Java函数式编程:Stream API 与 多线程
Stream API
惰性求值 VS 及早求值
Stream 中存在两类方法,
- 不产生值的方法称为惰性方法;
- 从 Stream 中产生值的方法叫做及早求值方法。
判断一个方法的类别很简单:
- 如果返回值是 Stream,那么就是惰性方法;
- 如果返回值是另一个值或为空,那么就是及早求值方法。
惰性方法返回的 Stream 对象不是一个新的集合,而是创建新集合的配方, Stream 本身不会做任何迭代操作,只有调用及早求值方法时,才会开始真正的迭代。
整个过程与 Builder 模式有共通之处,惰性方法负责对 Stream 进行装配 (设置 builder 的属性),调用及早求值方法时(调用 builder 的 build 方法), 按照之前的装配信息进行迭代操作。
有限流
列表转变为流
Collection.stream()或parallelStream()把集合类转为流或并行流:
final List<Dish> dishes = Arrays.asList(
new Dish("pork" , false, 800, Type.MEAT ),
new Dish("beef" , false, 700, Type.MEAT ),
new Dish("chicken" , false, 400, Type.MEAT ),
new Dish("french fries", true , 530, Type.OTHER),
new Dish("rice" , true , 350, Type.OTHER),
new Dish("season fruit", true , 120, Type.OTHER),
new Dish("pizza" , true , 550, Type.OTHER),
new Dish("prawns" , false, 300, Type.FISH ),
new Dish("salmon" , false, 450, Type.FISH ));
Stream<Dish> names = dishes.stream();
流聚合为容器
Stream.collect()可以把流转为集合:
// toList List<String> names = dishes.stream().map(Dish::getName).collect(toList()); // toSet 可以去重复。 Set<Type> types = dishes.stream().map(Dish::getType).collect(Collectors.toSet()); // toMap // 注意, 这个demo是一个坑,不可以这样用!!!, 请使用toMap(Function, Function, BinaryOperator)) Map<Type, Dish> byType = dishes.stream().collect(toMap(Dish::getType, d -> d)); Map<String, Student> map1 = list.stream().collect( Collectors.toMap(Student::getId, student -> student)); Map<String, Integer> map2 = list.stream().collect( Collectors.toMap(Student::getId, student -> student.getAge()));
其实collect()类似于MapReduce,可以把流处理为任何需要的类型,比如String:
String join1 = dishes.stream().map(Dish::getName).collect(Collectors.joining());
String join2 = dishes.stream().map(Dish::getName).collect(Collectors.joining(", "));
上面几个几乎是最常用的收集器了,也基本够用了。但作为初学者来说,理解需要时间。
想要真正明白为什么这样可以做到收集,就必须查看内部实现,可以看到,
这几个收集器都是基于java.util.stream.Collectors.CollectorImpl
stream()方法把集合转为流,collect()方法把流转为集合:
String collect =
Arrays.asList("abc", "eqwr", "bcd", "qb" , "ehdc", "jk")
.stream()
.map(x -> x.toUpperCase())
.collect(Collectors.joining(", "));
System.out.printf("filtered list : %s %n", collect);
String collect2 = Stream.of("abc", "eqwr", "bcd", "qb" , "ehdc", "jk")
.map(x -> x.toUpperCase())
.collect(Collectors.joining(", "));
System.out.printf("filtered list : %s %n", collect2);
collect(toList())方法由Stream里面的值生成一个列表,是一个及早求值操作。
collect 的功能不仅限于此,它是一个非常强大的结构。
@Data class User{
private String name;
}
public List<String> getNames(List<User> users){
List<String> names = new ArrayList<>();
for (User user : users){
names.add(user.getName());
}
return names;
}
public List<String> getNamesUseStream(List<User> users){
// 方法引用
//return users.stream().map(User::getName).collect(toList());
// lambda表达式
return users.stream().map(user -> user.getName()).collect(toList());
}
无限流
流是惰性的,分为中间操作和终止操作,在执行终止操作之前,流的遍历不会开始, 基于这一特性,才可以使用无限流。使用无限流,需要正确地限制长度(limit)。
无限流的两种生成方式:迭代(Iterate)与生产(Supplier)
所有流操作分为中间操作与终止操作两类,并被组合为管道流形式。 管道流由源(比如集合、数组,生成器函数,I/O channel,无限序列生成器), 接着是零个或多个中间操作和一个终止操作。
中间操作与终止操作
中间操作只有终止操作执行时才执行。它们以管道流形式直播执行, 可以通过下列方法加入管道流:
-
filter() -
map() -
flatMap() -
distinct() -
sorted() -
peek() -
limit() -
