个数组。在拷贝内容从一个数组到 另一个数组的时候System.arrayCopy非常强大和灵活。你可以拷贝整个或子数组, 具体看你的需求。System.arraycoy语法:
public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
如你所见,arraycopy允许我们指定索引和长度,能很灵活给你拷贝子数组和存储到需要的 位置或目标数组。这里是一个例子,拷贝前三个元素到目标数组:
public static void main(String args[]) {
int[] source = new int[]{10, 20, 30, 40, 50};
int[] target = new int[5];
System.out.println("Before copying");
for(int i: target){
System.out.println(i);
}
System.arraycopy(source, 0, target, 0, 3);
System.out.println("after copying");
for(int i: target){
System.out.println(i);
}
}
输出:
Before copying 0 0 0 0 0 after copying 10 20 30 0 0
多维数组
int[][] multiArray = new int[2][3];
int[][] multiArray = {{1,2,3},{10,20,30}};
System.out.println(multiArray[0].length);
System.out.println(multiArray[1].length);
显示数组内容
输出内容最常见的方式
// List<String>类型的列表
List<String> list = new ArrayList<String>();
list.add("First");
list.add("Second");
list.add("Third");
list.add("Fourth");
System.out.println(list);
输出:
[First, Second, Third, Fourth]
String数组
String[] array = new String[] { "First", "Second", "Third", "Fourth" };
System.out.println(array.toString());</pre>
输出:
[Ljava.lang.String;@12dacd1
使用Array类输出数组内容
// String数组
String[] array = new String[] { "First", "Second", "Third", "Fourth" };
System.out.println(Arrays.toString(array));
输出:
[First, Second, Third, Fourth]
输出数组的数组
可以使用Arrays.deepToString()方法。
String[] arr1 = new String[] { "Fifth", "Sixth" };
String[] arr2 = new String[] { "Seventh", "Eight" };
// 数组的数组
String[][] arrayOfArray = new String[][] { arr1, arr2 };
// 比较下面的输出
System.out.println(arrayOfArray);
System.out.println(Arrays.toString(arrayOfArray));
System.out.println(Arrays.deepToString(arrayOfArray));
输出:
[[Ljava.lang.String;@1ad086a [[Ljava.lang.String;@10385c1, [Ljava.lang.String;@42719c] [[Fifth, Sixth], [Seventh, Eighth]]
再看下面的完整例子:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class PrintArray {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("First");
list.add("Second");
list.add("Third");
list.add("Fourth");
System.out.println(list);
String[] array = new String[] { "First", "Second", "Third", "Fourth" };
System.out.println(array.toString());
System.out.println(Arrays.toString(array));
String[] arr1 = new String[] { "Fifth", "Sixth" };
String[] arr2 = new String[] { "Seventh", "Eigth" };
String[][] arrayOfArray = new String[][] { arr1, arr2 };
System.out.println(arrayOfArray);
System.out.println(Arrays.toString(arrayOfArray));
System.out.println(Arrays.deepToString(arrayOfArray));
}
}
输出:
[First, Second, Third, Fourth] [Ljava.lang.String;@12dacd1 [First, Second, Third, Fourth] [[Ljava.lang.String;@1ad086a [[Ljava.lang.String;@10385c1, [Ljava.lang.String;@42719c] [[Fifth, Sixth], [Seventh, Eigth]]
容器类初始化
忘设初始容量
在JAVA中,我们常用Collection中的Map做Cache,但是我们经常会遗忘设置初始容量:
cache = new LRULinkedHashMap< K, V>(maxCapacity);
解决
初始容量的影响有多大?拿LinkedHashMap来说,初始容量如果不设置默认是16,超过
16×LOAD_FACTOR,会resize(2 * table.length)扩大2倍。采用:
Entry[] newTable = new Entry[newCapacity]; transfer(newTable)
即整个数组Copy, 那么对于一个需要做大容量CACHE来说,从16变成一个很大的数量,需要
做多少次数组复制可想而知。如果初始容量就设置很大,自然会减少resize, 不过可能会
担心,初始容量设置很大时,没有Cache内容仍然会占用过大体积。其实可以参考以下表格
简单计算下, 初始时还没有cache内容, 每个对象仅仅是4字节引用而已。
- memory for reference fields (4 bytes each);
- memory for primitive fields
| Java类型 | 占用字节 |
| boolean | 1 |
| byte | |
| char | 2 |
| short | |
| int | 4 |
| float | |
| long | 8 |
| double |
不仅是map, 还有StringBuffer等,都有容量resize的过程,如果数据量很大,就不能
忽视初始容量可以考虑设置下,否则不仅有频繁的resize还容易浪费容量。
在Java编程中,除了上面枚举的一些容易忽视的问题,日常实践中还存在很多。相信通过 不断的总结和努力,可以将我们的程序完美呈现给读者。
枚举(enum)
不能用ordinal自增当值时,增加一个value表示值:
public enum CardType {
Gray(1), White(2), Black(3);
private int value;
private static final CardType[] valueArr = CardType.values();
private CardType(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public static CardType valueOf(int value) {
for (CardType e : valueArr)
if (e.value == value)
return e;
return null;
}
}
通过ordinal()、name()、getValue()取得对应的值:
assertTrue(0 == CardType.Gray.ordinal());
assertEquals("Gray", CardType.Gray.name());
assertTrue(1 == CardType.Gray.getValue());
assertTrue(1 == CardType.White.ordinal());
assertEquals("White", CardType.White.name());
assertTrue(2 == CardType.White.getValue());
assertTrue(2 == CardType.Black.ordinal());
assertEquals("Black", CardType.Black.name());
assertTrue(3 == CardType.Black.getValue());
根据ordinal、name、value生成枚举对象:
int ordinal = 2;
CardType type = CardType.values()[ordinal];
assertEquals(type, CardType.Black);
type = CardType.valueOf("Black");
assertEquals(type, CardType.Black);
type = CardType.valueOf(3);
assertEquals(type, CardType.Black);
Optional
三种构造方式:
-
Optional.empty() -
Optional.of(obj): 它要求传入的obj不能是null值的, 否则还没开始进入角色就倒在了NullPointerException异常上了. -
Optional.ofNullable(obj): 它以一种智能的, 宽容的方式来构造一个Optional实例
空值处理
return user.orElse(null); //而不是 return user.isPresent() ? user.get() : null;
return user.orElse(UNKNOWN_USER);
//而不是 return user.isPresent() ? user.get() : UNKNOWN_USER;
检查不为空
user.ifPresent(System.out::println);
//而不要下边那样
if (user.isPresent()) { System.out.println(user.get()); }
map映射
return user.map(u -> u.getOrders()).orElse(Collections.emptyList())
//上面避免了我们类似 Java 8 之前的做法
if(user.isPresent()) {
return user.get().getOrders();
} else {
return Collections.emptyList();
}
链式操作
map是可能无限级联的, 比如再深一层, 获得用户名的大写形式
return user.map(u -> u.getUsername())
.map(name -> name.toUpperCase())
.orElse(null);
这要搁在以前, 每一级调用的展开都需要放一个 null 值的判断
if(user != null) {
String name = user.getUsername();
if(name != null) {
return name.toUpperCase();
} else {
return null;
}
} else {
return null;
}
Java对象
对象初始化
在Java中,一个对象在可以被使用之前必须要被正确地初始化,这一点是Java规范规定的。 本文试图对Java如何执行对象的初始化做一个详细深入地介绍(与对象初始化相同,类在被 加载之后也是需要初始化的,本文在最后也会对类的初始化进行介绍,相对于对象初始化 来说,类的初始化要相对简单一些)。
显式初始化
Java对象在其被创建时初始化,在Java代码中,有两种行为可以引起对象的创建。其中比较
直观的一种,也就是通常所说的显式对象创建,就是通过new关键字来调用一个类的构造
函数,通过构造函数来创建一个对象,这种方式在java规范中被称为「由执行类实例创建
表达式而引起的对象创建」。
隐式初始化
当然,除了显式地创建对象,以下的几种行为也会引起对象的创建,但是并不是通过new
关键字来完成的,因此被称作隐式对象创建,他们分别是:
String字面量
加载一个包含String字面量的类或者接口会引起一个新的String对象被创建,除非包含
相同字面量的String对象已经存在与虚拟机内了(JVM会在内存中会为所有碰到String
字面量维护一份列表,程序中使用的相同字面量都会指向同一个String对象),比如:
class StringLiteral {
private String str = "literal";
private static String sstr = "s_literal";
}
自动装箱
自动装箱机制可能会引起一个原子类型的包装类对象被创建,比如:
class PrimitiveWrapper {
private Integer iWrapper = 1;
}
String连接操作符
String连接符也可能会引起新的String或者StringBuilder对象被创建,同时还可能
引起原子类型的包装对象被创建,比如(本人试了下,在mac ox下1.6.0_29版本的javac,
对待下面的代码会通过StringBuilder来完成字符串的连接,并没有将i包装成
Integer,因为StringBuilder的append方法有一个重载,其方法参数是int),
public class StringConcatenation {
private static int i = 1;
public static void main(String... args) {
System.out.println("literal" + i);
}
}
Java如何初始化对象
当一个对象被创建之后,虚拟机会为其分配内存,主要用来存放对象的实例变量及其从超类 继承过来的实例变量(即使这些从超类继承过来的实例变量有可能被隐藏也会被分配空间)。 在为这些实例变量分配内存的同时,这些实例变量也会被赋予默认值。
关于实例变量隐藏:
class Foo {
int i = 0;
}
class Bar extends Foo {
int i = 1;
public static void main(String... args) {
Foo foo = new Bar();
System.out.println(foo.i);
}
}
上面的代码中,Foo和Bar中都定义了变量i,在main方法中,我们用Foo引用一个
Bar对象,如果实例变量与方法一样,允许被覆盖,那么打印的结果应该是1,但是实际
的结果确是0。
但是如果我们在Bar的方法中直接使用i,那么用的会是Bar对象自己定义的实例变量
i,这就是隐藏,Bar对象中的i把Foo对象中的i给隐藏了,这条规则对于静态
变量同样适用。
在内存分配完成之后,java的虚拟机就会开始对新创建的对象执行初始化操作,因为java 规范要求在一个对象的引用可见之前需要对其进行初始化。在Java中,三种执行对象初始化 的结构,分别是实例初始化器、实例变量初始化器以及构造函数。
Java的构造函数
每一个Java中的对象都至少会有一个构造函数,如果我们没有显式定义构造函数,那么Java
编译器会为我们自动生成一个构造函数。构造函数与类中定义的其他方法基本一样,除了
构造函数没有返回值,名字与类名一样之外。在生成的字节码中,这些构造函数会被命名成
<init>方法,参数列表与Java语言书写的构造函数的参数列表相同(<init>这样的
方法名在Java语言中是非法的,但是对于JVM来说,是合法的)。另外,构造函数也可以被
重载。
Java要求一个对象被初始化之前,其超类也必须被初始化,这一点是在构造函数中保证的。
Java强制要求Object对象(Object是Java的顶层对象,没有超类)之外的所有对象构造
函数的第一条语句必须是超类构造函数的调用语句或者是类中定义的其他的构造函数,如果
我们即没有调用其他的构造函数,也没有显式调用超类的构造函数,那么编译器会为我们
自动生成一个对超类构造函数的调用指令,比如:
public class ConstructorExample {
}
对于上面代码中定义的类,如果观察编译之后的字节码,我们会发现编译器为我们生成一个 构造函数,如下:
aload_0 invokespecial #8; //Method java/lang/Object."<init>":()V return
上面代码的第二行就是调用Object对象的默认构造函数的指令。
正因为如此,如果我们显式调用超类的构造函数,那么调用指令必须放在构造函数所有代码 的最前面,是构造函数的第一条指令。这么做才可以保证一个对象在初始化之前其所有的 超类都被初始化完成。
如果我们在一个构造函数中调用另外一个构造函数,如下所示:
public class ConstructorExample {
private int i;
ConstructorExample() {
this(1);
....
