Java类加载器
Java类加载器
背景知识
正确理解类加载器能够帮你解决NoClassDefFoundError和
java.lang.ClassNotFoundException,因为它们和类的加载相关。
显式地加载类
Java提供了显式加载类的API:
-
Class.forName(classname) -
Class.forName(classname, initialized, classloader)
上面的接口说明可以指定类加载器的名称以及要加载的类的名称。
类的加载是通过调用java.lang.ClassLoader的loadClass()方法,
而loadClass()方法则调用了findClass()方法来定位相应类的字节码。
URL url =
(new File("file:/Downloads/u.jar")) .toURI();
URLClassLoader uc = new URLClassLoader(new URL[]{url});
Class class = uc.loadClass("t.User");
Object newInstance = class.newInstance();
-
在这个例子使用了
java.net.URLClassLoader,它从JAR和目录中进行查找类文件, 所有以/结尾的查找路径被认为是目录。 -
如果
findClass()没有找到那么它会抛出java.lang.ClassNotFoundException异常, -
如果找到的话则会调用
defineClass()将字节码转化成类实例,然后返回。
类加载器简介
- 类加载器的功能是通过一个类的全限定名来获取描述此类的二进制字节流。
- 类加载器在Java虚拟机的外部。
- 每一个类加载器,都拥有一个独立的类命名空间。 同一个class文件通过不同的类加载器加载到同一个Java虚拟机,这些类必定不相等。
什么地方使用类加载器
类加载器在很多地方被运用,最经典的例子就是AppletClassLoader,
它被用来加载Applet使用的类,而Applets大部分是在网上使用,
而非本地的操作系统使用。
使用不同的类加载器,你可以从不同的源地址加载同一个类,它们被视为不同的类。
J2EE使用多个类加载器加载不同地方的类,例如WAR文件由Web-app类加载器加载,
而EJB-JAR中的类由另外的类加载器加载。有些服务器也支持热部署,
这也由类加载器实现。你也可以使用类加载器来加载数据库或者其他持久层的数据。
类加载器的分类
从Java虚拟机的角度来说,只存在两种不同类加载器:
- 一种是启动类加载器(Bootstrap ClassLoader),这个类加载器使用C++语言实现 (只限HotSpot),是虚拟机自身的一部分。
-
另一种就是所有其他的类加载器,这些类加载器都由Java语言实现,独立于虚拟机外部,
并且全都继承自抽象类
java.lang.ClassLoader。
从Java开发人员的角度来看,类加载还可以划分的更细致一些,绝大部分Java程序员都会 使用以下3种系统提供的类加载器:
-
启动类加载器(Bootstrap ClassLoader): 这个类加载器负责加载
JAVA_HOME/lib目录中的rt.jar,或者被-Xbootclasspath参数所指定的路径, 并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录下也不会重载)。它是所有类加载器的父加载器。 Bootstrap类加载器没有 任何父类加载器,如果你调用String.class.getClassLoader()会返回null, 任何基于此的代码会抛出NUllPointerException异常。 -
扩展类加载器(Extension ClassLoader): 这个类加载器由
sun.misc.Launcher$ExtClassLoader实现,它负责夹杂JAVA_HOME/lib/ext目录下的, 或者被java.ext.dirs系统变量所指定的路径种的所有类库。开发者可以直接使用 扩展类加载器。 -
应用程序类加载器(Application ClassLoader): 这个类加载器由
sun.misc.Launcher$AppClassLoader实现。由于这个类加载器是ClassLoader.getSystemClassLoader()方法的返回值,所以也成为系统类加载器。 它负责加载由-classpath或-cp命令行选项或是*.jar文件中的MANIFEST文件的classpath中指来定义的用户类路径(ClassPath)上所指定的类库。 开发者可以直接使用这个类加载器,如果应用中没有定义过自己的类加载器, 一般情况下这个就是程序中默认的类加载器。

双亲委派模型
双亲委派模型(Parents Dlegation Mode)并不是个强制性的约束模型, 而是Java设计者推荐给开发者的一种类加载器实现方式。
双亲委派模型要求除了顶层的启动类加载器之外, 其余的类加载器都应当由自己的父类加载器加载。 这里类加载器之间的父子关系一般不会以继承的关系来实现, 而是都使用组合关系来复用父加载器的代码。
如果一个类加载器收到了类加载的请求,他首先不会自己去尝试加载这个类, 而是把这个请求委派父类加载器去完成。每一个层次的类加载器都是如此, 因此所有的加载请求最终都应该传送到顶层的启动类加载器中, 只有当父加载器反馈自己无法完成这个请求(他的搜索范围中没有找到所需的类)时, 子加载器才会尝试自己去加载。
如果没有使用双亲委派模型,由各个类加载器自行加载的话,
如果用户自己编写了一个称为java.lang.Object的类,并放在程序的ClassPath中,
那系统将会出现多个不同的Object类, Java类型体系中最基础的行为就无法保证。
应用程序也将会变得一片混乱。
实现的方法
双亲委任模型的实现非常简单,逻辑清晰易懂:
- 先检查是否已经被加载过,若没有加载则调用父加载器的loadClass方法,
- 如父加载器为空则默认使用启动类加载器作为父加载器。
- 如果父类加载失败,抛出ClassNotFoundException 异常后,再调用自己的findClass方法进行加载。
所有的代码都在java.lang.ClassLoader.loadClass():
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
双亲委派模型无法实现的工作
预留接口调用第三方API
双亲委派模型很好的解决了各个类加载器的基础类的统一问题 (越基础的类由越上层的加载器进行加载),基础类之所以称为“基础”, 是因为它们总是作为被用户代码调用的API。但当基础类需要调用会用户的代码时, 就不能使用双亲委派模式。
比如需要调用由独立厂商实现并部署在应用程序的ClassPath下的例如JNDI、JDBC、JCE、JAXB、JBI等提供者 (SPI,Service Provider Interface)的代码,
一个典型的例子就是JNDI服务,JNDI现在已经是Java的标准服务,
它的代码由启动类加载器去加载rt.jar,但它需要调用由独立厂商实现并部署在应用程序的
JNDI接口代码,但启动类加载器不可能“认识“这些代码啊。因为这些类不在rt.jar中,
但是启动类加载器又需要加载。
为了解决这个问题,Java设计团队只好引入了一个不太优雅的设计:
线程上下文类加载器(Thread Context ClassLoader)。
这个类加载器可以通过java.lang.Thread类的setContextClassLoader方法进行设置。
如果创建线程时还未设置,它将会从父线程中继承一个,
如果在应用程序的全局范围内都没有设置过多的话,
那这个类加载器默认即使应用程序类加载器。
有了线程上下文加载器,JNDI服务使用这个线程上下文加载器去加载所需要的SPI代码, 也就是父类加载器请求子类加载器去完成类加载的动作, 这种行为实际上就是打通了双亲委派模型的层次结构来逆向使用类加载器, 实际上已经违背了双亲委派模型的一般性原则。但这无可奈何, Java中所有涉及SPI的加载动作基本胜都采用这种方式。
动态加载模块
为了实现热插拔,热部署,模块化,意思是添加一个功能或减去一个功能不用重启。
实现的方式只需要把这模块连同类加载器一起换掉就实现了代码的热替换。
可见性
下级加载器可以看到上级加载的类,但上级加载器看不到下级加载的类。
根据可见性机制,子类加载器可以看到父类加载器加载的类,而反之则不行。
所以下面的例子中,当Abc.class已经被Application类加载器加载过了,
然后如果想要使用Extension类加载器加载这个类,
将会抛出java.lang.ClassNotFoundException异常:
package test;
import java.util.logging.Level;
import java.util.logging.Logger;
/**
* Java program to demonstrate How ClassLoader works in Java,
* in particular about visibility principle of ClassLoader.