skip()
所有中间操作是懒执行,即直到实际需要处理结果时才会执行。 执行中间操作实际上并不执行任何操作,而是创建一个新的流,当遍历该流时, 它包含与给定谓词匹配的原始流的元素。因此在执行管道的终止操作之前, 流的遍历不会开始。
这是非常重要的特性, 对于无限流尤其重要——因为它允许我们创建只有在调用终止操作时才实际调用的流。
终止操作可以遍历流生成结果或直接消费。终止操作执行后, 可以认为管道流被消费了并不能再被使用。几乎在所有情况下,终端操作都是立即执行的, 在返回之前完成对数据源的遍历和对管道的处理。
终止操作的立即性对无限流是重要概念,因为在处理时我们需要仔细考虑流是否被正确限制
(例如limit()函数)。终止操作有:
-
forEach() -
forEachOrdered() -
toArray() -
reduce() -
collect() -
min() -
max() -
count() -
anyMatch() -
allMatch() -
noneMatch() -
findFirst() -
findAny()
每个这些操作都会触发所有的中间操作。
创造无限流
无限流的两种生成方式:迭代(Iterate)与生产(Supplier)
通过迭代创建流
iterate():接收一个初始元素seed,生成从seed到f的迭代流
-
seed:初始元素 -
f:UnaryOperator函数式接口,接收T类型参数,调用apply()后返回T本身, 应用于上一个元素以产生新元素
public static Stream iterate(final T seed, final UnaryOperator f);
eg:创建一个从0开始,每次加2的无限流,并限制收集前十个元素:
List list = Stream.iterate(0, c -> c + 2) .limit(10) .collect(Collectors.toList()); // output:[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
eg:相当于:
Stream<Integer> infiniteStream = Stream.iterate(0, i -> i + 2); List<Integer> collect = infiniteStream .limit(10) .collect(Collectors.toList());
eg:斐波那契数列,从[0, 1]开始,下一个元素是前两个元素之和,
并限制收集前十个数组中的首元素:
Stream // 生成流,元素为两个相邻数字的数组
// 例:[0, 1],[1, 1], [1, 2], [2, 3], [3, 5], ....
.iterate(new int[] { 0, 1 }, t -> new int[] { t[1], t[0] + t[1] })
// 把数组的流转为数字的流:每一项只取数组中的第一个元素
.map(arr -> arr[0])
.limit(10) // 指定取的元素数量。
.forEach(x -> System.out.println(x)); // 打印出来
// 同样的逻辑,但这次不是打印而是聚合成List
List list = Stream.iterate(
new Integer[]{0, 1}, c -> new Integer[]{c[1], c[0] + c[1]})
.map(c -> c[0]).limit(10).collect(Collectors.toList());
通过生产者创建流
generate():接收一个Supplier函数式接口作为参数,生成迭代流
public static Stream generate(Supplier s) {};
-
s:Supplier函数式接口,生产者,返回T
并在调用终止操作之前调用限制方法。
在collect()终止方法之前使用limit()方法很重要,否则程序无限执行。
eg:生成十个随机数:
Stream // random num .generate(Math::random) .limit(10) // 指定取的元素数量。 .forEach(x -> System.out.println(x)); // 打印出来 // 同样的逻辑,不打印而是聚合成list List list = Stream.generate(Math::random) .limit(10) .collect(Collectors.toList());
eg:创建一个随机UUID的无限流:
Supplier<UUID> randomUUIDSupplier = UUID::randomUUID; Stream<UUID> infiniteStreamOfRandomUUID = Stream.generate(randomUUIDSupplier); List<UUID> randomInts = infiniteStreamOfRandomUUID .skip(10) .limit(10) .collect(Collectors.toList());
创建长度未知的流
很多情况下要用流去操作长度未知的数据。比如数据库查询结果、 网络请求的数据。
要把这些长度未知的数据包装成流,基本思路是先创建一个无限的流, 但在每次生成下一个元素前,判断一下数据是否已经读完。
方法一:通过迭代器(Iterator)包装流
自己实现一个迭代器,在迭代器里判断是不是已经读完数据:
// 自定义迭代器,定义结束条件与如何生成下一个元素
Iterator<Integer> it = new Iterator<Integer>() {
// 迭代标记
int counter = 0;
@Override
public boolean hasNext() {
// 指定终止条件
return counter < 10;
}
@Override
public Integer next() {
counter++;
return (int) (Math.random() * 100);
}
};
// 通过迭代器创建生成器
Spliterator<Integer> sp = Spliterators.spliteratorUnknownSize(
it, Spliterator.IMMUTABLE);
// 通过生成器创建流
StreamSupport.stream(sp, false)
.forEach(x -> System.out.println(x)); // 打印出元素
另一个例子,把一个无法迭代的org.json.JSONArray转为Stream<JSONObject>流:
package my.sample
import java.util.Iterator;
import java.util.Spliterator;
import java.util.Spliterators;
import java.util.stream.Stream;
import java.util.stream.StreamSupport;
import java.util.concurrent.atomic.AtomicInteger;