}
ConstructorExample(int i) {
....
this.i = i;
....
}
}
对于这种情况,Java只允许在ConstructorExample(int i)内出现调用超类的构造函数,
也就是说,下面的代码编译是无法通过的,
public class ConstructorExample {
private int i;
ConstructorExample() {
super();
this(1);
....
}
ConstructorExample(int i) {
....
this.i = i;
....
}
}
或者:
public class ConstructorExample {
private int i;
ConstructorExample() {
this(1);
super();
....
}
ConstructorExample(int i) {
....
this.i = i;
....
}
}
Java对构造函数作出这种限制,目的是为了要保证一个类中的实例变量在被使用之前已经被 正确地初始化,不会导致程序执行过程中的错误。但是,与C或者C++不同,Java执行构造 函数的过程与执行其他方法并没有什么区别,因此,如果我们不小心,有可能会导致在对象 的构建过程中使用了没有被正确初始化的实例变量,如下所示:
class Foo {
int i;
Foo() {
i = 1;
int x = getValue();
System.out.println(x);
}
protected int getValue() {
return i;
}
}
class Bar extends Foo {
int j;
Bar() {
j = 2;
}
@Override
protected int getValue() {
return j;
}
}
public class ConstructorExample {
public static void main(String... args) {
Bar bar = new Bar();
}
}
如果运行上面这段代码,会发现打印出来的结果既不是1,也不是2,而是0。根本
原因就是Bar重载了Foo中的getValue方法。在执行Bar的构造函数时,编译器会为
我们在Bar构造函数开头插入调用Foo的构造函数的代码,而在Foo的构造函数中调用
了getValue方法。由于Java对构造函数的执行没有做特殊处理,因此这个getValue方法
是被Bar重载的那个getValue方法,而在调用Bar的getValue方法时,Bar的构造
数还没有被执行,这个时候j的值还是默认值0,因此我们就看到了打印出来的0。
实例变量初始化器与实例初始化器
我们可以在定义实例变量的同时,对实例变量进行赋值,赋值语句就时实例变量初始化器了 ,比如:
public class InstanceVariableInitializer {
private int i = 1;
private int j = i + 1;
}
如果我们以这种方式为实例变量赋值,那么在构造函数执行之前会先完成这些初始化操作。
我们还可以通过实例初始化器来执行对象的初始化操作,比如:
public class InstanceInitializer {
private int i = 1;
private int j;
{
j = 2;
}
}
上面代码中花括号内代码,在Java中就被称作实例初始化器,其中的代码同样会先于构造 函数被执行。
如果我们定义了实例变量初始化器与实例初始化器,那么编译器会将其中的代码放到类的 构造函数中去,这些代码会被放在对超类构造函数的调用语句之后(还记得吗?Java要求 构造函数的第一条语句必须是超类构造函数的调用语句),构造函数本身的代码之前。我们 来看下下面这段Java代码被编译之后的字节码,Java代码如下:
public class InstanceInitializer {
private int i = 1;
private int j;
{
j = 2;
}
public InstanceInitializer() {
i = 3;
j = 4;
}
}
编译之后的字节码如下:
aload_0 invokespecial #11; //Method java/lang/Object."<init>":()V aload_0 iconst_1 putfield #13; //Field i:I aload_0 iconst_2 putfield #15; //Field j:I aload_0 iconst_3 putfield #13; //Field i:I aload_0 iconst_4 putfield #15; //Field j:I return
上面的字节码,第4,5行是执行的是源代码中i=1的操作,第6,7行执行的源代码中j=2
的操作,第8-11行才是构造函数中i=3和j=4的操作。
Java是按照编程顺序来执行实例变量初始化器和实例初始化器中的代码的,并且不允许顺序 靠前的实例初始化器或者实例变量初始化器使用在其后被定义和初始化的实例变量,比如:
public class InstanceInitializer {
{
j = i;
}
private int i = 1;
private int j;
}
public class InstanceInitializer {
private int j = i;
private int i = 1;
}
上面的这些代码都是无法通过编译的,编译器会抱怨说我们使用了一个未经定义的变量。 之所以要这么做,是为了保证一个变量在被使用之前已经被正确地初始化。但是我们仍然 有办法绕过这种检查,比如:
public class InstanceInitializer {
private int j = getI();
private int i = 1;
public InstanceInitializer() {
i = 2;
}
private int getI() {
return i;
}
public static void main(String[] args) {
InstanceInitializer ii = new InstanceInitializer();
System.out.println(ii.j);
}
}
如果我们执行上面这段代码,那么会发现打印的结果是0。因此我们可以确信,变量j被
赋予了i的默认值0,而不是经过实例变量初始化器和构造函数初始化之后的值。
初始化过程中的多次赋值
一个实例变量在对象初始化的过程中会被赋值几次
在本文的前面部分,我们提到过,JVM在为一个对象分配完内存之后,会给每一个实例变量 赋予默认值,这个时候实例变量被第一次赋值,这个赋值过程是没有办法避免的。
如果我们在实例变量初始化器中对某个实例x变量做了初始化操作,那么这个时候,这个 实例变量就被第二次赋值了。
如果我们在实例初始化器中,又对变量x做了初始化操作,那么这个时候,这个实例变量
就被第三次赋值了。
如果我们在类的构造函数中,也对变量x做了初始化操作,那么这个时候,变量x就被
第四次赋值。
也就是说,一个实例变量,在Java的对象初始化过程中,最多可以被初始化4次。
总结
通过上面的介绍,我们对Java中初始化对象的几种方式以及通过何种方式执行初始化代码 有了了解,同时也对何种情况下我们可能会使用到未经初始化的变量进行了介绍。在对这些 问题有了详细的了解之后,就可以在编码中规避一些风险,保证一个对象在可见之前是完全 被初始化的。
类的初始化
Java规范中关于类在何时被初始化有详细的介绍,在3.0规范中的12.4.1节可以找到,这里 就不再多说了。简单来说,就是当类被第一次使用的时候会被初始化,而且只会被一个线程 初始化一次。我们可以通过静态初始化器和静态变量初始化器来完成对类变量的初始化工作 ,比如:
public class StaticInitializer {
static int i = 1;
static {
i = 2;
}
}
上面通过两种方式对类变量i进行了赋值操作,分别通过静态变量初始化器(代码第2行)以及 静态初始化器(代码第5-6行)完成。
静态变量初始化器和静态初始化器基本同实例变量初始化器和实例初始化器相同,也有相同
的限制(按照编码顺序被执行,不能引用后定义和初始化的类变量)。静态变量初始化器和
静态初始化器中的代码会被编译器放到一个名为static的方法中(static是Java语言的
关键字,因此不能被用作方法名,但是JVM却没有这个限制),在类被第一次使用时,这个
static方法就会被执行。上面的Java代码编译之后的字节码如下,我们看到其中的
static方法,
static {};
Code:
Stack=1, Locals=0, Args_size=0
iconst_1
putstatic #10; //Field i:I
iconst_2
putstatic #10; //Field i:I
return
在前面介绍了可以通过特殊的方式来使用未经初始化的实例变量,对于类变量也同样适用, 比如:
public class StaticInitializer {
static int j = getI();
static int i = 1;
static int getI () {
return i;
}
public static void main(String[] args) {
System.out.println(StaticInitializer.j);
}
}
上面这段代码的打印结果是0,类变量的值是i的默认值0。但是,由于静态方法是
不能被覆写的,因此「对象初始化」中关于构造函数调用被覆写方法引起的问题不会在此
出现。
内部类
有三种内部部类
Java语言规范中有三种内部:
- 成员类
- 本地类
- 匿名类
成员类
class Outer {
/* 成员类 */
class Inner {}
Inner i = new Inner();
}
匿名类
class Outer {
/* 匿名类 */
Object anonymous = new Object() {};
}
本地类
本地类:初始化块中
class Outer {
{
class Local {}
Local l = new Local();
}
}
本地类:构造函数中
class Outer {
Outer() {
class Local {}
Local l = new Local();
}
}
本地类:方法中
class Outer {
void method() {
class Local {}
Local l = new Local();
}
}
实现「细节」
Java语言规范和虚拟机规范并没有告诉我们内部类的实现细节。这里的一些文章阐明了 一些细节,比如Java编译器如何生成合成方法,可以使这些成员类访问(外部类的)私有 成员,这在JVM中本来是是不允许的。
很容易直到内部类的另一个实现细节:内部类的构造函数需要额外的合成参数。内部类
构造函数第一个合成参数就是普遍知道的内部类的外围实例(的引用),它存储在
this$0的合成域中。 这是适用于三种内部类:成员,本地和匿名。
但鲜为人知的是,局部内部类需要通过额外的合成构造参数来获取非常量变量,(获取 常量将被内联,并不会产生额外的合成构造函数参数):
class Outer {
void method() {
final String constant = "foo";
final String nonConstant = "foo".toUpperCase();
class Local {
/*
* synthetic fields and constructor:
*
* Outer this$0; String nonConstant;
*
* Local(Outer this$0, String nonConstant){ this.this$0 = this$0;
* this.nonConstant = nonConstant; }
*/
}
Local l = new Local();
}
}
好吧,但是我为什么要关心它?