*
* @author Javin Paul
*/
public class ClassLoaderTest {
public static void main(String args[]) {
try {
//printing ClassLoader of this class
System.out.println(
"ClassLoaderTest.getClass().getClassLoader() : " +
ClassLoaderTest.class.getClassLoader());
// trying to explicitly load this class again using
// Extension class loader
Class.forName(
"test.ClassLoaderTest", true,
ClassLoaderTest.class.getClassLoader().getParent());
} catch (ClassNotFoundException ex) {
Logger.getLogger(ClassLoaderTest.class.getName())
.log(Level.SEVERE, null, ex);
}
}
}
输出:
ClassLoaderTest.getClass().getClassLoader() : sun.misc.Launcher$AppClassLoader@601bb1
16/08/2012 2:43:48 AM test.ClassLoaderTest main
SEVERE: null
java.lang.ClassNotFoundException: test.ClassLoaderTest
at java.net.URLClassLoader$1.run(URLClassLoader.java:202)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:190)
at sun.misc.Launcher$ExtClassLoader.findClass(Launcher.java:229)
at java.lang.ClassLoader.loadClass(ClassLoader.java:306)
at java.lang.ClassLoader.loadClass(ClassLoader.java:247)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:247)
at test.ClassLoaderTest.main(ClassLoaderTest.java:29)
单一性
仅加载一个类一次,这是由委托机制确保子类加载器不会再次加载父类加载器加载过的类。
单一性并不是强制性的,但是在大多数情况下应该严格遵守。
学习OSGI
Java 程序中基本有一个共识:OSGI对类加载器的使用时值得学习的,弄懂了OSGI的实现, 就可以算是掌握了类加载器的精髓。
Tomcat的类加载器
需求分析
Tomcat是个web容器, 那么它要解决什么问题:
- 一个web容器可能需要部署两个应用程序, 不同的应用程序可能会依赖同一个第三方类库的不同版本, 不能要求同一个类库在同一个服务器只有一份, 因此要保证每个应用程序的类库都是独立的,保证相互隔离。
- 部署在同一个web容器中相同的类库相同的版本可以共享。 否则,如果服务器有10个应用程序,那么要有10份相同的类库加载进虚拟机。
- web容器也有自己依赖的类库,不能于应用程序的类库混淆。 基于安全考虑,应该让容器的类库和程序的类库隔离开来。
- web容器要支持jsp的修改,jsp文件最终也是要编译成class文件才能在虚拟机中运行, 但程序运行后修改jsp已经是司空见惯的事情,所以web容器需要支持 jsp 修改后不用重启。
前三个通过双亲委派机制就可以实现;动态加载需要每个JSP对应一个加载器, 修改JSP后把旧的servlet和加载器一起替换掉就可以。
类加载结构
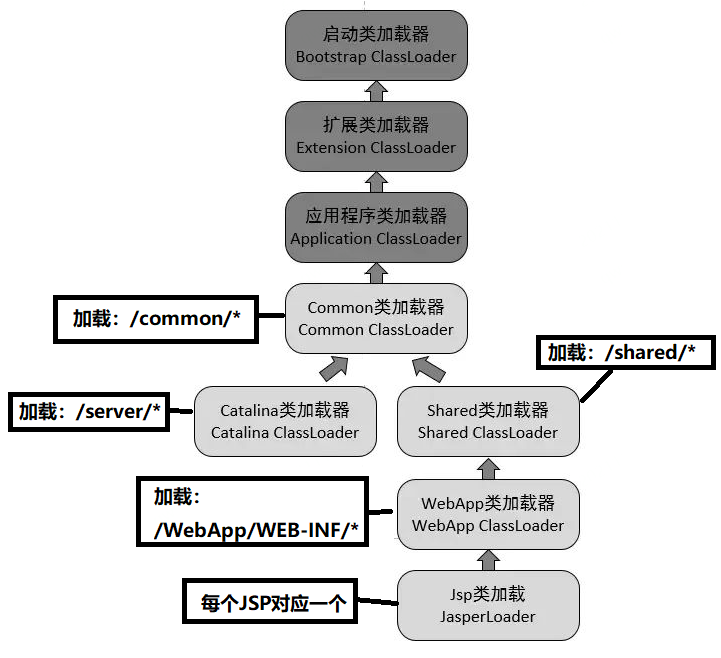
我们看到前面3个类加载和默认的一致,然后下游的TOMCAT使用的加载器有:
-
CommonLoader:Tomcat最基本的类加载器,加载/common/*路径中的class可以被 Tomcat容器本身以及各个Webapp访问;(在tomcat 6之后已经合并到根目录下的lib目录下) -
CatalinaLoader:Tomcat容器私有的类加载器,加载/server/*路径中的class对于 Webapp不可见;(在tomcat 6之后已经合并到根目录下的lib目录下) -
SharedLoader:各个Webapp共享的类加载器,加载/shared/*路径中的class对于所有 Webapp可见,但是对于Tomcat容器不可见;(在tomcat 6之后已经合并到根目录下的lib目录下) -
WebappClassLoader:每一个Web应用程序对应一个私有的类加载器, 加载/WebApp/WEB-INF/*路径中的class只对当前Webapp可见; -
JasperLoader:每一个JSP文件对应一个Jsp类加载器。 加载范围仅仅是这个JSP文件所编译出来的那一个.Class文件。 它出现的目的就是为了被丢弃:当Web容器检测到JSP文件被修改时, 会替换掉目前的JasperLoader的实例, 并通过再建立一个新的Jsp类加载器来实现JSP文件的HotSwap功能。
我们前面说过:双亲委派模型要求除了顶层的启动类加载器之外, 其余的类加载器都应当由自己的父类加载器加载。 很显然,tomcat 不是这样实现,tomcat 为了实现隔离性,没有遵守这个约定, 每个webappClassLoader加载自己的目录下的class文件,不会传递给父类加载器。
如果tomcat 的 CommonClassLoader 想加载 WebAppClassLoader 中的类,该怎么办? 我们可以使用线程上下文类加载器实现,使用线程上下文加载器, 可以让父类加载器请求子类加载器去完成类加载的动作。
加载被修改过的类
同一类的不同版本
对象的getClass()方法取得类型:
Class clazz = "Hello World".getClass(); System.out.println(clazz);
对象的invoke()方法调用:
MyObject mo = new MyObject();
mo.method();
// 相当于
mo.getClass().getDeclaredMethod("method").invoke(mo);
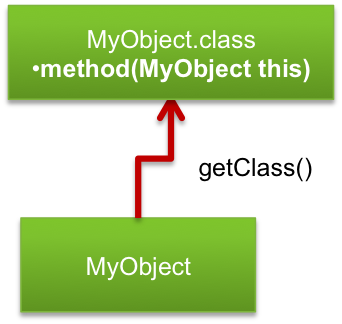
取得类加载器:
mo.class.getClassLoader();
在Java中如果之后加载了同一个类的新版本实现,新加载的版本被视为一个不同的类。 旧版本类所建立的对象都只关联到旧版本的类上:
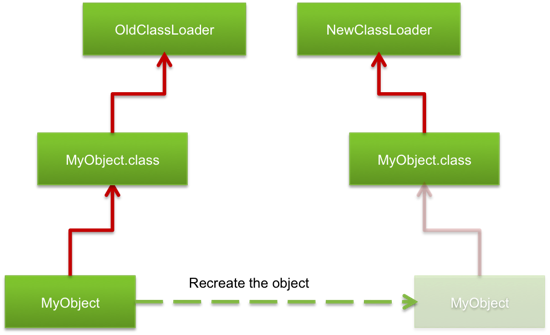
就像是换电话号码一样:只换电话号码很简单, 但是要通知到所有所有的联系人改成你换的新号码很麻烦。
保留老版本的状态
定义一个用来观察的类Example:
public interface IExample {
String message();
int plusPlus();
}
public class Example implements IExample {
private int counter;
public String message() {
return "Version 1";
}
public int plusPlus() {
return counter++;
}
public int counter() {
return counter;
}
}
在测试程序中循环开始前建立一个实例,然后每次循环中都建立一个新的实例:
public class Main {
private static IExample example1;
private static IExample example2;