import org.json.JSONArray;
import org.json.JSONObject;
public class MySample {
// 把一个无法迭代的`org.json.JSONArray`转为`Stream<JSONObject>`流
public static Stream<JSONObject>
transJsonArray2JsonStream(JSONArray jsonArr)
{
return StreamSupport.stream(
Spliterators.spliteratorUnknownSize(
new JsonArrayIterator(jsonArr),
Spliterator.IMMUTABLE), // 指定内容不可变
false); // 指定这个流是不能并行处理流
}
}
class JsonArrayIterator implements Iterator<JSONObject> {
private JSONArray jsonArr; // 数据源是 JSONArray
// 记录当前迭代到第几个元素
// 是否有必要用线程安全的类?
// 上面另一个类中创建流时指定了不能并行的流
// 那应该没有必要用AtomicInteger
// 迭代器也不可能线程安全。
// 一个线程中`hasNext()`确认已经取完了,另一个线程可能先取掉。
// private AtomicInteger idx = new AtomicInteger(0);
private int idx = 0;
public JsonArrayIterator(JSONArray jsonArr) {
this.jsonArr = jsonArr;
}
@Override
public boolean hasNext() {
// 数据为空或遍历完了数据源就返回终止
return null != jsonArr && idx < jsonArr.length();
}
@Override
public JSONObject next() {
// 按标记取出下一个元素
return jsonArr.getJSONObject(idx++);
}
}
方法二:定义Spliterator
See JavaDoc on:
https://docs.oracle.com/javase/8/docs/api/java/util/Spliterator.html
例子:
public class GeneratingSpliterator<T> implements Spliterator<T>
{
private Supplier<T> supplier;
private Predicate<T> predicate;
public GeneratingSpliterator(final Supplier<T> newSupplier, final Predicate<T> newPredicate)
{
supplier = newSupplier;
predicate = newPredicate;
}
@Override
public int characteristics()
{
return 0;
}
@Override
public long estimateSize()
{
return Long.MAX_VALUE;
}
@Override
public boolean tryAdvance(final Consumer<? super T> action)
{
T newObject = supplier.get();
boolean ret = predicate.test(newObject);
if(ret) action.accept(newObject);
return ret;
}
@Override
public Spliterator<T> trySplit()
{
return null;
}
}
方法三:Java 9中新Stream.iterate()方法
Java 9中对Stream.iterate()进行了增强,可接受谓词(判断条件)
作为第二个参数判断流是否结束:
Stream.iterate( 1, // 起始元素 n -> n < 10, // 结束条件 n -> n * 2) // 生成下一个元素元素
Stream的collect操作
Stream自带的API里有两种常用的collect()方法:
使用Collector类汇总:
<R, A> R collect(Collector<? super T, A R> collector);
使用函数汇总:
<R> R collect( Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner)
使用Collector汇总
joining()方法:
String [] arr = {"aa", "bb", "cc"};
System.out.println(Arrays.stream(arr).collect(Collectors.joining()));
System.out.println(Arrays.stream(arr).collect(Collectors.joining("|")));
System.out.println(Arrays.stream(arr).collect(Collectors.joining(",", "{", "}")));
汇总为集合容器:
System.out.println(Arrays.stream(arr).collect(Collectors.toList()));
按成员的部分汇总:
class TokeRec {
private long id;
private int size;
}
List<TokeRec> ll = new ArrayList<AccountAndConfigService.TokeRec>();
Map<Integer, Long> recGroupMap = ll.stream().collect(
Collectors.groupingBy(TokeRec::getSize, Collectors.counting()));
使用函数汇总
<R> R collect( Supplier<R> supplier , // 生成目标实例 BiConsumer<R, ? super T> accumulator, // 累计每一项到容器中 BiConsumer<R, R> combiner ) // 把多个生成的目标整合到一起
比如按ID汇总的例子:
Map<Long, TokeRec> recGroupId = ll.stream().collect( () -> new HashMap<Long, TokeRec>(), (m , p ) -> m.put(p.getId(), p), (m1, m2) -> m1.putAll(m2));
可以简化为:
Map<Long, TokeRec> recGroupId2 = ll.stream().collect( HashMap::new, (map , p ) -> map.put(p.getId(), p), Map::putAll);