在大多数情况下,你并不关心内部类的实现机制,除非好奇心使然。但是如果你在内部类 中使用了反射,这里有些东西你需要清楚,而且我并没有听过或者在网上看过这类资料, 所以我想很有必要列出清单帮助其他人弄清楚,因为通过Java反射的API,不同的编译器会 产生不同的结果。
现在的问题是,当你使用Java反射来获取对内部类构造一个
java.lang.reflect.Constructor中的实例会发生什么情况,尤其是使用那些允许你访问
以下三种类型:
-
参数类型(pre-generics:
getParameterTypes()) -
泛型参数类型(post-generics:
getGenericParameterTypes()) -
和注释(
getParameterAnnotations())
答案是:这取决于不同的编译器。
假设有一个类:
class Outer {
class Inner {
Inner() {}
Inner(String param) {}
Inner(@Deprecated Integer param) {}
}
}
下面是这三个通过反射调用构造函数得到的数组的长度,它们会因为java编译器的不同而 不同。
| Outer.Inner.class. getDeclaredConstructor() | Outer.Inner.class. getDeclaredConstructor (String.class) | Outer.Inner.class. getDeclaredConstructor (Integer.class) | |
|---|---|---|---|
| getParameterTypes().length | 1 | 2 | 2 |
| getParameterAnnotations().length | 1 | 2 | 1 |
| getGenericParameterTypes().length compiled with Javac | 0 | 1 | 1 |
| getGenericParameterTypes().length compiled with Eclipse | 1 | 2 | 2 |
可以看到:
-
getParameterTypes()中始终包含「合成」参数 -
getGenericParameterTypes()中,只有用Eclipse编译时才包含「合成」参数 -
getParameterAnnotations(),除非你的构造函数的参数使用了注释,否则也一直包含了「合成」参数。
通过这些信息,你可以了解到这三个方法产生的不同结果,但是到目前为止我还是没有
办法确定一个参数是否是「合成」的,因为虽然你可以对每个内部类都需要的this$X
合成参数做一个很好的猜测,你没办法知道最终成为局部内部类的「合成」参数的数目。
日期与时间
时区
设定本地时区,注意本地时间会有混乱。因为历史上的历法变化。如1927年上海时间到 北京时间切换,中间空出来5分钟:
import java.text.SimpleDateFormat;
import java.text.ParseException;
import java.util.Date;
import java.util.TimeZone;
class time{
public static void main(String[] args) throws ParseException {
SimpleDateFormat sf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
sf.setTimeZone(TimeZone.getTimeZone("Asia/shanghai"));
String str3 = "1927-12-31 23:54:07";
String str4 = "1927-12-31 23:54:08";
Date sDt3 = sf.parse(str3);
Date sDt4 = sf.parse(str4);
long ld3 = sDt3.getTime() /1000;
long ld4 = sDt4.getTime() /1000;
System.out.println(ld3);
System.out.println(ld4);
System.out.println(ld4-ld3);
}
}
输出一秒钟本地时间之间差了353秒:
-1325491905 -1325491552 353
Java在的时区实现相当的强大啊。这种细节都能考虑到。本地时间的完全就是一锅,应该 尽量不用。如果你要开发和时区有关系的程序,你的系统里一定要使用GMT标准时间,仅在 显示的时候才转成本地时间。
旧日期工具:java.util
最开始的时候,Date既要承载日期信息,又要做日期之间的转换,还要做不同日期格式的显示,职责较繁杂(不懂单一职责,你妈妈知道吗?纯属恶搞~哈哈)
后来从JDK 1.1 开始,这三项职责分开了:
- 使用Calendar类实现日期和时间字段之间转换;
- 使用DateFormat类来格式化和分析日期字符串;
- 而Date只用来承载日期和时间信息。
原有Date中的相应方法已废弃。不过,无论是Date,还是Calendar,都用着太不方便了,这是API没有设计好的地方。
年月表示不直观
坑爹的year和month
Date date = new Date(2012,1,1); System.out.println(date); 输出Thu Feb 01 00:00:00 CST 3912
观察输出结果,year是2012+1900,而month,月份参数我不是给了1吗?怎么输出二月(Feb)了?
应该曾有人告诉你,如果你要设置日期,应该使用 java.util.Calendar,像这样...
Calendar calendar = Calendar.getInstance(); calendar.set(2013, 8, 2);
这样写又不对了,calendar的month也是从0开始的,表达8月份应该用7这个数字,要么就干脆用枚举
calendar.set(2013, Calendar.AUGUST, 2);
注意上面的代码,Calendar年份的传值不需要减去1900(当然月份的定义和Date还是一样),这种不一致真是让人抓狂!
有些人可能知道,Calendar相关的API是IBM捐出去的,所以才导致不一致。
java.util.Date与java.util.Calendar中的所有属性都是可变的
下面的代码,计算两个日期之间的天数....
public static void main(String[] args) {
Calendar birth = Calendar.getInstance();
birth.set(1975, Calendar.MAY, 26);
Calendar now = Calendar.getInstance();
System.out.println(daysBetween(birth, now));
System.out.println(daysBetween(birth, now)); // 显示 0?
}
public static long daysBetween(Calendar begin, Calendar end) {
long daysBetween = 0;
while(begin.before(end)) {
begin.add(Calendar.DAY_OF_MONTH, 1);
daysBetween++;
}
return daysBetween;
}
daysBetween有点问题,如果连续计算两个Date实例的话,第二次会取得0,因为Calendar状态是可变的,考虑到重复计算的场合,最好复制一个新的Calendar
public static long daysBetween(Calendar begin, Calendar end) {
Calendar calendar = (Calendar) begin.clone(); // 复制
long daysBetween = 0;
while(calendar.before(end)) {
calendar.add(Calendar.DAY_OF_MONTH, 1);
daysBetween++;
}
return daysBetween;
}
Java8新日期类型java.time
以上种种,导致目前有些第三方的java日期库诞生,比如广泛使用的JODA-TIME,还有Date4j等,虽然第三方库已经足够强大,好用,但还是有兼容问题的,比如标准的JSF日期转换器与joda-time API就不兼容,你需要编写自己的转换器,所以标准的API还是必须的,于是就有了JSR310。
JSR 310实际上有两个日期概念。第一个是Instant,它大致对应于java.util.Date类,因为它代表了一个确定的时间点,即相对于标准Java纪元(1970年1月1日)的偏移量;但与java.util.Date类不同的是其精确到了纳秒级别。
第二个对应于人类自身的观念,比如LocalDate和LocalTime。他们代表了一般的时区概念,要么是日期(不包含时间),要么是时间(不包含日期),类似于java.sql的表示方式。此外,还有一个MonthDay,它可以存储某人的生日(不包含年份)。每个类都在内部存储正确的数据而不是像java.util.Date那样利用午夜12点来区分日期,利用1970-01-01来表示时间。
新标准有三个核心思路:
- 不可改变值的类。一个严重的问题是,对于Java中已经存在的格式化处理类(Formatter)不是线程安全的。这使开发人员在日常开发中需要编写线程安全的日期处理代码变得很麻烦。新的API保证所有的核心类中的值是不可变的,避免了并发情况下带来的不必要的问题。
- 领域驱动设计。新的API模型可以精确的表示出Date和Time的差异性。在以前的Java库中这一点就表现的非常差。比如,java.util.Date他表示一个时间点,从Unix时代开始就是以毫秒数的形式保存,但是你调用它的toString方法时,结果却显示它是有时区概念的,这就容易让开发者产生歧义。领域驱动设计的重点是从长远好处出发且简单易懂, 当你需要把你以前的处理时间的模块代码移植到Java8上时你就需要考虑一下领域模型的设计了。
- 区域化时间体系。新的API允许人们在时区不同的时间体系下使用。比如日本或者泰国,他们不必要遵循 ISO-8601。新API为大多数开发者减少了很多额外的负担,我们只需要使用标准的时间日期API。
目前Java8已经实现了JSR310的全部内容。新增了java.time包定义的类表示了日期-时间概念的规则,
包括instants, durations, dates, times, time-zones and periods。这些都是基于ISO日历系统,
它又是遵循 Gregorian规则的。最重要的一点是值不可变,且线程安全,通过下面一张图,
我们快速看下java.time包下的一些主要的类的值的格式,方便理解:
-
java.time.format.DateTimeFormatter:时间格式化工具 -
Instant:时间戳,比如:2576458258.266 sends after 1970-01-01 -
LocalDateTime:包含日期和时间,比如:2010-12-03T11:05:30 -
LocalDate:时间的日期部分,比如:2010-12-03 -
LocalTime:时间在一天内的时间部分,比如:11:05:30 -
Year:,比如:2010 -
YearMonth:,比如:2010-12 -
MonthDay:,比如:-12-03 -
ZoneOffset:时间偏移量,比如:+8:00 -
Clock:时钟,比如获取美国的纽约时间,比如: -
OffsetTime:,比如:11:05:30+01:00 -
OffsetDateTime:,比如:2010-12-03T11:05:30+01:00 -
ZonedDateTime:带时区的时间,比如:2010-12-03T11:05:30+01:00 Europe/Paris -
Duration:持续时间段 -
Period:时间段
Date and Time:简单的日期和时间 “容器”
| Type | Y | M | D | H | m | S(n) | Z | Zld | toString |
|---|---|---|---|---|---|---|---|---|---|
Instant
|
X |
1999-01-12T12:00:00.747Z
|
|||||||
LocalDate
|
X | X | X |
2010-12-03
|
|||||
LocalTime
|
X | X | X |
11:05:30
|
|||||
LocalDateTime
|
X | X | X | X | X | X |
2010-12-03T11:05:30
|
||
ZonedDateTime
|
X | X | X | X | X | X | X | X |
2010-12-03T11:05:30+01:00 Europe/Paris
|
OffsetTime
|
X | X | X | X |
11:05:30+01:00
|
||||
OffsetDateTime
|
X | X | X | X | X | X | X |
2010-12-03T11:05:30+01:00
|
|
ZoneOffset
|
+8:00
|
||||||||
Clock:
|
Ranges:时间跨度
| Type | Y | M | D | H | m | S(n) | Z | Zld | toString |
|---|---|---|---|---|---|---|---|---|---|
Duration
|
X | P22H | |||||||
Period
|
X | X | X | P15D |
Partials:范围
| Type | Y | M | D | H | m | S(n) | Z | Zld | toString |
|---|---|---|---|---|---|---|---|---|---|
Month
|
* |
JANUARY
|
|||||||
MonthDay
|
X | X |
-12-03
|
||||||
Year
|
X |
2010
|
|||||||
YearMonth
|
X | X |
2010-12
|
||||||
DayOfWeek
|
* |
SUNDAY
|
Chronology: 组织和识别日期的日历系统
-
Chronology: 是创建或获取预建日历系统的工厂默认为 IsoChronology (例如:ThaiBuddhistChronology)。 -
ChronoLocalDate: 在任意年表中存储没有时间的日期。 -
ChronoLocalDateTime: 以任意年表存储日期和时间。 -
ChronoZonedDateTime: 以任意年表形式存储日期、时间和时区。 -
ChronoPeriod: 模拟天/时间跨度以用于任意年表。 -
Era: 存储时间线 [通常两个 Chronology,但有时会更多]。
该包的API提供了大量相关的方法,这些方法一般有一致的方法前缀:
-
of:静态工厂方法。 -
parse:静态工厂方法,关注于解析。 -
get:获取某些东西的值。 -
is:检查某些东西的是否是true。 -
with:不可变的setter等价物。 -
plus:加一些量到某个对象。 -
minus:从某个对象减去一些量。 -
to:转换到另一个类型。 -
at:把这个对象与另一个对象组合起来,例如: date.atTime(time)。
日期
java.time.LocalDate
import java.time.LocalDate; import java.time.temporal.ChronoUnit; LocalDate today = LocalDate.now(); // 取得当天日期(仅日期部分) LocalDate.of(2012, Month.DECEMBER, 12); // from values LocalDate.ofEpochDay(150); // middle of 1970 int year = today.getYear(); // 年 int month = today.getMonthValue(); // 月 int day = today.getDayOfMonth(); // 日 bool isLeapYear = today.isLeapYear(); // 是否是闰年 LocalDate date = LocalDate.of(2018, 2, 6); // 指定日期 date.equals(LocalDate.now); // 日期是否相等 LocalDate prvYea r = today.minus(1, ChronoUnit.YEARS); // 一年前 LocalDate nextYear = today.plus( 1, ChronoUnit.YEARS); // 一年后 LocalDate nextWeek = today.plus( 1, ChronoUnit.WEEKS); // 一周后 // 判断日期是早于还是晚于 LocalDate.of(2018, 2, 6).isAfter( LocalDate.of(2018, 2, 9)) // false LocalDate.of(2018, 2, 6).isBefore(LocalDate.of(2018, 2, 9)) // true
java.time.YearMonth
YearMonth忽略日,只含年月:
- 用于表示信用卡到期日、FD到期日、期货期权到期日等。
-
用于判断月共有多少天,
YearMonth实例的lengthOfMonth()方法可以 返回当月的天数,在判断2月有28天还是29天时非常有用。
import java.time.YearMonth; import java.time.Month; YearMonth currentYearMonth = YearMonth.now(); int dayCount = currentYearMonth.lengthOfMonth(); // 当月有几天 YearMonth cardExpiry = YearMonth.of(2019, Month.FEBRUARY); // 信用卡过期日期
java.time.MonthDay
MonthDay忽略年,只含月与日:
import java.time.LocalDate;
import java.time.MonthDay;
// 工厂方法:of(month, day)
MonthDay birthday = MonthDay.of(2, 6);
// 工厂方法:from(LocalDate)
currentMonthDay = MonthDay.from(LocalDate.now());
if (currentMonthDay.equals(birthday)) {
System.out.println("是你的生日");
} else {
System.out.println("你的生日还没有到");
}
一天中的时间
java.time.LocalTime
LocalTime time = LocalTime.now();
// 从时间中抽取
LocalTime truncatedTime = time.truncatedTo(ChronoUnit.SECONDS);
// Set the value, returning a new object
LocalDateTime thePast = timePoint.withDayOfMonth(10).withYear(2010);
/* You can use direct manipulation methods, or pass a value and field pair */
LocalDateTime yetAnother = thePast.plusWeeks(3).plus(3, ChronoUnit.WEEKS);
LocalTime.of(17, 18); // the train I took home today
LocalTime.parse("10:15:30"); // From a String
LocalTime newTime = time.plusHours(3); // 加上三小时
日期时间转换:
LocalDate theDate = timePoint.toLocalDate(); Month month = timePoint.getMonth(); int day = timePoint.getDayOfMonth(); timePoint.getSecond();
新的API提供的一个调节器的概念–用来封装通用的处理逻辑的一段代码。 你对任意时间使用WithAdjuster来设置一个或者多个字段, 或者可以使用PlusAdjuster来对字段进行增量或者减法操作. 值类型也可以被当做调节器使用,用来更新字段的值. 新的API定义了一些内置的调节器, 但是如果你希望实现某些特定的业务逻辑,你也可以自己实现一个调节器.
