JMM与Volatile
JMM分析
volatile可见性实例代码
public class VisibilityTest {
// JMM模型 java线程内存模型
// 可见性 为什么? lock addl $0x0,(%rsp) 触发缓存一致性协议
private volatile boolean flag = true;
public void refresh(){
flag = false;
System.out.println(Thread.currentThread().getName()+"修改flag");
}
public void load(){
System.out.println(Thread.currentThread().getName()+"开始执行.....");
int i=0;
while (flag){
i++;
//TODO
// 不能
// 能
//shortWait(100000);
// 不能 迷 为什么? 缓存是否失效(过期)
//shortWait(10000);
// 能 synchronized 可见性保证 内存屏障
// System.out.println("=====");
// try {
// // 能 sleep 让出cpu时间片
// Thread.sleep(0);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
}
System.out.println(Thread.currentThread().getName()+"跳出循环: i="+ i);
}
public static void main(String[] args){
VisibilityTest test = new VisibilityTest();
new Thread(() -> test.load(), "threadA").start();
try {
Thread.sleep(2000);
new Thread(()->test.refresh(),"threadB").start();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void shortWait(long interval){
long start = System.nanoTime();
long end;
do{
end = System.nanoTime();
}while(start + interval >= end);
}
}
什么是伪共享
查看CPU缓存大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size 64
或者:
$ cat /proc/cpuinfo processor : 0 vendor_id : AuthenticAMD cpu family : 23 model : 1 model name : AMD Ryzen 5 PRO 1600 Six-Core Processor stepping : 1 ... cache_alignment : 64 <-- 缓存大小 ...
Cache Line大小是64Byte(linux下查看缓存行大小)。
如果多个核的线程在操作同一个缓存行中的不同变量数据,那么就会出现频繁的缓存失效, 即使在代码层面看这两个线程操作的数据之间完全没有关系。 这种不合理的资源竞争情况就是伪共享(False Sharing)。
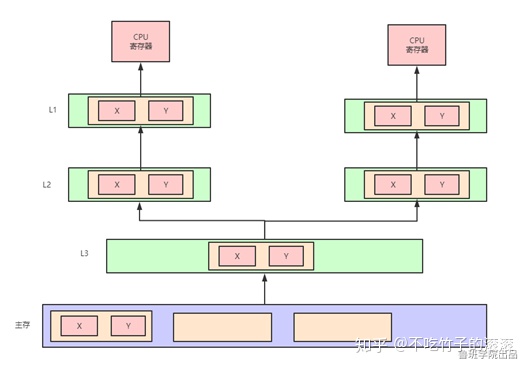
避免伪共享:
- 缓存行填充
-
使用
@sun.misc.Contended注解(java8)
伪共享案例:
public class FalseSharingTest {
public static void main(String[] args) throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer) throws InterruptedException {
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(System.currentTimeMillis() - start);
}
}
class Pointer {
// 避免伪共享: @Contended + jvm参数:-XX:-RestrictContended
//@Contended
volatile long x;
//避免伪共享: 缓存行填充
//long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
}
volatile重排规则
| 能否重排 | 第二个操作 | ||
|---|---|---|---|
| 第一个操作 | 普通读写 | volatile读 | volatile写 |
| 普通读写 | NO | ||
| volatile读 | NO | NO | NO |
| volatile写 | NO | NO | |
结论:
- 第二个操作是volatile写,不管第一个操作是什么都不会重排序
- 第一个操作是volatile读,不管第二个操作是什么都不会重排序
- 第一个操作是volatile写,第二个操作是volatile读,也不会发生重排序
JMM内存屏障插入策略:
- 在每个volatile写操作的前面插入一个StoreStore屏障
- 在每个volatile写操作的后面插入一个StoreLoad屏障
- 在每个volatile读操作的后面插入一个LoadLoad屏障
- 在每个volatile读操作的后面插入一个LoadStore屏障