Stream常用操作
自定义归约reducing
前面几个都是reducing工厂方法定义的归约过程的特殊情况,其实可以用Collectors.reducing创建收集器。比如,求和
Integer totalCalories = dishes.stream().collect(reducing(0, Dish::getCalories, (i, j) -> i + j)); Integer totalCalories2 = dishes.stream().collect(reducing(0, Dish::getCalories, Integer::sum));
当然也可以直接使用reduce
Optional<Integer> totalCalories3 = dishes.stream().map(Dish::getCalories).reduce(Integer::sum);
虽然都可以,但考量效率的话,还是要选择下面这种
int sum = dishes.stream().mapToInt(Dish::getCalories).sum();
reducing
关于reducing的用法比较复杂,目标在于把两个值合并成一个值。
public static <T, U>
Collector<T, ?, U> reducing(
U identity, // 初始值
Function<? super T, ? extends U> mapper, // mapper方法
BinaryOperator<U> op) // 合并操作
reducing还有一个重载的方法,可以省略第一个参数,意义在于把Stream里的第一个参数当做初始值:
public static <T> Collector<T, ?, Optional<T>>
reducing(BinaryOperator<T> op)
先看返回值的区别,T表示输入值和返回值类型,即输入值类型和输出值类型相同。还有不同的就是Optional了。这是因为没有初始值,而第一个参数有可能是null,当Stream的元素是null的时候,返回Optional就很意义了。
再看参数列表,只剩下BinaryOperator。BinaryOperator是一个三元组函数接口,目标是将两个同类型参数做计算后返回同类型的值。可以按照1>2? 1:2来理解,即求两个数的最大值。求最大值是比较好理解的一种说法,你可以自定义lambda表达式来选择返回值。那么,在这里,就是接收两个Stream的元素类型T,返回T类型的返回值。用sum累加来理解也可以。
Collectors.collectingAndThen()
Collectors.collectingAndThen() 函数应该最像 map and reduce 了,它可接受两个参数,第一个参数用于 reduce 操作,而第二参数用于 map 操作。
也就是,先把流中的所有元素传递给第二个参数,然后把生成的集合传递给第一个参数来处理。
例如下面的代码,先把 [1,2,3,4] 这个集合传递给s-> s*slambda 表达式,
计算得出结果为[1,4,9,16],然后再把[1,4,9,16]传递给v->v*2表达式,
计算得出[2,8,18,32],然后传递给Collectors.averagingLong()计算得到结果为
25.0
package cn.twle..util.stream;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class CollectingAndThenExample {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1,2,3,4);
Double result = list.stream().collect(
Collectors.collectingAndThen(
Collectors.averagingLong(v->v*2),
s-> s*s));
System.out.println(result);
}
}
https://segmentfault.com/a/1190000040465075
数值统计:count、max、min
Stream 上最常用的操作之一就是求总数、最大值和最小值,count、max 和 min 足以解决问题。
都是及早求值方法:
min 和 max 入参是一个 Comparator 对象,用于元素之间的比较,
返回值是一个Optional<T>,它代表一个可能不存在的值,
通过get方法可以获取 Optional 中的值。
public Long getCount(List<User> users){
return users.stream()
.filter(user -> user != null)
.count();
}
// 求最小年龄
public Integer getMinAge(List<User> users){
return users.stream()
.map(user -> user.getAge())
.min(Integer::compareTo)
.get();
}
// 求最大年龄
public Integer getMaxAge(List<User> users){
return users.stream()
.map(user -> user.getAge())
.max(Integer::compareTo)
.get();
}
计算最值和平均值
IntStream、LongStream 和 DoubleStream 等流的类中,
有个非常有用的方法叫做 summaryStatistics() 。可以返回 IntSummaryStatistics、
LongSummaryStatistics 或者 DoubleSummaryStatistic s,描述流中元素的各种摘要数据。
在本例中,我们用这个方法来计算列表的最大值和最小值。
它也有 getSum()和getAverage()方法来获得列表的所有元素的总和及平均值。
//获取数字的个数、最小值、最大值、总和以及平均值
List<Integer> primes = Arrays.asList(2, 3, 5, 7, 11, 13, 17, 19, 23, 29);
IntSummaryStatistics stats = primes.stream().mapToInt(
(x) -> x).summaryStatistics();
System.out.println("Highest prime number in List : " + stats.getMax());
System.out.println("Lowest prime number in List : " + stats.getMin());
System.out.println("Sum of all prime numbers : " + stats.getSum());
System.out.println("Average of all prime numbers : " + stats.getAverage());
findAny、findFirst