import static java.time.temporal.TemporalAdjusters.*; LocalDateTime timePoint = ... foo = timePoint.with(lastDayOfMonth()); bar = timePoint.with(previousOrSame(ChronoUnit.WEDNESDAY)); // Using value classes as adjusters timePoint.with(LocalTime.now());
日期时间
java.time.Instant
Instant类有一个静态工厂方法now()会返回当前的时间戳,
时间戳信息里同时包含了日期和时间,这和java.util.Date很像。
实际上Instant类确实等同于 Java 8之前的Date类。如下所示:
import java.time.Instant;
Instant timestamp = Instant.now();
可以使用Date类和Instant类各自的转换方法互相转换,例如:
Date.from(Instant)将Instant转换成java.util.Date,
Date.toInstant()则是将Date类转换成Instant类。
java.time.Clock
Clock时钟类用于获取当时的时间戳,或当前时区下的日期时间信息。
以前用到System.currentTimeInMillis()和TimeZone.getDefault()的地方都可用
Clock替换。
import java.time.Clock; Clock clock = Clock.systemUTC(); // 当前系统的UTC时间 Clock defaultClock = Clock.systemDefaultZone(); // 当前系统的时区时间
时区
Java 8以前GregorianCalendar类处理的时区现在由单独的时区类来处理。
如ZoneId指定时区,ZoneDateTime表示时区下的时间:
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.ZonedDateTime;
LocalDateTime localtDateAndTime = LocalDateTime.now(); // 当前时间戳
ZoneId america = ZoneId.of("America/New_York"); // 美国时区
ZonedDateTime dateTimeInNY = ZonedDateTime.of(localtDateAndTime, america );
ZoneId.from(dateTimeInNY) // 从时间中取出时区
assertEquals(america, ZoneId.from(dateTimeInNY));
ZonedDateTime.parse("2007-12-03T10:15:30+01:00[Europe/Paris]");
时区差
ZoneOffset 是一段时间内代表格林尼治时间/世界同一时间与时区之间的差异。 他能表示一个特殊的差异时区偏移量。
ZoneOffset offset = ZoneOffset.of("+2:00");
时区偏移类的日期时间
- OffsetDateTime 是一个带有偏移量的时间日期类。如果你的服务器处在不同的时区,他可以存入数据库中也可以用来记录某个准确的时间点。
- OffsetTime 是一个带有偏移量的时间类。
OffsetTime time = OffsetTime.now(); // changes offset, while keeping the same point on the timeline OffsetTime sameTimeDifferentOffset = time.withOffsetSameInstant(offset); // changes the offset, and updates the point on the timeline OffsetTime changeTimeWithNewOffset = time.withOffsetSameLocal(offset); // Can also create new object with altered fields as before changeTimeWithNewOffset.withHour(3).plusSeconds(2);
日期时间和格式化与解析
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
// 字符串转日期
LocalDate formatted = LocalDate.parse("20180205", DateTimeFormatter.BASIC_ISO_DATE);
LocalDateTime date = LocalDateTime.now();
DateTimeFormatter format = DateTimeFormatter.ofPattern("yyyy/MM/dd HH:mm:ss");
String str = date.format(format); //日期转字符串
LocalDate date2 = LocalDate.parse(str,format); //字符串转日期
时间段
java.time.Period
计算日间之间的天数:
import java.time.LocalDate; import java.time.Period; // 日期区间 Period period = Period.between(LocalDate.now(), LocalDate.of(2018, 12, 14)); // 「三年两个月零一天」 Period period = Period.of(3, 2, 1); int years = period.getYears(); // 间隔多少和年 int months = period.getMonths(); // 间隔多少和月 int days = period.getDays(); // 间隔多少和日 // You can modify the values of dates using periods LocalDate newDate = oldDate.plus(period); ZonedDateTime newDateTime = oldDateTime.minus(period); // Components of a Period are represented by ChronoUnit values assertEquals(1, period.get(ChronoUnit.DAYS));
java.time.Duration
Duration类也是用来描述一段时间的, 他和Period类似,但是不同于Period的是,它表示的精度更细。
// A duration of 3 seconds and 5 nanoseconds Duration duration = Duration.ofSeconds(3, 5); Duration oneDay = Duration.between(today, yesterday);
Chronology系列类
由于我们需要支持无ISO日期年表表示的环境, Java SE 8 首次引入了Chronology类, 在这种环境下使用。 他们也实现了核心的时间日期接口。
Chronology:
- ChronoLocalDate
- ChronoLocalDateTime
- ChronoZonedDateTime
这些类应该使用在具有高度国际化的应用中需要使用本地化的时间体系时, 没有这种需求的话最好不要使用它们。有一些时间体系中甚至没有一个月, 一个星期这样的概念,我们只能通过更加通用抽象的字段进行运算。
其他例子
public class TimeIntroduction {
public static void testClock() throws InterruptedException {
//时钟提供给我们用于访问某个特定 时区的 瞬时时间、日期 和 时间的。
Clock c1 = Clock.systemUTC(); //系统默认UTC时钟(当前瞬时时间 System.currentTimeMillis())
System.out.println(c1.millis()); //每次调用将返回当前瞬时时间(UTC)
Clock c2 = Clock.systemDefaultZone(); //系统默认时区时钟(当前瞬时时间)
Clock c31 = Clock.system(ZoneId.of("Europe/Paris")); //巴黎时区
System.out.println(c31.millis()); //每次调用将返回当前瞬时时间(UTC)
Clock c32 = Clock.system(ZoneId.of("Asia/Shanghai"));//上海时区
System.out.println(c32.millis());//每次调用将返回当前瞬时时间(UTC)
Clock c4 = Clock.fixed(Instant.now(), ZoneId.of("Asia/Shanghai"));//固定上海时区时钟
System.out.println(c4.millis());
Thread.sleep(1000);
System.out.println(c4.millis()); //不变 即时钟时钟在那一个点不动
Clock c5 = Clock.offset(c1, Duration.ofSeconds(2)); //相对于系统默认时钟两秒的时钟
System.out.println(c1.millis());
System.out.println(c5.millis());
}
public static void testInstant() {
//瞬时时间 相当于以前的System.currentTimeMillis()
Instant instant1 = Instant.now();
System.out.println(instant1.getEpochSecond());//精确到秒 得到相对于1970-01-01 00:00:00 UTC的一个时间
System.out.println(instant1.toEpochMilli()); //精确到毫秒
Clock clock1 = Clock.systemUTC(); //获取系统UTC默认时钟
Instant instant2 = Instant.now(clock1);//得到时钟的瞬时时间
System.out.println(instant2.toEpochMilli());
Clock clock2 = Clock.fixed(instant1, ZoneId.systemDefault()); //固定瞬时时间时钟
Instant instant3 = Instant.now(clock2);//得到时钟的瞬时时间
System.out.println(instant3.toEpochMilli());//equals instant1
}
public static void testLocalDateTime() {
//使用默认时区时钟瞬时时间创建 Clock.systemDefaultZone() -->即相对于 ZoneId.systemDefault()默认时区
LocalDateTime now = LocalDateTime.now();
System.out.println(now);
//自定义时区
LocalDateTime now2 = LocalDateTime.now(ZoneId.of("Europe/Paris"));
System.out.println(now2);//会以相应的时区显示日期
//自定义时钟
Clock clock = Clock.system(ZoneId.of("Asia/Dhaka"));
LocalDateTime now3 = LocalDateTime.now(clock);
System.out.println(now3);//会以相应的时区显示日期
//不需要写什么相对时间 如java.util.Date 年是相对于1900 月是从0开始
//2013-12-31 23:59
LocalDateTime d1 = LocalDateTime.of(2013, 12, 31, 23, 59);
//年月日 时分秒 纳秒
LocalDateTime d2 = LocalDateTime.of(2013, 12, 31, 23, 59, 59, 11);
//使用瞬时时间 + 时区
Instant instant = Instant.now();
LocalDateTime d3 = LocalDateTime.ofInstant(Instant.now(), ZoneId.systemDefault());
System.out.println(d3);
//解析String--->LocalDateTime
LocalDateTime d4 = LocalDateTime.parse("2013-12-31T23:59");
System.out.println(d4);
LocalDateTime d5 = LocalDateTime.parse("2013-12-31T23:59:59.999");//999毫秒 等价于999000000纳秒
System.out.println(d5);
//使用DateTimeFormatter API 解析 和 格式化
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy/MM/dd HH:mm:ss");
LocalDateTime d6 = LocalDateTime.parse("2013/12/31 23:59:59", formatter);
System.out.println(formatter.format(d6));
//时间获取
System.out.println(d6.getYear());
System.out.println(d6.getMonth());
System.out.println(d6.getDayOfYear());
System.out.println(d6.getDayOfMonth());
System.out.println(d6.getDayOfWeek());
System.out.println(d6.getHour());
System.out.println(d6.getMinute());
System.out.println(d6.getSecond());
System.out.println(d6.getNano());
//时间增减
LocalDateTime d7 = d6.minusDays(1);
LocalDateTime d8 = d7.plus(1, IsoFields.QUARTER_YEARS);
//LocalDate 即年月日 无时分秒
//LocalTime即时分秒 无年月日
//API和LocalDateTime类似就不演示了
}
public static void testZonedDateTime() {
//即带有时区的date-time 存储纳秒、时区和时差(避免与本地date-time歧义)。
//API和LocalDateTime类似,只是多了时差(如2013-12-20T10:35:50.711+08:00[Asia/Shanghai])
ZonedDateTime now = ZonedDateTime.now();
System.out.println(now);
ZonedDateTime now2 = ZonedDateTime.now(ZoneId.of("Europe/Paris"));
System.out.println(now2);
//其他的用法也是类似的 就不介绍了
ZonedDateTime z1 = ZonedDateTime.parse("2013-12-31T23:59:59Z[Europe/Paris]");
System.out.println(z1);
}
public static void testDuration() {
//表示两个瞬时时间的时间段