public static void main(String[] args) {
example1 = ExampleFactory.newInstance(); // factory class
while (true) {
example2 = ExampleFactory.newInstance(); // factory class
System.out.println("1) " +
example1.message() + " = " + example1.plusPlus());
System.out.println("2) " +
example2.message() + " = " + example2.plusPlus());
System.out.println();
Thread.currentThread().sleep(3000);
}
}
}
如果忽略异常处理,那么工厂类的实现很简单:
public class ExampleFactory {
public static IExample newInstance() throws Exception {
URL resource = Thread.currentThread()//
.getContextClassLoader().getResource("");
URLClassLoader tmp = //
new URLClassLoader(new URL[] { resource }) {
public Class loadClass(String name) //
throws ClassNotFoundException //
{
if ("test.classloader.Example".equals(name)) {
return findClass(name);
}
return super.loadClass(name);
}
};
return (IExample) tmp //
.loadClass("test.classloader.Example").newInstance();
}
}
getClassPath()返回硬编码的 classpath ,更好的方法是通过
ClassLoader.getResource() 取得。
程序运行的输出为:
Version 1 = 3 Version 1 = 0
因为每个循环中会再次加载Example类,如果在程序执行过程中Example类被修改了,
比如把Example.message()输出的文本改为Version 2那么后继的循环的输出的就是:
Version 1 = 4 Version 2 = 0
第一个实例不断地增加计数,但执行的是旧版的代码,第二个实例会不断更新类版本, 但是每次更新都会丢失之前计数:
为了保留第二个实例的计数状态,增加Example.copy()
方法用于在构造新实例时复制之前的状态。
public IExample copy(IExample example) {
if (example != null)
counter = example.counter();
return this;
}
这样主程序Main.main()每次构建新实例时通过之前的状态复制计数:
example2 = ExampleFactory.newInstance().copy(example2);
程序一开始执行时两边都有计数:
Version 1 = 3 Version 1 = 3
即使在程序执行过程中修改并编译Example.message()输出格式为Version 2,
计数状态依然被保留了下来:
Version 1 = 4 Version 2 = 4
source code:java/classloader/rjc101.zip
类加载器引起内存泄漏
类加载器会导致内存泄漏:在目前的Java平台中,在生产环境里几次动态布署就会导致
OutOfMemoryError’s。
我们加载一个新的类时,丢弃旧的类加载器并创建一个新的。 并尽可能把对象的状态复制回来:
但是需要注意:
- 类加载器其实也维护了每个由他加载的类的引用。
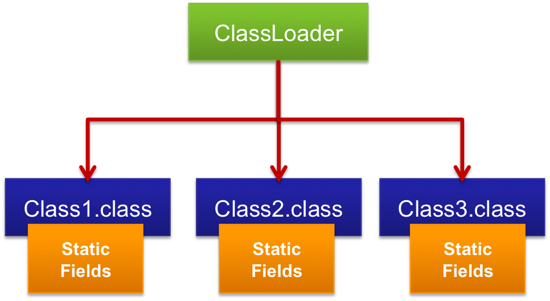
这就意味着:
- 类加载器维护了加载过的类的引用。而静态成员往往保存着各种缓存, 即便你写的程序没有大容量的缓存,但你引用的第三方框架很有可能有。 所以这种泄漏的代价可能很大。
- 每个类维护了加载自己的类加载的引用,所以一个类创建的对象都保留着对类的引用。 所以重新加载与布署的过程有没有清理的对象会导致内存泄漏,而且这种情况很常见。
泄漏的例子
在循环中重新加载类:
public class Main {
private static IExample example1;
private static IExample example2;
public static void main(String[] args) {
example1 = ExampleFactory.newInstance().copy();
while (true) {
example2 = ExampleFactory.newInstance().copy();
System.out.println("1) " + example1.message() + " = " +
example1.plusPlus());
System.out.println("2) " + example2.message() + " = " +
example2.plusPlus());
System.out.println();
Thread.currentThread().sleep(3000);
}
}
}
为了演示泄漏的场景,我们创建Leak类型和接口ILeak:
interface ILeak {
}
public class Leak implements ILeak {
private ILeak leak;
public Leak(ILeak leak) {
this.leak = leak;
}
}
Leak只是作为一个链表,每一项都维护前一项的引用。
我们在Example添加Leak成员并丢入一个大数组来演示对内存的战用:
public class Example implements IExample {
private int counter;
private ILeak leak;
private static final long[] cache = new long[1000000];
/* message(), counter(), plusPlus() impls */
public ILeak leak() {
return new Leak(leak);
}
public IExample copy(IExample example) {
if (example != null) {
counter = example.counter();
leak = example.leak();
}
return this;
}
}
这里的重点是:
-
Example维护对Leak,但Leak没有对Example的引用。 -
当
Example.copy()时会创建一个新的Leak对象并保留前一个Leak的引用。
这样执行程序很容易就生耗尽内存:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at example.Example.<clinit>(Example.java:8)
分析
Java6可以使用参数-XX:+HeapDumpOnOutOfMemoryError保存堆错误状态:
java.lang.OutOfMemoryError: Java heap space Dumping heap to java_pid37266.hprof ... Heap dump file created [57715044 bytes in 1.707 secs] Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at example.Example.<clinit>(Example.java:8)