及早求值方法: 两个函数都以Optional为返回值,用于表示是否找到。
public Optional<User> getAnyActiveUser(List<User> users){
return users.stream()
.filter(user -> user.isActive())
.findAny();
}
public Optional<User> getFirstActiveUser(List<User> users){
return users.stream()
.filter(user -> user.isActive())
.findFirst();
}
allMatch、anyMatch、noneMatch
及早求值方法: 均以 Predicate 作为输入参数,对集合中的元素进行判断,并返回最终的结果。
// 所有用户是否都已激活 boolean allMatch = users.stream().allMatch(user -> user.isActive()); // 是否有激活用户 boolean anyMatch = users.stream().anyMatch(user -> user.isActive()); // 是否所有用户都没有激活 boolean noneMatch = users.stream().noneMatch(user -> user.isActive());
forEach
及早求值: 以 Consumer 为参数,对 Stream 中复合条件的对象进行操作。
public void printActiveName(List<User> users){
users.stream()
.filter(user -> user.isActive())
.map(user -> user.getName())
.forEach(name -> System.out.println(name));
}
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
// 直接打印
list.forEach(System.out::println);
// 取值分别操作
list.forEach(i -> {
System.out.println(i * 3);
});
reduce
及早求值方法: reduce函数,用来将值进行合并,map和reduce是函数式编程的核心。 reduce 操作可以实现从一组值中生成一个值,之前提到的 count、min、max 方法因为比较通用,单独提取成方法,事实上,这些方法都是通过 reduce 完成的。
Integer integer = Arrays.asList(1, 2, 3) .stream() .map((i) -> i = i * 3) .reduce((sum, count) -> sum += count) // 整数类型的默认的不动点是0 .get(); System.out.println(integer); Integer integer2 = Arrays.asList(1, 2, 3) .stream() .map((i) -> i = i * 3) .reduce(0, (sum, count) -> sum += count); System.out.println(integer2);
reduce的更多用法:
// 字符串连接,concat = "ABCD"
String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);
// 求最小值,minValue = -3.0
double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(
Double.MAX_VALUE, Double::min);
// 求和,sumValue = 10, 有起始值
int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);
// 求和,sumValue = 10, 无起始值
sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();
// 过滤,字符串连接,concat = "ace"
concat = Stream.of("a", "B", "c", "D", "e", "F").filter(
x -> x.compareTo("Z") > 0).reduce("", String:concat);
过滤 filter
惰性求值方法:
过滤是Java开发者在大规模集合上的一个常用操作,
而现在使用lambda表达式和流API过滤大规模数据集合是惊人的简单。
流提供了一个filter()方法,接受一个 Predicate 对象,
即可以传入一个lambda表达式作为过滤逻辑。下面的例子是用lambda表达式过滤Java集合,
将帮助理解。
public List<User> getActiveUser(List<User> users){
return users.stream()
.filter(user -> user.isActive())
.collect(toList());
}
List<String> strList = Arrays.asList(
"abc", "eqwr", "bcd", "qb" , "ehdc", "jk");
List<String> filtered = strList.stream().filter(
x -> x.length()> 2).collect(Collectors.toList());
System.out.printf("Original List : %s, filtered list : %s %n",
strList, filtered);
映射函数 map
及早求值方法:
以 Function 作为参数,将 Stream 中的元素从一种类型转换成另外一种类型。
List<Integer> list = Arrays.asList(1, 2, 3); // 可改变对象 list.stream().map((i) -> i * 3).forEach(System.out::println); // 不可改变原有对象 list.forEach(i -> i = i * 3); list.forEach(System.out::println);
peek
Stream 提供的是内迭代,有时候为了功能调试,需要查看每个值, 同时能够继续操作流,这时就会用到 peek 方法。
public void printActiveName(List<User> users){
users.stream()
.filter(user -> user.isActive())
.peek(user -> System.out.println(user.isActive()))
.map(user -> user.getName())
.forEach(name -> System.out.println(name));
}
使用distinct进行去重