Duration d1 = Duration.between(Instant.ofEpochMilli(System.currentTimeMillis() - 12323123), Instant.now());
//得到相应的时差
System.out.println(d1.toDays());
System.out.println(d1.toHours());
System.out.println(d1.toMinutes());
System.out.println(d1.toMillis());
System.out.println(d1.toNanos());
//1天时差 类似的还有如ofHours()
Duration d2 = Duration.ofDays(1);
System.out.println(d2.toDays());
}
public static void testChronology() {
//提供对java.util.Calendar的替换,提供对年历系统的支持
Chronology c = HijrahChronology.INSTANCE;
ChronoLocalDateTime d = c.localDateTime(LocalDateTime.now());
System.out.println(d);
}
/**
* 新旧日期转换
*/
public static void testNewOldDateConversion(){
Instant instant=new Date().toInstant();
Date date=Date.from(instant);
System.out.println(instant);
System.out.println(date);
}
public static void main(String[] args) throws InterruptedException {
testClock();
testInstant();
testLocalDateTime();
testZonedDateTime();
testDuration();
testChronology();
testNewOldDateConversion();
}
}
与Joda-Time的区别
其实JSR310的规范领导者Stephen Colebourne,同时也是Joda-Time的创建者,JSR310是在Joda-Time的基础上建立的,参考了绝大部分的API,但并不是说JSR310=JODA-Time,下面几个比较明显的区别是
- 最明显的变化就是包名(从org.joda.time以及java.time)
- JSR310不接受NULL值,Joda-Time视NULL值为0
- JSR310的计算机相关的时间(Instant)和与人类相关的时间(DateTime)之间的差别变得更明显
- JSR310所有抛出的异常都是DateTimeException的子类。虽然DateTimeException是一个RuntimeException
总结
对比旧的日期API
| Java.time | java.util.Calendar以及Date |
|---|---|
| 流畅的API | 不流畅的API |
| 实例不可变 | 实例可变 |
| 线程安全 | 非线程安全 |
日期与时间处理API,在各种语言中,可能都只是个不起眼的API, 如果你没有较复杂的时间处理需求,可能只是利用日期与时间处理API取得系统时间, 简单做些显示罢了,然而如果认真看待日期与时间,其复杂程度可能会远超过你的想象, 天文、地理、历史、政治、文化等因素,都会影响到你对时间的处理。所以在处理时间上, 最好选用JSR310(如果你用java8的话就实现310了),或者Joda-Time。
不止是java面临时间处理的尴尬,其他语言同样也遇到过类似的问题,比如
- Arrow:Python 中更好的日期与时间处理库
- Moment.js:JavaScript 中的日期库
- Noda-Time:.NET 阵营的 Joda-Time 的复制
Java IO
文件流与字符流
-
字节流:以
*InputStream或*OutputStream结尾。 -
字符流:以
*Reader或*Writer结局。


字符流
InputStreamReader可以把字节流,以指定的编码转换为字符流。 OutputStreamWriter可以把字符流以指定的编码转换为字节流。
这两个类采用了适配器设计模式, InputStreamReader把字节流转换为字符流, OutputStreamWriter把字符流转换为字节流。
当文本文件的编码格式与当前环境的编码格式不兼容时, 使用转换流类读写文件
// 程序开发环境使用UTF-8编码, 而现在是以GBK的格式把数据保存到文件中
OutputStream out = new FileOutputStream("d:/def.txt"); //以覆盖的方式打开文件
OutputStreamWriter osw = new OutputStreamWriter(out, "GBK");
osw.close();
InputStream in = new FileInputStream("d:/test01.java");
//使用转换流, 把字节流in中的字节,按照指定的编码GBK转换为字符
InputStreamReader isr = new InputStreamReader(in, "GBK");
int cc = isr.read(); //可以读取字符流isr中的字符
while( cc != -1) {
System.out.print((char)cc);
cc = isr.read();
}
isr.close();
文件流
文件字节流
读写文件内容, 是以字节为单位:
FileInputStream fis = new FileInputStream("d:/abc.txt");
//read()方法从文件中读取一个字节 ,并把读到 的字节返回, 如果读到文件末尾返回-1
int cc = fis.read();
while( cc != -1 ) {
System.out.print((char) cc);
// 当前文件中都是英文字符,一个字符对应一个字节, 把读到的字节转换为字符再打印
cc = fis.read(); // 继续读取文件中的内容
}
fis.close();
FileInputStream fis = new FileInputStream("d:/abc.txt");
byte[] bytes = new byte[8];
//读取数据保存到字节数组中, 返回读到的字节数,如果读到文件末尾返回-1
int len = fis.read(bytes);
while( len != -1 ){
//从流中读取了len个字节保存到了字节数组中, 可以对这len个字节 进行处理
//把读到的len个字节转换为字符串打印到屏幕上
System.out.print( new String(bytes, 0, len) );
//继续向下读, 读的字节继续保存到字节中
len = fis.read(bytes);
}
fis.close();
try ( FileInputStream fis = new FileInputStream("d:/abc.txt");) {
byte [] bytes = new byte[8]; //字符数组一般情况下是1024的偶数倍
int len = fis.read(bytes);
while( len != -1){
System.out.print( new String(bytes, 0 ,len));
len = fis.read(bytes);
}
} catch (Exception e) {
}
FileInputStream fis = null;
try {
fis = new FileInputStream("d:/abc.txt");
int cc = fis.read();
while( cc != -1 ){
System.out.print( (char)cc );
cc = fis.read();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if ( fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//1)建立当前程序与文件之间的流通道, 如果文件不存在,会创建一个新的文件,如果文件已存在,会覆盖原来的内容
//FileOutputStream fos = new FileOutputStream("d:/def.txt");
//1)建立当前程序与文件之间的流通道, 如果文件不存在,会创建一个新的文件,如果文件已存在,原文件后面追加新的内容
FileOutputStream fos = new FileOutputStream("d:/def.txt", true); //以追加的方式打开文件
//2)把数据保存到文件中
//2.1 可以一次保存一个字节
fos.write(97);
fos.write(98);
fos.write(99);
//2.2 可以一次保存一个字节数组
byte[]bytes = "wkcto is a NB Website".getBytes();
fos.write(bytes);
//2.3 换行 , 在Windows操作系统中,换行需要 两个 字符
fos.write('\n');
fos.write('\r');
//2.4 保存字节数组中部分字节
fos.write(bytes, 0, 5);
//3)关闭流通道
fos.close();
//以字节数组为单位复制, 异常处理, 自动关闭流
try (
FileInputStream fis = new FileInputStream(srcFile);
FileOutputStream fos = new FileOutputStream(destFile);
) {
byte [] bytes = new byte[1024];
int len = fis.read(bytes);
while( len != -1 ){
//把读到的len个字节保存到fos输出流中
fos.write(bytes, 0, len);
len = fis.read(bytes);
}
} catch (Exception e) {
}
////以字节为单位复制, 异常处理, 手动关闭流
//文件复制,从源文件中读取一个字节, 把该字节保存到目标文件中
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream(srcFile);
fos = new FileOutputStream(destFile);
int cc = fis.read(); //从源文件中读取一个字节
while( cc != -1 ){
//把读到的字节cc保存到目标文件中
fos.write(cc);
//继续读到源文件的下个字节
cc = fis.read();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if ( fis != null ) {
try {
fis.close();
// fos.close(); //不能放在一起
} catch (IOException e) {
e.printStackTrace();
}
}
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
文件字符流
字符流是以字符为单位处理流中的数据, 也可以说是以字符为单位读写文件的内容。 FileReader/FileWriter字符流只能读写纯文本文件, 并且要求文本文件的编码与当前环境的编码要兼容。
FileReader fReader = new FileReader("d:/log.txt");
char [] contents = new char[8];
//从文件中读取字符保存到字符数组中, 返回读到的字符个数, 如果读到文件末尾返回-1
int len = fReader.read(contents);
while( len != -1 ){
//把读到的len个字符转换为字符串打印到屏幕上
System.out.print( new String(contents, 0 ,len ));
len = fReader.read(contents);
}
fReader.close();
FileReader fr = new FileReader("d:/abc.txt");
//read()读取一个字符, 返回该字符的码值, 读到文件末尾返回-1
int cc = fr.read();
while( cc != -1 ){
System.out.print( (char)cc );
cc = fr.read();
}
fr.close();
}
//以覆盖的方式打开 文件,如果原来的文件格式是GBK,写入后文件的格式变为UTF-8
// FileWriter fw = new FileWriter("d:/def.txt");
//以追加的方式打开 文件,如果原来的文件格式是GBK,写入后文件会出现乱码
FileWriter fw = new FileWriter("d:/def.txt", true);
//一次写一个字符
fw.write('A');
fw.write('中');
//一次写一个字符数组
char [] contents = "wkcto是一个NB的网站".toCharArray();
fw.write(contents);
fw.write("还可以一次写一个字符串");
fw.write("\n"); //换行
fw.close();
//一次复制一个字符数组, 异常处理, 自动关闭流
try (
FileReader fr = new FileReader(srcfile);
FileWriter fw = new FileWriter(destfile);
){
char [] contents = new char[1024];
int len = fr.read(contents);
while( len != -1 ){
fw.write(contents, 0, len);
len = fr.read(contents);
}
} catch (Exception e) {
}
//逐个字符复制, 异常处理, 手动关闭流
FileReader fr = null;
FileWriter fw = null;
try {
fr = new FileReader(srcfile);
fw = new FileWriter(destfile);
int cc = fr.read();
while( cc != -1 ){
//把读到的字符cc保存到fw输出流中
fw.write(cc);
//继续读下个字符
cc = fr.read();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if ( fr != null ) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fw != null) {
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
缓冲流
字节缓冲流

默认有8192字节的缓冲区
//使用字节缓冲流保存数据到文件
//在当前程序与指定的文件间建立字节流通道
OutputStream out = new FileOutputStream("d:/def.txt");
//使用字节缓冲流对out字节流进行包装(缓冲)
BufferedOutputStream bos = new BufferedOutputStream(out);
//使用缓冲流保存数据, 现在是把数据保存到缓冲流的缓冲区中
bos.write(97);
byte[] bytes = "wkcto is a good websit".getBytes();
bos.write(bytes);
// bos.flush(); //把缓冲区的数据清空到文件里
bos.close();
//使用字节缓冲流读取文件内容
//在当前程序与指定的文件之间建立字节 流通道
InputStream in = new FileInputStream("d:/abc.txt");