然后可以使用JDK中的jhat或是Eclipse中的EMA(Eclipse Memory Analyzer)
分析dump文件。
通过EMA中的 Dominator Tree analysis 可以看到最大的内存消耗和
哪些对象持有它们的引用。在这个例子中是Leak类型占据了大量的堆内存:
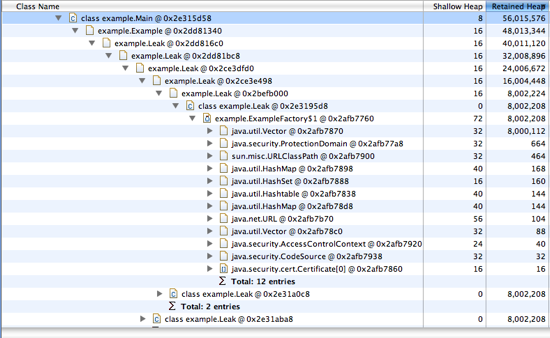
查看泄漏的对象持有什么资源,执行查询:
List objects -> with outgoing references 然后搜索:example.Leak:
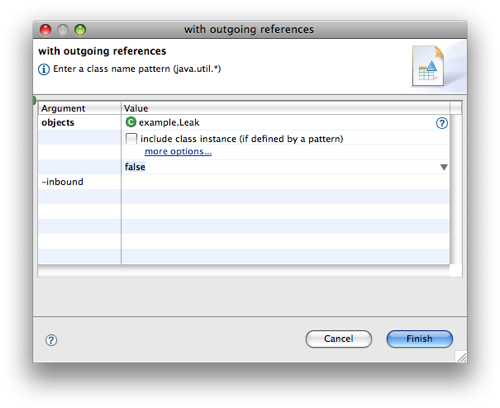
查到多个Leak对象间接地通过几个实例持有Example实例的引用:
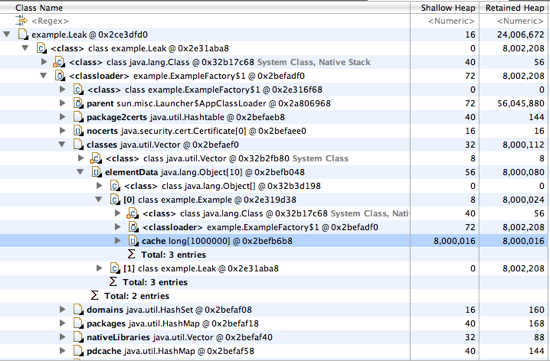
其中有一个间接的类型为ExampleFactory$1,
它是ExampleFactory中定义的URLClassLoader的匿名类。
所以现在的状况是:
-
每个
Leak对象都被下一个Leak引用形成一个链表所以无法回收生成泄漏, 而它们都持有类加载器的引用。 -
类加载器又持有它加载过的
Example类
结论
单对象的泄漏如果遇到类的重新加载用到了新的类加载器, 会导致相关类加载器加载过的类一起泄漏。所以遇到内存异常时用IDE等工具非常必要。
source code:java/classloader/rjc2011.zip
Web服务器
In order for a Java EE web application to run, it has to be packaged into an archive with a .WAR extension and deployed to a servlet container like Tomcat. This makes sense in production, as it gives you a simple way to assemble and deploy the application, but when developing that application you usually just want to edit the application’s files and see the changes in the browser.
A Java EE enterprise application has to be packaged into an archive with an .EAR extension and deployed to an application container. It can contain multiple web applications and EJB modules, so it often takes a while to assemble and deploy it. Recently, 1100+ EE developers told us how much time it takes them, and we compiled the results into the Redeploy and Restart Report. Spoiler: Avg redeploy & restart time is 2.5 minutes – which is higher than we expected.
In Reloading Java Classes 101 java.classloader.base , we examined how dynamic classloaders can be used to reload Java classes and applications. In this article we will take a look at how servers and frameworks use dynamic classloaders to speed up the development cycle. We’ll use Apache Tomcat as the primary example and comment when behavior differs in other containers (Tomcat is also directly relevant for JBoss and GlassFish as these containers embed Tomcat as the servlet container).
Redeployment
To make use of dynamic classloaders we must first create them. When deploying your application, the server will create one classloader for each application (and each application module in the case of an enterprise application). The classloaders form a hierarchy as illustrated:
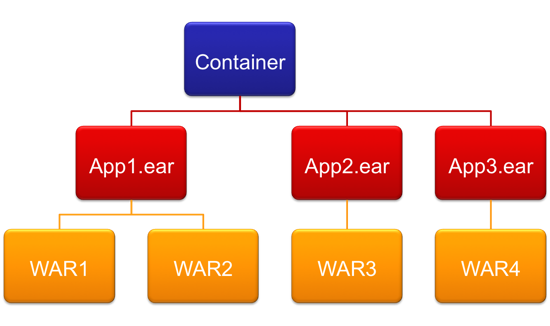
In Tomcat each .WAR application is managed by an instance of the StandardContext class that creates an instance of WebappClassLoader used to load the web application classes. When a user presses 「reload」 in the Tomcat Manager the following will happen:
-
StandardContext.reload()method is called -
The previous
WebappClassLoaderinstance is replaced with a new one - All reference to servlets are dropped
- New servlets are created
-
Servlet.init()is called on them
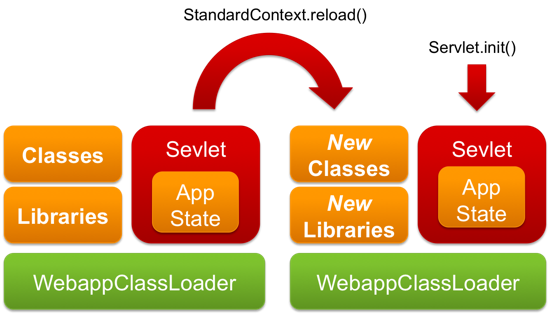
Calling Servlet.init() recreates the 「initialized」 application state with the updated classes loaded using the new classloader instance. The main problem with this approach is that to recreate the 「initialized」 state we run the initialization from scratch, which usually includes loading and processing metadata/configuration, warming up caches, running all kinds of checks and so on. In a sufficiently large application this can take many minutes, but in a in small application this often takes just a few seconds and is fast enough to seem instant, as commonly demonstrated in the Glassfish v3 promotional demos.