注意:X86处理器不会对读-读、读-写和写-写操作做重排序, 会省略掉这3种操作类型对应的内存屏障。仅会对写-读操作做重排序,所以volatile写-读操作只需要在volatile写后插入StoreLoad屏障

volatile有序性案例
DCL为什么要使用volatile:
public class SingletonFactory {
private volatile static SingletonFactory myInstance;
public static SingletonFactory getMyInstance() {
if (myInstance == null) {
synchronized (SingletonFactory.class) {
if (myInstance == null) {
myInstance = new SingletonFactory();
}
}
}
return myInstance;
}
public static void main(String[] args) {
SingletonFactory.getMyInstance();
}
}
x、y的值有哪些可能
public class ReOrderTest {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException{
int i=0;
while (true) {
i++;
x = 0; y = 0;
a = 0; b = 0;
/* x,y: */
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
shortWait(20000);
a = 1;
UnsafeFactory.getUnsafe().storeFence();
x = b;
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
b = 1;
UnsafeFactory.getUnsafe().storeFence();
y = a;
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("第" + i + "次(" + x + "," + y + ")");
if (x==0 && y==0){
break;
}
}
}
public static void shortWait(long interval){
long start = System.nanoTime();
long end;
do {
end = System.nanoTime();
} while(start + interval >= end);
}
}
内存屏障
硬件层提供了一系列的内存屏障 memory barrier / memory fence(Intel的提法)来提供一致性的能力。拿X86平台来说,有几种主要的内存屏障:
- lfence,是一种Load Barrier 读屏障
- sfence, 是一种Store Barrier 写屏障
- mfence, 是一种全能型的屏障,具备lfence和sfence的能力
- Lock前缀,Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。 Lock会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁。 它后面可以跟ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG等指令。
内存屏障有两个能力:
- 阻止屏障两边的指令重排序
- 刷新处理器缓存/冲刷处理器缓存
对Load Barrier来说,在读指令前插入读屏障,可以让高速缓存中的数据失效,重新从主内存加载数据
对Store Barrier来说,在写指令之后插入写屏障,能让写入缓存的最新数据写回到主内存
Lock前缀实现了类似的能力,它先对总线和缓存加锁,然后执行后面的指令, 最后释放锁后会把高速缓存中的数据刷新回主内存。在Lock锁住总线的时候, 其他CPU的读写请求都会被阻塞,直到锁释放。
不同硬件实现内存屏障的方式不同,Java内存模型屏蔽了这种底层硬件平台的差异,由JVM来为不同的平台生成相应的机器码。
as-if-serial & happens-before
as-if-serial
as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提高并行度), (单线程)程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序, 因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
double pi = 3.14; // A double r = 1.0; // B double area = pi * r * r; // C
A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中, C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。 但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。
happens-before
从JDK 5 开始,JMM使用happens-before的概念来阐述多线程之间的内存可见性。在JMM中, 如果一个操作执行的结果需要对另一个操作可见, 那么这两个操作之间「必须」存在happens-before关系。 happens-before和JMM关系如下图:
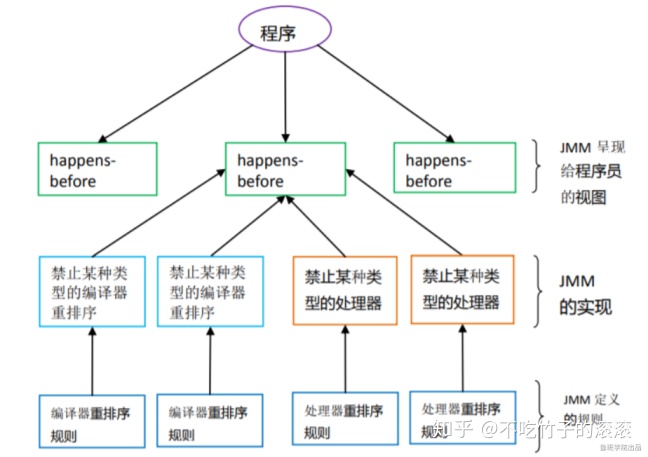
happens-before原则非常重要,它是判断数据是否存在竞争、线程是否安全的主要依据,依靠这个原则, 我们解决在并发环境下两操作之间是否可能存在冲突的所有问题。 下面我们就一个简单的例子稍微了解下happens-before:
i = 1; //线程A执行 j = i ; //线程B执行
j是否等于1呢?假定线程A的操作i = 1happens-before线程B的操作j = i,
那么可以确定线程B执行后j = 1一定成立,如果他们不存在happens-before原则,
那么j = 1不一定成立。这就是happens-before原则的威力。
happens-before原则定义如下:
- 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见, 而且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在happens-before关系,并不意味着一定要按照happens-before 原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行 的结果一致,那么这种重排序并不非法。
下面是happens-before原则规则:
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
- 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作;
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
我们来详细看看上面每条规则(摘自《深入理解Java虚拟机第12章》):
- 程序次序规则:一段代码在单线程中执行的结果是有序的。注意是执行结果,因为虚拟机、处理器会对指令进行重排序(重排序后面会详细介绍)。虽然重排序了,但是并不会影响程序的执行结果,所以程序最终执行的结果与顺序执行的结果是一致的。故而这个规则只对单线程有效,在多线程环境下无法保证正确性。
- 锁定规则:这个规则比较好理解,无论是在单线程环境还是多线程环境,一个锁处于被锁定状态,那么必须先执行unlock操作后面才能进行lock操作。
- volatile变量规则:这是一条比较重要的规则,它标志着volatile保证了线程可见性。通俗点讲就是如果一个线程先去写一个volatile变量,然后一个线程去读这个变量,那么这个写操作一定是happens-before读操作的。
- 传递规则:提现了happens-before原则具有传递性,即A happens-before B , B happens-before C,那么A happens-before C
- 线程启动规则:假定线程A在执行过程中,通过执行ThreadB.start()来启动线程B,那么线程A对共享变量的修改在接下来线程B开始执行后确保对线程B可见。
- 线程终结规则:假定线程A在执行的过程中,通过制定ThreadB.join()等待线程B终止,那么线程B在终止之前对共享变量的修改在线程A等待返回后可见。
上面八条是原生Java满足Happens-before关系的规则,但是我们可以对他们进行推导出其他满足happens-before的规则:
- 将一个元素放入一个线程安全的队列的操作Happens-Before从队列中取出这个元素的操作
- 将一个元素放入一个线程安全容器的操作Happens-Before从容器中取出这个元素的操作
- 在CountDownLatch上的倒数操作Happens-Before CountDownLatch#await()操作
- 释放Semaphore许可的操作Happens-Before获得许可操作
- Future表示的任务的所有操作Happens-Before Future#get()操作
- 向Executor提交一个Runnable或Callable的操作Happens-Before任务开始执行操作
这里再说一遍happens-before的概念:如果两个操作不存在上述(前面8条 + 后面6条) 任一一个happens-before规则,那么这两个操作就没有顺序的保障, JVM可以对这两个操作进行重排序。如果操作A happens-before操作B, 那么操作A在内存上所做的操作对操作B都是可见的。
下面就用一个简单的例子来描述下happens-before原则:
private int i = 0;
public void write(int j ){
i = j;
}
public int read(){
return i;
}
我们约定线程A执行write(),线程B执行read(),且线程A优先于线程B执行, 那么线程B获得结果是什么?;我们就这段简单的代码一次分析happens-before的规则 (规则5、6、7、8 + 推导的6条可以忽略,因为他们和这段代码毫无关系):
- 由于两个方法是由不同的线程调用,所以肯定不满足程序次序规则;
- 两个方法都没有使用锁,所以不满足锁定规则;
- 变量i不是用volatile修饰的,所以volatile变量规则不满足;
- 传递规则肯定不满足;
所以我们无法通过happens-before原则推导出线程A happens-before线程B, 虽然可以确认在时间上线程A优先于线程B指定,但是就是无法确认线程B获得的结果是什么, 所以这段代码不是线程安全的。那么怎么修复这段代码呢?满足规则2、3任一即可。
happens-before原则是JMM中非常重要的原则,它是判断数据是否存在竞争、 线程是否安全的主要依据,保证了多线程环境下的可见性。