//对字节流进行缓冲
BufferedInputStream bis = new BufferedInputStream(in);
//使用缓冲字节流读取文件内容
int cc = bis.read();
while( cc != -1){
System.out.print( (char)cc );
cc = bis.read();
}
bis.close(); //关闭缓冲流, 也会把被包装的字节流关闭
字符缓冲流
默认有8192字符大小的缓冲区
//2) 使用缓冲字符流保存数据到文件中
FileWriter fw = new FileWriter("d:/def.txt");
BufferedWriter bw = new BufferedWriter(fw);
//把数组保存到缓冲流的缓冲区中
bw.write("hello");
bw.newLine();
bw.write("wkcto");
//从键盘上输入数据保存到文件中
// Scanner sc = new Scanner(System.in);
//System.in代表系统的标准输入设备,即键盘, System类的in字段是InputStream字节流
// String line = sc.nextLine(); //从键盘上读取一行
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String line = br.readLine();
while( line.length() > 0 ){
bw.write(line);
bw.newLine();
// line = sc.nextLine();
line = br.readLine();
}
bw.close(); //关闭缓冲流时,会把缓冲区的数据保存到文件中
//1) 使用缓冲字符流读取文件的内容
//创建字符流, d:/test.java文件, 该文件编码为utf-8,与当前环境编码一致
// FileReader fr = new FileReader("d:/test.java");
//创建字符流, d:/test01.java文件, 该文件编码为GBK,与当前环境编码不一致
InputStreamReader fr = new InputStreamReader(new FileInputStream("d:/test01.java"), "GBK");
//对字符流进行缓冲
BufferedReader br = new BufferedReader(fr);
//从缓冲字符流中读取数据, readLine()从输入缓冲字符流中读取一行, 读到文件末尾返回null
String line = br.readLine();
while( line != null ){
System.out.println( line);
line = br.readLine();
}
br.close();
数据流
DataInputStream/DataOutputStream 可以读写带有数据格式的数据 不直接对数据源进行操作, 是处理流
//使用DataInputStream读取文件的内容
InputStream in = new FileInputStream("d:/def.txt");
DataInputStream dis = new DataInputStream(in);
//读取的顺序要与写入的顺序一致
int num = dis.readInt();
double dd = dis.readDouble();
boolean flag = dis.readBoolean();
String text = dis.readUTF();
dis.close();
System.out.println("num=" + num + " ,dd=" + dd + " ,flag=" + flag + " ,text=" + text);
//使用DataOutputStream保存数据
OutputStream out = new FileOutputStream("d:/def.txt");
DataOutputStream dos = new DataOutputStream(out);
dos.writeInt(123); //保存整数
dos.writeDouble(3.14); //保存小数
dos.writeBoolean(true); //保存布尔
dos.writeUTF("wkcto"); //保存字符串
dos.close();
打印流
//在追加的方式建立与文件的字节流通道
OutputStream out = new FileOutputStream("d:/log.txt", true);
//创建打印流
PrintStream pStream = new PrintStream(out);
pStream.print("hello"); //打印,不换行
pStream.println(" wkcto"); //打印,换行
pStream.println("feifei");
System.out.println("在屏幕上打印信息, System类的out成员就是一个PrintStream打印流");
System.out.println("System.out代表系统的标准输出设备,显示器,");
//修改System.out的打印输出方向
System.setOut(pStream);
System.out.println("现在打印的信息就不是显示在屏幕上了, 而是打印到pstream流中,即log.txt文件中");
//有时, 也会把异常信息打印到日志文件中
try {
FileInputStream fis = new FileInputStream("F:/abc.txt");
} catch (Exception e) {
// 在开发时,一般是把异常打印到屏幕上,方便程序员调试
// e.printStackTrace();
// 在部署后, 经常把异常打印到日志文件中
e.printStackTrace(pStream);
}
pStream.close();
装饰者设计模式
设计模式就是别人总结的一套解决方案, 这套解决方案被大多数人熟知与认可
装饰者设计模式是对现有类的现有方法进行功能的扩展
在IO流相关类中,以Filter开头的类采用了装饰者设计模式
对象流
- 对象序列化:把一个对象转换为01二进制对象
- 反序列化:把一组01二进制转换为对象ObjectOutputStream类可以实现对象序列化, 把对象转换为01序列保存到文件中ObejctInputStream类实现对象反序列化,从文件中读取01序列转换为对象
- 注意:对象序列化/反序列化的前提是对象的类必须实现Serializable接口, 该接口是一个标志接口, 没有任何方法,只是告诉编译器这个类的对象可以序列化。
//创建Person对象
Person lisi = new Person("lisi", 18);
//把lisi对象序列化, 就是把lisi对象保存到文件中
OutputStream out = new FileOutputStream("d:/obj.txt");
ObjectOutputStream oos = new ObjectOutputStream(out);
oos.writeObject(lisi); //对象序列化
oos.close();
使用ObjectInputStream类实现对象的反序列化, 就是从文件中把保存的对象读取出来
InputStream in = new FileInputStream("d:/obj.txt");
ObjectInputStream ois = new ObjectInputStream(in);
Object obj = ois.readObject();//从文件中读取一个对象, readObject()方法的返回值是Object类型的
//文件中实际存储的是Person对象, 使用obj引用指向Person对象
System.out.println( obj ); //实际上调用的是Person对象的toString()方法
ois.close();
在对象序列化之后 ,即把对象已经保存到文件中了, 又在Person类中添加了一个字段,修改了Person类结构, 再进行反序列化时, 出现了异常:
java.io.InvalidClassException: com.wkcto.chapter06.objectstream.Person; local class incompatible: stream classdesc serialVersionUID = 3479771803741762411, local class serialVersionUID = 1549311491347595402
分析原因:
- 流中类的描述信息中 serialVersionUID的值与本地字节码文件中 serialVersionUID字段的值不相等引发的异常
- 当类Person实现了Serializable接口后, 系统会自动的在Person类中增加一个serialVersionUID序列化版本号字段
- 在lisi对象序列化时, serialVersionUID字段的值是: 3479771803741762411
- 当序列化后, 又在Person类添加了gender字段, 编译后,在字节码文件中重新生成了一个serialVersionUID的值:1549311491347595402
- 在进行反序列化时, 系统会检查流中serialVersionUID序列化版本号字段与本地字节码文件中serialVersionUID字段的值是否一样
- 如果相等就认为是同一个类的对象, 如果这个serialVersionUID序列化版本号字段的值不相等,就认为是不同类的对象
解决方法:
- 保证反序列化时流中serialVersionUID字段 的值,与本地字节码文件中serialVersionUID字段的值相等即可
- 可以在Person类实现了Serializable接口后, 手动的添加一个serialVersionUID字段
package com.wkcto.chapter06.objectstream;
import java.io.Serializable;
/**
* Person类的对象要想序列化, Person类必须实现Serializable接口
* Serializable接口是一个标志接口,没有任何方法
*/
public class Person implements Serializable{
String name;
int age;
String gender; //性别
//手动的添加序列化版本号字段
private static final long serialVersionUID = -1345649873215667710L;
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", gender=" + gender + "]";
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
}
文件File
// 在windows系统中文件默认分隔符是反斜杠`\`
// 在其他操作系统中, 如Linux, 文件分隔符是斜杠`/`
System.out.println(File.separator);
System.out.println(File.pathSeparator); //; 路径分隔符,Win为`;`,lin为`:`
File f1 = new File("hehe.txt"); //相对路径
f1.createNewFile();
System.out.println(f1.getAbsolutePath() );
System.out.println(f1.getPath());
System.out.println(f1.getParent());
System.out.println(f1.getName());
System.out.println(f1.isDirectory());
System.out.println(f1.isFile());
System.out.println(f1.length());
System.out.println(f1.lastModified());
System.out.println(new Date(f1.lastModified()));
//通过File构造方法的参数指定路径 ,File对象既可以是文件夹,也可以是文件
File f1 = new File("d:/java1");
File f2 = new File("d:/java2");
f1.mkdir(); //创建文件夹
f2.createNewFile(); //创建文件
//通过File构造方法的第一个参数指定上级目录
File f3 = new File("d:/java1", "sub1");
File f4 = new File("d:/java1", "sub2");
f3.mkdir();
f4.createNewFile();
File f5 = new File(f3, "sub3");
File f6 = new File(f3, "sub3");
//f5和f6两个对象重名
f5.mkdir(); //创建了sub3文件夹
f6.createNewFile(); //创建sub3文件夹, 出现了重名现象, 创建失败
//在创建File对象,也可以使用相对路径 , 相对于当前项目的路径
File f7 = new File("folder");
File f8 = new File("bin/folder2");
f7.mkdir();
f8.mkdir();
常用例子:
package com.wkcto.chapter06.file;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
/**
* 演示文件夹操作的递归调用
* @author 蛙课网
*
*/
public class Test05 {
public static void main(String[] args) {
String folder = "d:/java1";
// 显示指定文件夹的内容
// listsubDir(folder);
//文件夹的复制
copyDir( folder , "d:/java22");
}
//创建方法, 把srcfolder文件夹的内容复制到destFolder文件夹中, 包括子文件夹的内容
private static void copyDir(String srcFolder, String destFolder) {
//判断目标文件夹是否存在,如果不目标文件夹不存在,需要创建一个新的文件夹
File dest = new File(destFolder);
if ( !dest.exists() ) {
dest.mkdirs();
}
//遍历srcFolder源文件夹的内容, 复制到destFolder目录中
File src = new File(srcFolder);
File[] listFiles = src.listFiles();
for (File file : listFiles) {
if (file.isFile()) {
// 直接复制文件 , 需要先构建目标文件
File destFile = new File(destFolder, file.getName());
copyFile( file, destFile); //复制文件
}else{
//file是文件夹, 先在destFolder文件夹下创建一个与file同名的文件夹
File destSubDir = new File(destFolder, file.getName() );
// destSubDir.mkdir();
//再把file文件夹的内容复制到destFoler/file目录下
copyDir(file.getAbsolutePath(), destSubDir.getAbsolutePath());
}
}
}
//文件复制
private static void copyFile(File srcfile, File destFile) {
try(