If your application is deployed as an .EAR archive, many servers allow you to also redeploy each application module separately, when it is updated. This saves you the time you would otherwise spend waiting for non-updated modules to reinitialize after the redeployment.
Hot Deployment
Web containers commonly have a special directory (e.g. 「webapps」 in Tomcat, 「deploy」 in JBoss) that is periodically scanned for new web applications or changes to the existing ones. When the scanner detects that a deployed .WAR is updated, the scanner causes a redeploy to happen (in Tomcat it calls the StandardContext.reload() method). Since this happens without any additional action on the user’s side it is commonly referred to 「Hot Deployment」.
Hot Deployment is supported by all wide-spread application servers under different names: autodeployment, rapid deployment, autopublishing, hot reload, and so on. In some containers, instead of moving the archive to a predefined directory you can configure the server to monitor the archive at a specific path. Often the redeployment can be triggered from the IDE (e.g. when the user saves a file) thus reloading the application without any additional user involvement. Although the application is reloaded transparently to the user, it still takes the same amount of time as when hitting the 「Reload」 button in the admin console, so code changes are not immediately visible in the browser, for example.
Another problem with redeployment in general and hot deployment in particular is classloader leaks. As we reviewed in Reloading Java Classes 201 java.classloader.mem-leak , it is amazingly easy to leak a classloader and quickly run out of heap causing an OutOfMemoryError. As each deployment creates new classloaders, it is common to run out of memory in just a few redeploys on a large enough application (whether in development or in production).
Exploded Deployment
An additional feature supported by the majority of web containers is the so called 「exploded deployment」, also known as 「unpackaged」 or 「directory」 deployment. Instead of deploying a .WAR archive, one can deploy a directory with exactly the same layout as the .WAR archive:
Why bother? Well, packaging an archive is an expensive operation, so deploying the directory can save quite a bit of time during build. Moreover, it is often possible to set up the project directory with exactly the same layout as the .WAR archive. This means an added benefit of editing files in place, instead of copying them to the server. Unfortunately, as Java classes cannot be reloaded without a redeploy, changing a .java file still means waiting for the application to reinitialize.
With some servers it makes sense to find out exactly what triggers the hot redeploy in the exploded directory. Sometimes the redeploy will be triggered only when the 「web.xml」 timestamp changes, or as in the case of GlassFish only when a special 」.reload」 file timestamp changes. In most servers any change to deployment descriptors or compiled classes will cause a hot redeploy.
If your server only supports deploying by copying to a special directory (e.g. Tomcat 「webapps」, JBoss 「deploy」 directories) you can skip the copying by creating a symlink from that special directory to your project workspace. On Linux and Mac OS X you can use the common 「ln -s」 command to do that, whereas on Windows you should download the Sysinternals 「junction」 utility.
If you use Maven, then it’s quite complicated to set up exploded development from your workspace. If you have a solo web application you can use the Maven Jetty plugin, which uses classes and resources directly from Maven source and target project directories. Unfortunately, the Maven Jetty plugin does not support deploying multiple web applications, EJB modules or EARs so in the latter case you’re stuck doing artifact builds.
Session Persistence
Since we’re on the topic of reloading classes, and redeploying involves reinitializing an application, it makes sense to talk about session state. An HTTP session usually holds information like login credentials and conversational state. Losing that session when developing a web application means spending time logging in and browsing to the changes page – something that most web containers have tried to solve by serializing all of the objects in the HttpSession map and then deserializing them in the new classloader. Essentially, they copy all of the session state. This requires that all session attributes implement Serializable (ensuring session attributes can be written to a database or a file for later use), which is not restricting in most cases.
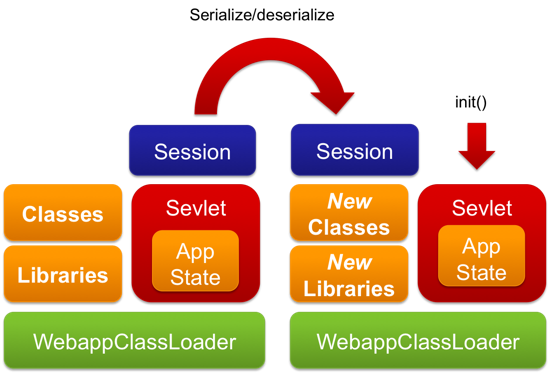
Session persistence has been present in most major containers for many years (e.g. Restart Persistence in Tomcat), but was notoriously absent in Glassfish before v3.
OSGi
There is a lot of misunderstanding surrounding what exactly OSGi does and doesn’t do. If we ignore the aspects irrelevant to the current issue, OSGi is basically a collection of modules each wrapped in its own classloader, which can be dropped and recreated at will. When it’s recreated, the modules are reinitialized exactly the same way a web application is.
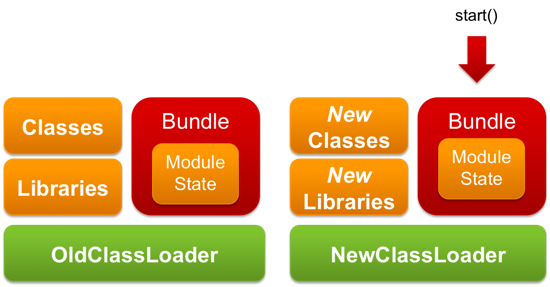
The difference between OSGi and a web container is that OSGi is something that is exposed to your application, that you use to split your application into arbitrarily small modules. Therefore, by design, these modules will likely be much smaller than the monolithic web applications we are used to building. And since each of these modules is smaller and we can 「redeploy」 them one-by-one, re-initialization takes less time. The time depends on how you design your application (and can still be significant).
Tapestry 5, RIFE & Grails
Recently, some web frameworks, such as Tapestry 5, RIFE and Grails, have taken a different approach, taking advantage of the fact that they already need to maintain application state. They’ll ensure that state will be serializable, or otherwise easily re-creatable, so that after dropping a classloader, there is no need to reinitialize anything.
This means that application developers use frameworks’ components and the lifecycle of those components is handled by the framework. The framework will initialize (based on some configuration, either xml or annotation based), run and destroy the components.
As the lifecycle of the components is managed by the framework, it is easy to recreate a component in a new classloader without user intervention and thus create the effect of reloading code. In the background, the old component is destroyed (classloader is dropped) and a new one created (in a new classloader where the classes are read in again) and the old state is either deserialized or created based on the configuration.
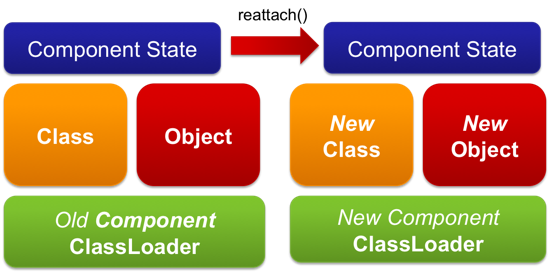
This has the obvious advantage of being very quick, as components are small and the classloaders are granular. Therefore the code is reloaded instantly, giving a smooth experience in developing the application. However such an approach is not always possible as it requires the component to be completely managed by the framework. It also leads to incompatibilities between the different class versions causing, among others, ClassCastExceptions.