List<Integer> numbers = Arrays.asList(9, 10, 3, 4, 7, 3, 4);
List<Integer> distinct = numbers.stream().map(
i -> i*i).distinct().collect(Collectors.toList());
System.out.printf("Original List : %s, Square Without duplicates : %s %n",
numbers, distinct);
takeWhile()和dropWhile()
var upList = List.of( "刘能", "赵四", "谢广坤" );
// 从集合中依次删除满足条件的元素,直到不满足条件为止
var upListSub1 = upList.stream()
.dropWhile(item -> item.equals("刘能"))
.collect(Collectors.toList() );
System.out.println(upListSub1); // 打印 [赵四, 谢广坤]
// 从集合中依次获取满足条件的元素,知道不满足条件为止
var upListSub2 = upList.stream()
.takeWhile(item -> item.equals("刘能"))
.collect(Collectors.toList());
System.out.println( upListSub2 ); // 打印 [刘能]
其他
- sorted:进行排序操作
- limit:限定结果输出数量
- skip:跳过 n 个结果,从 n+1 开始输出
Optional类型
Optional 对象相当于值的容器,而该值可以通过 get 方法获取, 同时 Optional 提供了很多函数用于对值进行操作, 从而最大限度的避免 NullPointerException 的出现。
Optional 与 Stream 的用法基本类型,所提供的方法同样分为惰性和及早求值两类, 惰性方法主要用于流程组装,及早求值用于最终计算。
of
使用工厂方法 of,可以从一个值中创建一个 Optional 对象,如果值为 null,会报 NullPointerException。
Optional<String> dataOptional = Optional.of("a");
String data = dataOptional.get(); // data is "a"
Optional<String> dataOptional = Optional.of(null);
String data = dataOptional.get(); // throw NullPointerException
empty
工厂方法 empty,可以创建一个不包含任何值的 Optional 对象。
Optional<String> dataOptional = Optional.empty(); String data = dataOptional.get(); //throw NoSuchElementException
ofNullable
工厂方法 ofNullable,可将一个空值转化成 Optional。
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}
get、orElse、orElseGet、orElseThrow
直接求值方法,用于获取 Optional 中值,避免空指针异常的出现。
Optional<String> dataOptional = Optional.of("a");
dataOptional.get(); // 获取Optional中的值, 不存在会抛出NoSuchElementException
dataOptional.orElse("b"); //获取Optional中的值,不存在,直接返回"B"
dataOptional.orElseGet(()-> String.valueOf(System.currentTimeMillis())); //获取Optional中的值,不存在,对Supplier进行计算,并返回计算结果
dataOptional.orElseThrow(()-> new XXXException()); //获取Optional中的值,不存在,抛出自定义异常
isPresent、ifPresent
直接求值方法,isPresent 用于判断 Optional 中是否有值,ifPresent 接收 Consumer 对象,当 Optional 有值的情况下执行。
Optional<String> dataOptional = Optional.of("a");
String value = null;
if (dataOptional.isPresent()){
value = dataOptional.get();
} else {
value = "";
}
//等价于
String value2 = dataOptional.orElse("");
// 当Optional中有值的时候执行
dataOptional.ifPresent(v->System.out.println(v));
map
惰性求值方法。map 与 Stream 中的用法基本相同,用于对 Optional 中的值进行映射处理,从而避免了大量 if 语句嵌套,多个 map 组合成链, 只需对最终的结果进行操作,中间过程中如果存在 null 值,之后的 map 不会执行。
@Data
static class Order{
private Name owner;
}
@Data
static class User{
private Name name;
}
@Data
static class Name{
String firstName;
String midName;
String lastName;
}
private String getFirstName(Order order){
if (order == null){
return "";
}
if (order.getOwner() == null){
return "";
}
if (order.getOwner().getFirstName() == null){
return "";
}
return order.getOwner().getFirstName();
}
private String getFirstName(Optional<Order> orderOptional){
return orderOptional.map(order -> order.getOwner())
.map(user->user.getFirstName())
.orElse("");
}
filter
惰性求值,对 Optional 中的值进行过滤,如果 Optional 为 empty,直接返回 empty; 如果 Optional 中存在值,则对值进行验证,验证通过返回原 Optional, 验证不通过返回 empty。
public Optional<T> filter(Predicate<? super T> predicate) {