FileInputStream fis = new FileInputStream(srcfile);
FileOutputStream fos = new FileOutputStream(destFile);
) {
byte [] bytes = new byte[1024];
int len = fis.read(bytes);
while ( len != -1){
fos.write(bytes, 0, len);
len = fis.read(bytes);
}
} catch (Exception e) {
// TODO: handle exception
}
}
// 显示指定文件夹的内容, 包括子文件夹的内容
private static void listsubDir(String folder) {
File dir = new File(folder);
// 列出指定文件夹的内容
File[] listFiles = dir.listFiles();
for (File file : listFiles) {
System.out.println(file.getAbsolutePath());
//判断file对象如果是文件夹, 把file子文件夹的内容也显示出来
if (file.isDirectory() ) {
listsubDir( file.getAbsolutePath() ); //递归调用
}
}
}
}
控制台对象
public static void copy() throws IOException{
BufferedReader bufis = new BufferedReader(new InputStreamReader(
new FileInputStream("12.doc"), "utf-8"));
String line = null;
while ((line = bufis.readLine())!=null){
System.out.println(line);
}
}
在Java中,你可以利用java.lang.System类中的两种属性,它提供从键盘输入和
从终端输出的方法——System.in和System.out。
使用System.in
System.in是InputStream,它可以使你的程序可利用的,并且提供从键盘读取未经处理的 字节的能力。不幸地是,这种形式大概不能提供有用的信息给你,所以你应该将它转换成 Reader类并且翻译成字符。利用BufferedReader类,这个类允许你利用readline()方法 一次读取一行内容。比如,如果你需要从键盘读取一个串,你可以利用下面的代码片断:
BufferedReader lineOfText = new BufferedReader( new InputStreamReader(System.in)); String textLine = lineOfText.readLine();
Readline()方法将返回整行输入,将它放到textLine中并且丢掉异常的数据。结果, 编译器会迫使你在调用readline()或者在你定义这个方法的时候放置,在定义方法的时候, 代码会构建一个throw列,这个构构建列表中所有的异常将被处理掉。
一旦你有了输出的队列,你可以简单的分析你需要的数据。也许你可以转换成整数, 看看下面的代码:
int numReadIn = 0;
try {
numReadIn = Integer.parseInt(textLine);
} catch (NumberFormatException) {
System.err.println("Trouble with the parsing of the number");
}
JDK 5.0 读取控制台的方法
从 JDK 5.0 开始,基本类库中增加了java.util.Scanner类,根据它的 API 文档说明,
这个类是采用正则表达式进行基本类型和字符串分析的文本扫描器。使用它的
Scanner(InputStream source)构造方法,可以传入系统的输入流System.in而从
控制台中读取数据。示例代码如下:
import java.util.Scanner;
public class Test3 {
public static void main(String[] args) {
String str = readString5("请输入字符串:");
System.out.println("readString5 方法的输入:" + str);
}
/**
* 使用扫描器类(Scanner)从控制台中读取字符串<br/>
* 适用于JDK 5.0及以后的版本
* @param prompt 提示信息
* @return 输入的字符串
*/
private static String readString5(String prompt) {
Scanner scanner = new Scanner(System.in);
System.out.print(prompt);
return scanner.nextLine();
}
}
从代码量上来看,Test3 比Test1 少了很多的代码,核心代码只有两行。其实并不是Scanner 将控制台输入给简单化了,只是在其内部的实现中已经将IOException 处理了,而且采用InputStreamReader 来一个字符一个字符进行扫描读取的(嘿嘿,它本身就是个扫描器),只是Scanner 做了更高层次的封装。
Scanner 不仅可以从控制台中读取字符串,还可以读取除char 之外的其他七种基本类型和两个大数字类型,并不需要显式地进行手工转换。Scanner 不单单只能扫描控制台中输入的字符,它还可以让读入的字符串匹配一定的正则表达式模式,如果不匹配时将抛出InputMismatchException 异常。
使用System.in 作为它的构造参数时,它只扫描了系统输入流中的字符。它还有其他的构造,分别可以从文件或者是字符串中扫描分析字符串的,具体的使用方法可以参考 API 文档说明。
JDK 6.0 读取控制台的方法
从 JDK 6.0 开始,基本类库中增加了java.io.Console类,用于获得与当前Java虚拟机
关联的基于字符的控制台设备。在纯字符的控制台界面下,可以更加方便地读取数据。
示例代码如下:
import java.io.Console;
import java.util.Scanner;
public class Test4 {
public static void main(String[] args) {
String str = readString6("请输入字符串:");
System.out.println("readString6 方法的输入:" + str);
}
/**
* 使用控制台类(Console)从控制台中读取字符串<br/>
* 适用于JDK 1.6或以后的版本
* @param prompt 提示信息
* @return 输入的字符串
*/
private static String readString6(String prompt) {
Console console = System.console();
if (console == null) {
throw new IllegalStateException("不能使用控制台");
}
return console.readLine(prompt);
}
}
Test3 中,输入数据前的提示信息需要使用System.out.print(); 来输出, 但是使用基于Console 的Test4 类,可以在方法参数中直接放入提示信息。
如果需要在控制台中输入密码等敏感信息的话,像在浏览器或者是应用程序中那样显示替 代字符,在 JDK 6.0 以前的做法是相当麻烦的(具体的做法可以参考《Java 编程语言中 的口令屏蔽》 一文),而使用Console 类的readPassword() 方法可以在控制台上 不回显地输入密码,并将密码结果保存在char 数组中,根据 API 文档的建议,在使用后 应立即将数组清空,以减少其在内存中占用的时间,以便增强安全性。
但是,Console 也有一些缺点,根据Console API 文档的说明:
虚拟机是否具有控制台取决于底层平台,还取决于调用虚拟机的方式。如果虚拟机从一个 交互式命令行开始启动,且没有重定向标准输入和输出流,那么其控制台将存在,并且 通常连接到键盘并从虚拟机启动的地方显示。如果虚拟机是自动启动的(例如,由后台 作业调度程序启动),那么它通常没有控制台。
通过上面的文档说明可以看出,在使用 IDE 的情况下,是无法获取到Console 实例的, 原因在于在 IDE 的环境下,重新定向了标准输入和输出流,也是就是将系统控制台上的 输入输出重定向到了 IDE 的控制台中。因此,在 IDE 中不能使用这个程序, 而Test3 就没有这种限制。
BufferedInputStream和GZIPInputStream性能调优
何时不需要缓冲
缓冲是用来减少来自输入设备的单独读取操作数的数量,许多开发者往往忽视这一点, 并经常将InputStream包含进BufferedInputStream中,如:
final InputStream is = new BufferedInputStream(new FileInputStream(file));
是否使用缓冲的简略规则如下:
- 当你的数据块足够大的时候(100K+),你不需要使用缓冲,你可以处理任何长度的块( 不需要保证在缓冲前缓冲区中至少有N bytes可用字节)。
- 在所有的其他情况下,你都需要缓冲输入数据。
最简单的不需要缓冲的例子就是手动复制文件的过程。
public static void copyFile(final File from, final File to)
throws IOException
{
final InputStream is = new FileInputStream(from);
try {
final OutputStream os = new FileOutputStream(to);
try {
final byte[] buf = new byte[8192];
int read = 0;
while ((read = is.read(buf)) != -1) {
os.write( buf, 0, read );
}
}
finally {
os.close();
}
}
finally {
is.close();
}
}
注1:衡量文件复制的性能是非常困难的,因为这很大程度上收到操作系统写入缓存的影响 。在我的机器上复制一个4.5G的文件到相同的硬盘所花费的时间在68至107s之间变化。
注2:文件复制经常通过Java NIO实现,使用FileChannel.transferTo或者
transferFrom()的方法。使用这些方法不需要再在内核和用户态之间频繁的转换(在
用户的java程序中将读入数据转换为字节缓存,再通过内核调用将它复制回输出文件中)。
相反它们在内核模式中传输尽可能多的数据(直达231-1字节),尽可能做到不返回用户的
代码中。因此,Java NIO会使用较少的CPU周期,并腾出留给其他程序。然而,只有高负荷
的环境下才能看到这当中的差异(在我的机器中,NIO模式的CPU总占用率为4%,而旧的
流模式CPU总占用率则为8-9%)。以下是一个可能的Java NIO实现:
private static void copyFileNio( final File from, final File to )
throws IOException
{
final RandomAccessFile inFile = new RandomAccessFile( from, "r" );
try
{
final RandomAccessFile outFile = new RandomAccessFile( to, "rw" );
try
{
final FileChannel inChannel = inFile.getChannel();
final FileChannel outChannel = outFile.getChannel();
long pos = 0;
long toCopy = inFile.length();
while ( toCopy > 0 )
{
final long bytes = inChannel.transferTo( pos, toCopy, outChannel );
pos += bytes;
toCopy -= bytes;
}
}
finally {
outFile.close();
}
}
finally {
inFile.close();
}
}
缓冲大小
BufferedInputStream中默认的缓冲大小是8192个字节。缓冲大小实际上是从输入设备中准备读取的块的平均大小。这就是为什么它经常值得精确地提高至64K(65536), 万一有非常大的输入文件 — 那些在512K和2M的文件,为了更深一层地减少磁盘读入的数量。许多专家也建议将此值设置为4096的整数倍 — 一个普通磁盘扇区的大小。所以,不要将缓冲区的大小设置为,像125000这样的大小,取而代之的应该是像131072(128K)这样的大小。
java.util.zip.GZIPInputStream 是一个能够很好处理gzip文件输入的输入流。它经常被用来做这样的事情:
final InputStream is = new GZIPInputStream( new BufferedInputStream(new FileInputStream(file)));
这样的初始化已经足够好了,不过BufferedInputStream在此处是多余的,因为GZIPInputStream已经拥有了自己的内建缓冲区,它里面有一个字节缓冲区(实际上,它是InflaterInputStream的成员),被用做此从底层流中读取压缩的数据,并且将其传递给一个inflater。这个缓冲区默认的大小是512字节,所以它必须被设置成一个更高的数值。一个更理想地使用GZIPInputStream的方式如下:
final InputStream is = new GZIPInputStream( new FileInputStream(file), 65536);
BufferedInputStream.available
BufferedInputStream.available 方法有一个可能的性能问题,取决于你真正想要接收到的东西。它的标准实现将返回BufferedInputStream自身的内部缓冲区可用字节数和底层输入流调用avalibale()结果的总和。所以,它将尽可能地返回一个精确的数值。但是在很多案例中,用户想知道的仅仅是缓冲区中是否还有空间可用( available() > 0). 在这种情况下,即使BufferedInputStream的缓冲区中只有一个字节余留,我们都不需要去查询底层的输入流。这显得非常重要,如果我们有一个FileInputStream包含在BufferedInputStream中–这样的优化会节省我们在FileInputStream.available()中的磁盘访问时间。
幸运的是,我们可以简单地解决这样的问题。BufferedInputStream不是一个final类,所以我们可以继承并且重载available方法。我们可以看看JDK的源代码着手准备。从这里我们还可以发现Java 6中的实现有一个bug — 如果BufferedInputStream可用的字节数和底层流available()调用结果的总和大于Integer.MaxVALUE,这样就会因为溢出而返回一个负数结果,不过这在Java 7中已经得到了解决。
以下是我们改进的实现,它将返回BufferedInputStream的内置缓冲区中可用的字节数,又或者是,如果它里面没有剩余的字节数,底层流中的available()方法会被调用,并且返回调用后的结果。在大多数情况下,这种实现会极少调用到底层流中的available()方法,因为当BufferedInputStream缓冲区被读取到最后,这个类会读取从底层流中读取更多的数据,所以,我们只会在输入文件的末尾中调用底层流的available()方法。
public class FasterBufferedInputStream extends BufferedInputStream
{
public FasterBufferedInputStream(InputStream in, int size) {