We’ve Covered a Lot – and simplified along the way
It’s worth mentioning that using classloaders for code reloading really isn’t as smooth as we have described here – this is an introductory article series. Especially with the more granular approaches (such as frameworks that have per component classloaders, manual classloader dropping and recreating, etc), when you start getting a mixture of older and newer classes all hell can break loose. You can hold all kinds of references to old objects and classes, which will conflict with the newly loaded ones (a common problem is getting a ClassCastException), so watch what you’re doing along the way. As a side note: Groovy is actually somewhat better at handling this, as all calls through the Meta-Object Protocol are not subject to such problems. This article addressed the following questions:
- How are dynamic classloaders used to reload Java classes and applications?
- How do Tomcat, GlassFish (incl v3), and other servers reload Java classes and applications?
- How does OSGi improve reload and redeploy times?
- How do frameworks (incl Tapestry 5, RIFE, Grails) reload Java classes and applications?
Coming up next, we continue our explanation of classloaders and the redeploy process with an investigation into HotSwap and JRebel, two tools used to reduce time spent reloading and redeploying. Stay tuned!
HotSwap and JRebel — Behind the Scenes
HotSwap and Instrumentation
In 2002, Sun introduced a new experimental technology into the Java 1.4 JVM, called HotSwap. It was incorporated within the Debugger API, and allowed debuggers to update class bytecode in place, using the same class identity. This meant that all objects could refer to an updated class and execute new code when their methods were called, preventing the need to reload a container whenever class bytecode was changed. All modern IDEs (including Eclipse, IDEA and NetBeans) support it. As of Java 5 this functionality is also available directly to Java applications, through the java Instrumentation API.
http://java.sun.com/javase/6/docs/technotes/guides/instrumentation/index.html
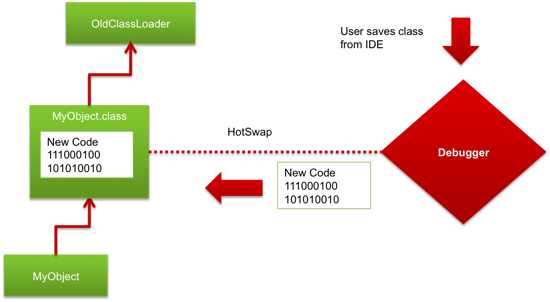
Unfortunately, this redefinition is limited only to changing method bodies — it cannot either add methods or fields or otherwise change anything else, except for the method bodies. This limits the usefulness of HotSwap, and it also suffers from other problems:
- The Java compiler will often create synthetic methods or fields even if you have just changed a method body (e.g. when you add a class literal, anonymous and inner classes, etc).
- Running in debug mode will often slow the application down or introduce other problems
This causes HotSwap to be used less than, perhaps, it should be.
Why is HotSwap limited to method bodies?
This question has been asked a lot during the almost 10 years since the introduction of HotSwap. One of the most voted for bugs for the JVM calls for supporting a whole array of changes, but so far it has not been implemented.
A disclaimer: I do not claim to be a JVM expert. I have a good general idea how the JVM is implemented and over the years I talked to a few (ex-)Sun engineers, but I haven’t verified everything I’m saying here against the source code. That said, I do have some ideas as to the reasons why this bug is still open (but if you know the reasons better, feel free to correct me).
The JVM is a heavily optimized piece of software, running on multiple platforms. Performance and stability are the highest priorities. To support them in different environments the Sun JVM features:
- Two heavily optimized Just-In-Time compilers (-client and -server)
- Several multi-generational garbage collectors
These features make evolving the class schema a considerable challenge. To understand why, we need to look a little closer as to what exactly is necessary to support adding methods and fields (and even more advanced, changing the inheritance hierarchy).
When loaded into the JVM, an object is represented by a structure in memory, occupying a continuous region of memory with a specific size (its fields plus metadata). In order to add a field, we would need to resize that structure, but since nearby regions may already be occupied, we would need to relocate the whole structure to a different region where there is enough free space to fit it in. Now, since we’re actually updating a class (and not just a single object) we would have to do this to every object of that class.
In itself this would not be hard to achieve — Java garbage collectors already relocate objects all the time. The problem is that the abstraction of one 「heap」 is just that, an abstraction. The actual layout of memory depends on the garbage collector that is currently active and, to be compatible with all of them, the relocation should probably be delegated to the active garbage collector. The JVM will also need to be suspended for the time of relocation, so doing GC at the same time makes sense.
Adding a method does not require updating the object structure, but it does require updating the class structure, which is also present on the heap. But consider this: the moment after a class has been loaded it is essentially is frozen forever. This enables the JIT to perform the main optimization that the JVM does — inlining. Most of the method calls in your application hot spots are eliminated and the code is copied to the calling method. A simple check is inserted to ensure that the target object is indeed what we think it is.
Here’s the punchline: the moment we can add methods to classes this 「simple check」 is not enough. We would need a considerably more complicated check that needs to ensure not only that no methods with the same name were added to the target class, but also to all it’s superclasses. Alternatively we could track all the inlined spots and their dependencies and deoptimize them when a class is updated. Either way it has a cost in either performance or complexity.
On top of that, consider that we’re talking about multiple platforms with varying memory models and instructions sets that probably require at least some specific handling and you get yourself an expensive problem with not much return on investment.
Introducing JRebel
In 2007, ZeroTurnaround announced the availability of a tool called JRebel (then JavaRebel) that could update classes without dynamic class loaders and with very few limitations. Unlike HotSwap, which is dependent on IDE integration, the tool works by monitoring the actual compiled .class files on disk and updating the classes whenever the files are updated. This means that you can use JRebel with a text editor and command-line compiler if so willing. Of course, it’s also integrated neatly into Eclipse, IntelliJ, and NetBeans. Unlike dynamic classloaders, JRebel preserves the identity and state of all existing objects and classes, allowing developers to continue using their application without delay.
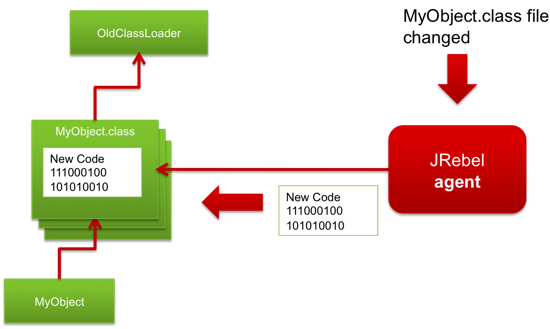
How does this work?