Objects.requireNonNull(predicate);
if (!isPresent())
return this;
else
return predicate.test(value) ? this : empty();
}
结合Either类型处理Stream流
可能有两种类型的容器Either
设计一种Either类型可能存两种类型。这很有用,比如处理流里的每一个元素时, 可能有的元素能正常处理,有的元素就是异常结果。
import java.util.Optional;
import java.util.function.Function;
import java.util.function.Predicate;
public interface Either<L, R> {
public boolean isLeft();
public boolean isRight();
public Optional<L> getLeft();
public Optional<R> getRight();
public <T, K> Either<T, K> map(Function<L, ? extends T> leftFunc, Function<R, ? extends K> rightFunc);
public boolean isMatch(Predicate<L> leftFunc, Predicate<R> rightFunc);
}
内容可能是Left或是Right两种类型中的一种,因为Right也有正常的含意,
Left有剩下的含意,所以一般用Right存正常的结果,Left存错误的结果:
import java.util.Optional;
import java.util.function.Function;
import java.util.function.Predicate;
public class Left<L, R> implements Either<L, R> {
private L value;
public Left(L value) {
this.value = value;
}
public static <L, R> Left<L, R> ofLeft(L value) {
return new Left<L, R>(value);
}
@Override
public boolean isLeft() {
return true;
}
@Override
public boolean isRight() {
return false;
}
@Override
public Optional<L> getLeft() {
return Optional.of(value);
}
@Override
public Optional<R> getRight() {
return Optional.empty();
}
@Override
public <T, K> Either<T, K> map(
Function<L, ? extends T> leftFunc,
Function<R, ? extends K> rightFunc)
{
T newValue = leftFunc.apply(value);
return new Left<T, K>(newValue);
}
@Override
public boolean isMatch(Predicate<L> leftFunc, Predicate<R> rightFunc) {
return leftFunc.test(value);
}
}
import java.util.Optional;
import java.util.function.Function;
import java.util.function.Predicate;
public class Right<L, R> implements Either<L, R> {
private final R value;
private Right(R value) {
this.value = value;
}
public static <L, R> Right<L, R> ofRight(R value) {
return new Right<L, R>(value);
}
@Override
public boolean isLeft() {
return false;
}
@Override
public boolean isRight() {
return true;
}
@Override
public Optional<L> getLeft() {
return Optional.empty();
}
@Override
public Optional<R> getRight() {
return Optional.of(value);
}
@Override
public <T, K> Either<T, K> map(
Function<L, ? extends T> leftFunc,
Function<R, ? extends K> rightFunc)
{
K newValue = rightFunc.apply(value);
return new Right<T, K>(newValue);
}
@Override
public boolean isMatch(Predicate<L> leftFunc, Predicate<R> rightFunc) {
return rightFunc.test(value);
}
}
可能产生不同的结果
有些操作会生成不同的类型结果。比如除法操作的结果可能是一个数值, 也有可能是一个除以0的异常:
Stream<Either<Exception, Integer>> eiStm = Arrays.asList(
3, 2, 4, 0, 7, 1, 5, 0, 0
).stream()
.map(d -> {
Either<Exception, Integer> tk = null;
try {
tk = Right.ofRight(999999 / d); // 一般情况下是数值,但除以0有异常
} catch (Exception e) {
tk = Left.ofLeft(e); // 结果是异常
}
return tk; });
这样就在结果的流里同时保存了正常的结果与异常的信息。
把不同类型的元素分开
正常结果和异常信息混在一起不好处理,最后还是要把两种不同元素分开。
所以定义一个BinList类把可能有两种结果的类型给分成两份:
import java.util.LinkedList;
import java.util.List;
import java.util.Optional;
public class BinList<L, R> {
private final List<L> leftList;
private final List<R> rightList;
public BinList() {
this.leftList = new LinkedList<L>();