super(in, size);
}
//如果有东西可用,该方法将返回一个正数,否则它会返回0。
public int available() throws IOException {
if (in == null)
throw new IOException( "Stream closed" );
final int n = count - pos;
return n > 0 ? n : in.available();
}
}
为了测试这个实现,我尝试使用标准版的和改进版的BufferedInputStream去读取4.5G的文件,它们都有64K的缓冲区大小,并且每读取512或者1024字节的时候就调用一次available()方法。干净的测试需要操作系统在每一次测试之后重启以清除磁盘缓存。于是我决定在热身阶段读取文件,当文件已经在磁盘缓存时就用两种方法测试性能。测试显示,标准类的运行时间与available()调用的数量呈线性关系。而改进的方法运行时间看起来却与调用的次数无关。
这里是测试的源代码:
| standard, once per 512 bytes | improved, once per 512 bytes | standard, once per 1024 bytes | improved, once per 1024 bytes | |
|---|---|---|---|---|
| Java6 | 17.062 sec | 2.11 sec | 9.592 sec | 2.047 sec |
| Java7 | 17.337 sec | 2.125 sec | 9.748 sec | 2.044 sec |
private static void testRead(final InputStream is) throws IOException {
final long start = System.currentTimeMillis();
final byte[] buf = new byte[512]; //or 1024 bytes
while (true) {
if (is.available() == 0) break;
is.read( buf );
}
final long time = System.currentTimeMillis() - start;
System.out.println("Impl: " + is.getClass().getCanonicalName() +
" time = " + time / 1000.0 + " sec");
}
使用以下的声明变量调用以上方法:
final InputStream is1 = new BufferedInputStream( new FileInputStream(file), 65536); final InputStream is2 = new FasterBufferedInputStream( new FileInputStream(file), 65536);
总结
- BufferedInputStream和GZIPInputStream 都有内建的缓冲区。前者默认的缓冲大小是8192字节,后者则为512字节。一般而言,它值得增加任何它们的整数倍大小到至少65536。
- 不要使用BufferedInputStream作为GZIPInputStream的输入,相反,显示地在构造器中设置GZIPInputStream的缓存大小。虽然,保持BufferedInputStream仍然是安全的。
- 如果你有一个new BufferedInputStream( new FileInputStream( file ) )对象,并且需要频繁地调用它的available方法(例如,每输入一次信息都需要调用一次或者两次),考虑重载 BufferedInputStream.available方法,它将极大地提高文件读取的速度。
示例:优化压缩
随着文件的大小越来越大的时候,耗费的时间也在急剧增加, 最后测了一下压缩20M的文件竟然需要30秒的时间。压缩文件的代码如下。
public static void zipFileNoBuffer() {
File zipFile = new File(ZIP_FILE);
try (
ZipOutputStream zipOut = new ZipOutputStream(
new FileOutputStream(zipFile))
) {
//开始时间
long beginTime = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
try (InputStream input = new FileInputStream(JPG_FILE)) {
zipOut.putNextEntry(new ZipEntry(FILE_NAME + i));
int temp = 0;
while ((temp = input.read()) != -1) {
zipOut.write(temp);
}
}
}
printInfo(beginTime);
} catch (Exception e) {
e.printStackTrace();
}
}
通过缓冲优化
public static void zipFileBuffer() {
File zipFile = new File(ZIP_FILE);
try (ZipOutputStream zipOut = new ZipOutputStream(
new FileOutputStream(zipFile));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(
zipOut))
{
//开始时间
long beginTime = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
try (BufferedInputStream bufferedInputStream = //
new BufferedInputStream(new FileInputStream(JPG_FILE))) {
zipOut.putNextEntry(new ZipEntry(FILE_NAME + i));
int temp = 0;
while ((temp = bufferedInputStream.read()) != -1) {
bufferedOutputStream.write(temp);
}
}
}
printInfo(beginTime);
} catch (Exception e) {
e.printStackTrace();
}
}
通过NIO Channel优化
因为在NIO中新出了Channel和ByteBuffer。正是因为它们的结构更加符合操作系统执行I/O 的方式,所以其速度相比较于传统IO而言速度有了显著的提高。Channel就像一个包含着 煤矿的矿藏,而ByteBuffer则是派送到矿藏的卡车。也就是说我们与数据的交互都是与 ByteBuffer的交互。
在NIO中能够产生FileChannel的有三个类。分别是FileInputStream、FileOutputStream、 以及既能读又能写的RandomAccessFile。
public static void zipFileChannel() {
//开始时间
long beginTime = System.currentTimeMillis();
File zipFile = new File(ZIP_FILE);
try (ZipOutputStream zipOut = new ZipOutputStream(
new FileOutputStream(zipFile));
WritableByteChannel writableByteChannel = Channels.newChannel(zipOut))
{
for (int i = 0; i < 10; i++) {
try (FileChannel fileChannel = //
new FileInputStream(JPG_FILE).getChannel())
{
zipOut.putNextEntry(new ZipEntry(i + SUFFIX_FILE));
fileChannel.transferTo(0, FILE_SIZE, writableByteChannel);
}
}
printInfo(beginTime);
} catch (Exception e) {
e.printStackTrace();
}
}
我们可以看到这里并没有使用ByteBuffer进行数据传输,而是使用了transferTo的方法。这个方法是将两个通道进行直连。
This method is potentially much more efficient than a simple loop
- that reads from this channel and writes to the target channel. Many
- operating systems can transfer bytes directly from the filesystem cache
- to the target channel without actually copying them.
这是源码上的描述文字,大概意思就是使用transferTo的效率比循环一个Channel 读取出来然后再循环写入另一个Channel好。操作系统能够直接传输字节从文件系统 缓存到目标的Channel中,而不需要实际的copy阶段。
copy阶段就是从内核空间转到用户空间的一个过程
可以看到速度相比较使用缓冲区已经有了一些的提高。
内核空间和用户空间
那么为什么从内核空间转向用户空间这段过程会慢呢?首先我们需了解的是什么是内核空间 和用户空间。在常用的操作系统中为了保护系统中的核心资源,于是将系统设计为四个 区域,越往里权限越大,所以Ring0被称之为内核空间,用来访问一些关键性的资源。 Ring3被称之为用户空间。
- Ring 0:内核
- Ring 1:设备驱动
- Ring 2:设备驱动
- Ring 3:应用
用户态、内核态:线程处于内核空间称之为内核态,线程处于用户空间属于用户态。
应用程序是都属于用户态的,访问核心资源就需要调用内核中所暴露出的接口用以调用, 称之为系统调用。例如访问磁盘上的文件,应用程序就会调用系统调用的接口open方法, 然后内核去访问磁盘中的文件,将文件内容返回给应用程序。大致的流程如下:
- 用户态逻辑
- 系统调用(用户态切换到内核态)
- 保存寄存器
- 内核态逻辑
- 恢复寄存器
- 系统调用返回(内核态切换到用户态)
- 用户态逻辑
直接缓冲区和非直接缓冲区
既然我们要读取一个磁盘的文件,要废这么大的周折。有没有什么简单的方法能够使我们的 应用直接操作磁盘文件,不需要内核进行中转呢?有,那就是建立直接缓冲区了。
- 非直接缓冲区:非直接缓冲区就是我们上面所讲内核态作为中间人,每次都需要内核在 中间作为中转。
- 直接缓冲区:直接缓冲区不需要内核空间作为中转copy数据,而是直接在物理内存申请 一块空间,这块空间映射到内核地址空间和用户地址空间,应用程序与磁盘之间数据的 存取通过这块直接申请的物理内存进行交互。
既然直接缓冲区那么快,我们为什么不都用直接缓冲区呢?其实直接缓冲区有以下的缺点。直接缓冲区的缺点:
- 不安全
- 消耗更多,因为它不是在JVM中直接开辟空间。这部分内存的回收只能依赖于 垃圾回收机制,垃圾什么时候回收不受我们控制。
- 数据写入物理内存缓冲区中,程序就丧失了对这些数据的管理,即什么时候这些数据 被最终写入从磁盘只能由操作系统来决定,应用程序无法再干涉。
综上所述,所以我们使用transferTo方法就是直接开辟了一段直接缓冲区。 所以性能相比而言提高了许多
使用内存映射文件
NIO中新出的另一个特性就是内存映射文件,内存映射文件为什么速度快呢? 其实原因和上面所讲的一样,也是在内存中开辟了一段直接缓冲区。 与数据直接作交互。源码如下
//Version 4 使用Map映射文件
public static void zipFileMap() {
//开始时间
long beginTime = System.currentTimeMillis();
File zipFile = new File(ZIP_FILE);
try (ZipOutputStream zipOut = new ZipOutputStream(
new FileOutputStream(zipFile));
WritableByteChannel writableByteChannel = Channels.newChannel(zipOut))
{
for (int i = 0; i < 10; i++) {
zipOut.putNextEntry(new ZipEntry(i + SUFFIX_FILE));
//内存中的映射文件
MappedByteBuffer mappedByteBuffer =
new RandomAccessFile(JPG_FILE_PATH, "r").getChannel().map(
FileChannel.MapMode.READ_ONLY, 0, FILE_SIZE);
writableByteChannel.write(mappedByteBuffer);
}
printInfo(beginTime);
} catch (Exception e) {
e.printStackTrace();
}
}
使用Pipe
Java NIO 管道是2个线程之间的单向数据连接。Pipe有一个source通道和一个sink通道。 其中source通道用于读取数据,sink通道用于写入数据。可以看到源码中的介绍, 大概意思就是写入线程会阻塞至有读线程从通道中读取数据。如果没有数据可读, 读线程也会阻塞至写线程写入数据。直至通道关闭。
//Version 5 使用Pip
public static void zipFilePip() {
long beginTime = System.currentTimeMillis();
try(WritableByteChannel out =
Channels.newChannel(new FileOutputStream(ZIP_FILE)))
{
Pipe pipe = Pipe.open();
//异步任务
CompletableFuture.runAsync(()->runTask(pipe));
//获取读通道
ReadableByteChannel readableByteChannel = pipe.source();
ByteBuffer buffer = ByteBuffer.allocate(((int) FILE_SIZE)*10);
while (readableByteChannel.read(buffer)>= 0) {
buffer.flip();
out.write(buffer);
buffer.clear();
}
}catch (Exception e){
e.printStackTrace();
}
printInfo(beginTime);
}
//异步任务
public static void runTask(Pipe pipe) {
try(ZipOutputStream zos = new ZipOutputStream(
Channels.newOutputStream(pipe.sink()));
WritableByteChannel out = Channels.newChannel(zos))
{
System.out.println("Begin");
for (int i = 0; i < 10; i++) {
zos.putNextEntry(new ZipEntry(i+SUFFIX_FILE));
FileChannel jpgChannel = new FileInputStream(
new File(JPG_FILE_PATH)).getChannel();
jpgChannel.transferTo(0, FILE_SIZE, out);
jpgChannel.close();
}
}catch (Exception e){
e.printStackTrace();
}
}