For starters, JRebel works on a different level of abstraction than HotSwap. Whereas HotSwap works at the virtual machine level and is dependent on the inner workings of the JVM, JRebel makes use of two remarkable features of the JVM — abstract bytecode and classloaders. Classloaders allow JRebel to recognize the moment when a class is loaded, then translate the bytecode on-the-fly to create another layer of abstraction between the virtual machine and the executed code.
Others have used this features to enable profilers, performance monitoring, continuations, software transactional memory and even distributed heap. Combining bytecode abstraction with classloaders is a powerful combination, and can be used to implement a variety of features even more exotic than class reloading. As we examine the issue closer, we’ll see that the challenge is not just in reloading classes, but also doing so without a visible degradation in performance and compatibility.
As we reviewed in Reloading Java Classes 101(前面的基础部分) the problem in reloading classes is that once a class has been loaded it cannot be unloaded or changed; but we are free to load new classes as we please. To understand how we could theoretically reload classes, let’s take a look at dynamic languages on the Java platform. Specifically, let’s take a look at JRuby (we’ll simplify a lot, so don’t crucify anyone important).
Although JRuby features 「classes」, at runtime each object is dynamic and new fields and methods can be added at any moment. This means that a JRuby object is not much more than a Map from method names to their implementations and from field names to their values. The implementations for those methods are contained in anonymously named classes that are generated when the method is encountered. If you add a method, all JRuby has to do is generate a new anonymous class that includes the body of that method. As each anonymous class has a unique name there are no issues loading it and as a result the application is updated on-the-fly.
Theoretically, since bytecode translation is usually used to modify the class bytecode, there is no reason why we can’t use the information in that class and just create as many classes as necessary to fulfill its function. We could then use the same transformation as JRuby and split all Java classes into a holder class and method body classes. Unfortunately, such an approach would be subject to (at least) the following problems:
- Perfomance. Such a setup would mean that each method invocation would be subject to indirection. We could optimize, but the application would be at least an order of magnitude slower. Memory use would also skyrocket, as so many classes are created.
- Java SDK classes. The classes in the Java SDK are considerably harder to process than the ones in the application or libraries. Also they often are implemented in native code and cannot be transformed in the 「JRuby」 way. However if we leave them as is, then we’ll cause numerous incompatibility errors, which are likely not possible to work around.
- Compatibility. Although Java is a static language it includes some dynamic features like reflection and dynamic proxies. If we apply the 「JRuby」 transformation none of those features will work unless we replace the Reflection API with our own classes, aware of the transformation.
Therefore, JRebel does not take such an approach. Instead it uses a much more complicated approach, based on advanced compilation techniques, that leaves us with one master class and several anonymous support classes backed by the JIT transformation runtime that allow modifications to take place without any visible degradation in performance or compatibility. It also
- Leaves as many method invocations intact as possible. This means that JRebel minimizes its performance overhead, making it lightweight.
- Avoids instrumenting the Java SDK except in a few places that are necessary to preserve compatibility.
- Tweaks the results of the Reflection API, so that we can correctly include the added/removed members in these results. This also means that the changes to Annotations are visible to the application.
Beyond Class Reloading – Archives
Reloading classes is something Java developers have complained about for a long time, but once we solved it, other problems turned up.
The Java EE standard was developed without much concern for development Turnaround (the time it takes between making a change to code and seeing the effects of that change in an application). It expects that all applications and their modules be packaged into archives (JARs, WARs and EARs), meaning that before you can update any file in your application, you need to update the archive — which is usually an expensive operation involving a build system like Ant or Maven. As we discussed in Reloading Java Classes 301(前面的服务器部分) this can be minimized by using exploded development and incremental IDE builds, but for large application this is commonly not a viable option.
To solve this problem in JRebel 2.x we developed a way for the user to map archived applications and modules back to the workspace — our users create a rebel.xml configuration file in each application and module that tells JRebel where the source files can be found. JRebel integrates with the application server, and when a class or resource is updated it is read from the workspace instead of the archive.
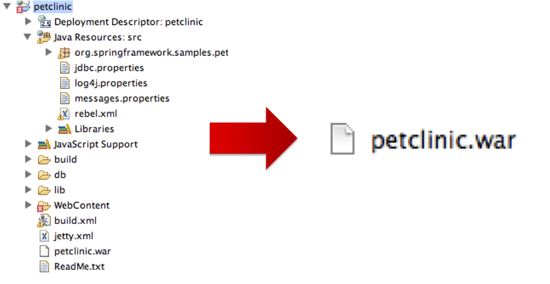
This allows for instant updates of not just classes, but any kind of resources like HTML, XML, JSP, CSS, .properties and so on. Maven users don’t even need to create a rebel.xml file, since our Maven plugin will generate it automatically.
Beyond Class Reloading – Configurations and Metadata
En route to eliminating Turnaround, another issue becomes obvious: Nowadays, applications are not just classes and resources, they are wired together by extensive configuration and metadata. When that configuration changes it should be reflected in the running application. However it’s not enough to make the changes to the configuration files visible, the specific framework must reload it and reflect the changes in the application.
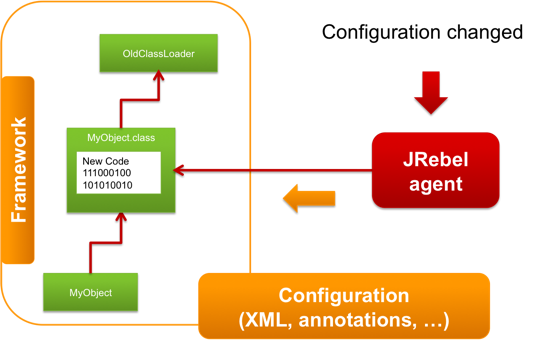
To support these kinds of changes in JRebel we developed an open source API that allows our team and third party contributers to make use of JRebel’s features and propagate changes in configuration to the framework, using framework-specific plugins. E.g. we support adding beans and dependencies in Spring on-the-fly as well as a wide variety of changes in other frameworks.
Conclusions
This article sums up the methods to reload Java classes without dynamic class loaders. We also discuss the reasons for HotSwap’s limitations, how JRebel works behind the scenes and the problems that arise when class reloading is solved.
How Much Does Turnaround Cost?
The Easily-Measurable Cost of Turnaround: Builds and Redeploys
Last year we ran two surveys asking developers how much time they spend building and redeploying their application. Although we’ve been talking with developers about this for a long time, and everyone understands that some amount of time is spent on builds and redeploys, it was still surprising to see the results – including actual numbers of minutes, days, and weeks spent on the process. For example, during an average hour of coding developers spend:
- An average of 6 minutes building the application [Source: The Build Tool Report].
- An average of 10.5 minutes redeploying the application [Source: The Java EE Container Redeploy & Restart Report].
To be fair, there are large deviations on both sides of these averages — the survey data we used only came from 600 and 1100 respondents respectively, and they used a variety of technologies which you can read about in the reports themselves. Some folks don’t spend as much as the averages, while others spend much more, and your project could be anywhere in that range.
Given that, the averages should apply pretty nicely to Java EE development as an industry (with the usual disclaimer of 「lies, damn lies and statistics」). Let’s take a look at an awful scenario — where everyone in the industry is right on the average:
- Build (6 mins) + Redeploy (10.5 mins) = 16.5 minutes per hour of development or 27.5% of coding time
- Assuming that developers only code 5 hours per day x 5 days per week x 48 weeks a year = 1200 coding hours a year
- 1200 hours * 27.5% = 330 hours a year or 330/40 = 8.25 full-time work-weeks a year spent on turnaround, per developer
- Assuming 20 USD/h average salary, this adds up to 330 * 20 = 6600 USD per developer per year [Source: conservative estimation backed by http://www.worldsalaries.org/computerprogrammer.shtml]
- Larry Ellison recently quoted the number of Java developers around the world at 9 million.
If you’d like to work out the time or cash spent annually by the industry on Turnaround, these are some numbers you can start with.
Context Switching
Programming is complicated. In fact it’s so complicated that most people are not capable of doing it. Those who are capable must mentally juggle a lot of context while writing code.. context including specifications, GUI considerations, relevant library calls, relevant application classes, methods and variables and so on.
This information is held in the the working (aka short-term) memory. Since the working memory is not meant for long term storage, switching away from a current task means that you will start losing the context surrounding the code, and then spend time trying to get back into it. The rest of the article will discuss how quickly context is lost, how long it takes to restore it, and what effect it has on the quality of your work.
How quickly does working memory degrade?
In 1959, an article titled, 「Short-Term Retention of Individual Verbal Items」 by L. Peterson and M. Peterson appeared in the Journal of Experimental Psychology [Source: http://www-test.unifr.ch/psycho/site/assets/files/Allg/ExU/Peterson_1959.pdf]. It showed that on average, after only 3 seconds, about half of our working memory is lost. The following graph plots the amount of working memory preserved after every subsequent 3 seconds:
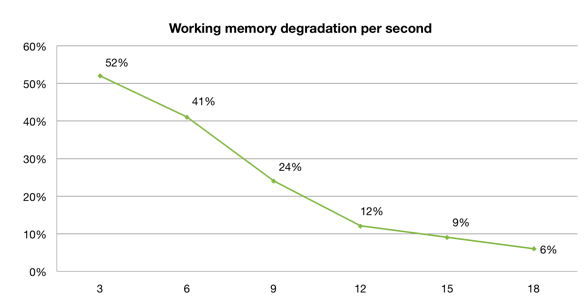
After 15 seconds, less than 10% of the original memory is preserved. While these results may not be directly applicable to the programming context, it is clear that memory degradation occurs after seconds, not minutes. Translated, it means that short distractions cause dramatic losses in working memory.
How long it takes to restore context after an interruption?
Although there’s not a direct answer to that question, going through the relevant literature gives us some clues:
the recovery time after a phone call is at least 15 minutes. If more than 10 interrupts occur during a day, the time between the interrupts becomes too short to accomplish product development work. Rini van Solingen et al, Interrupts: Just a Minute Never Is
To take a call you need to completely switch away from your working environment and focus on the conversation. Other interrupts are less disruptive than that:
Recovering from an email interrupt, and returning to work at the same work rate as before the interrupt — 64 seconds. Thomas Jackson et al, Case Study: Evaluating the Effect of Email Interruptions within the Workplace
Instant message — 11 to 25 seconds. Thomas Jackson, Instant Messaging Implications in the Transition from a Private Consumer Activity to a Communication Tool for Business
FYI – These quotes are not based on software developers, but rather more generic office workers. Take that as you’d like. Since context recovery is a process, it takes some time to get back to maximum speed after an interrupt:
The trouble is, getting into 「the zone」 is not easy. When you try to measure it, it looks like it takes an average of 15 minutes to start working at maximum productivity. [...] The other trouble is that it’s so easy to get knocked out of the zone. Noise, phone calls, going out for lunch, having to drive 5 minutes to Starbucks for coffee, and interruptions by coworkers [...] all knock you out of the zone. Joel Spolsky, Where do These People Get Their (Unoriginal) Ideas?
So what about development Turnaround — should that be considered an interrupt and how much does it add to the cost?
From experience, any pause will cause the working memory to start fading, and longer pauses will cause developers to multi-task (even if the other task is reading Slashdot). This will mean that the context surrounding a particular task is at least partially lost and needs to be restored. A longer pause means more memory degradation, increased likelihood of a task switch, and the assumption that recovery time is also longer. Just to illustrate, let’s assume that it takes 50% of the length of the pause to recover the context after getting back to work. In that case, the total cost of turnaround for a java developer dealing with average build and redeploy delays looks something like:
- 16.5 (mins per hour spent on Build & Redeploy phases) + 50% = 24.75 minutes per hour of development or 41.25% of coding time
- 1200 (coding hours per year) * 41.25% = 495 hours per year spent on Turnaround (divide that by 40 hours per week to get 12.375 full-time work-weeks a year spent on turnaround)
- Assuming a (20 USD)/h average salary this adds up to 495 * 20 = 9900 USD per developer per year
These numbers make a lot of assumptions. I’m not convinced that the average hourly wage of someone reading this blog is $20. I’m also not convinced that these numbers make an air-tight argument — but the point here is: the social cost of Turnaround is more than just the time spent on building, redeploying, & restarting.
Finally, I’m not convinced that developers keep all the code they wrote on a day full of distractions – I get the feeling that long turnaround times, distractions, and interruptions have a negative effect on code quality, and on the mental abilities of other developers. Though we couldn’t find data measuring this specifically, there is some indication that this impact is also not trivial, and I’d like to finish with it:
In a series of tests carried out by Dr Glenn Wilson, Reader in Personality at the Institute of Psychiatry, University of London, an average worker’s functioning IQ falls ten points when distracted by ringing telephones and incoming emails. This drop in IQ is more than double the four point drop seen following studies on the impact of smoking marijuana. Similarly, research on sleep deprivation suggests that an IQ drop of ten points is equal to missing an entire night of sleep. This IQ drop was even more significant in the men who took part in the tests. Dr Glenn Wilson
Many programmers appear to be continually frustrated in attempts to work. They are plagued by noise and interruption, and pessimistic that the situation will ever be improved. The data recorded about actual interruptions supports the view that the so-called 「work-day」 is made up largely of frustration time. T. DeMarco and T. Lister, Programmer performance and the effects of the workplace,
Conclusions
It’s been a long trip from the beginning of the series to this point. We can only hope that we answered some of your questions and maybe posed some new questions to answer. Probably the most important point that we were trying to bring to your attention is that reducing Java turnaround is a complex and expensive problem, which deserves a lot more attention than it’s getting at the moment
What are your thoughts on all this?