this.rightList = new LinkedList<R>();
}
public BinList(List<L> leftList, List<R> rightList) {
this.leftList = leftList;
this.rightList = rightList;
}
/**
* @return the leftList
*/
public List<L> getLeftList() {
return leftList;
}
/**
* @return the rightList
*/
public List<R> getRightList() {
return rightList;
}
public void append(Either<L, R> o) {
if (o.isLeft()) {
Optional<L> l = o.getLeft();
if (null != l && l.isPresent()) {
this.getLeftList().add(l.get());
}
} else if (o.isRight()) {
Optional<R> r = o.getRight();
if (null != r && r.isPresent()) {
this.getRightList().add(r.get());
}
}
}
public void appendLeft(L left) {
this.getLeftList().add(left);
}
public void appendRight(R right) {
this.getRightList().add(right);
}
public BinList<L, R> appendAll(BinList<L, R> other) {
BinList<L, R> result = new BinList<L, R>();
result.getLeftList().addAll(this.getLeftList());
result.getRightList().addAll(this.getRightList());
result.getLeftList().addAll(other.getLeftList());
result.getRightList().addAll(other.getRightList());
return result;
}
@Override
public String toString() {
return "BinList [leftList=" + leftList + ", rightList=" + rightList + "]";
}
}
效果:
List<Either<Integer, String>> bbList = Arrays.asList(
Right.ofRight("aaa"), Left .ofLeft ( 111 ),
Right.ofRight("bbb"), Left .ofLeft ( 222 ),
Right.ofRight("ccc"), Left .ofLeft ( 333 ));
BinList<Integer,String> bList = bbList.stream().collect(
( ) -> new BinList<Integer,String>(),
(bl, o ) -> bl.append(o),
(l1, l2) -> l1.appendAll(l2));
System.out.println(bList);
// 输出:BinList [leftList=[111, 222, 333], rightList=[aaa, bbb, ccc]]
可以简写为:
bList = bbList.stream().collect( BinList<Integer,String>::new, (bl, o) -> bl.append(o), BinList<Integer,String>::appendAll);
例子,还是处理除法操作中的除以0异常:
BinList<Exception, Integer> ieBlst =
Arrays.asList(3, 2, 4, 0, 7, 1, 5, 0, 0).stream()
.map(d -> {
Either<Exception, Integer> tk = null;
try {
tk = Right.ofRight(999999 / d);
} catch (Exception e) {
tk = Left.ofLeft(e);
}
return tk; })
.collect(
BinList<Exception, Integer>::new,
(bl, o) -> bl.append(o),
BinList::appendAll);
System.out.println(ieBlst);
// 输出: BinList [
// leftList=[
// java.lang.ArithmeticException: / by zero,
// java.lang.ArithmeticException: / by zero,
// java.lang.ArithmeticException: / by zero],
// rightList=[
// 333333, 499999, 249999, 142857, 999999, 199999]]
Lambda 下并发程序
并发与并行:
- 并发是两个任务共享时间段,并行是两个任务同一时间发生。
- 并行化是指为了缩短任务执行的时间,将任务分解为几个部分,然后并行执行, 这和顺序执行的工作量是一样的,区别是多个 CPU 一起来干活, 花费的时间自然减少了。
- 数据并行化。数据并行化是指将数据分为块,为每块数据分配独立的处理单元。
并行化流操作
并行化流操作是 Stream 提供的一个特性,只需改变一个方法调用, 就可以让其拥有并行操作的能力:
-
如果已经存在一个 Stream 对象,调用他的
parallel方法就能让其并行执行。 -
如果已经存在一个集合,调用
parallelStream方法就能获取一个拥有并行执行能力的 Stream。
并行流主要解决如何高效使用多核 CPU 的事情。
@Data
class Account{
private String name;
private boolean active;
private Integer amount;
}
public int getActiveAmount(List<Account> accounts){
return accounts.parallelStream()
.filter(account -> account.isActive())
.mapToInt(account -> account.getAmount())
.sum();
}
public int getActiveAmount2(List<Account> accounts){
return accounts.stream()
.parallel()
.filter(account -> account.isActive())
.mapToInt(Account::getAmount)
.sum();
}
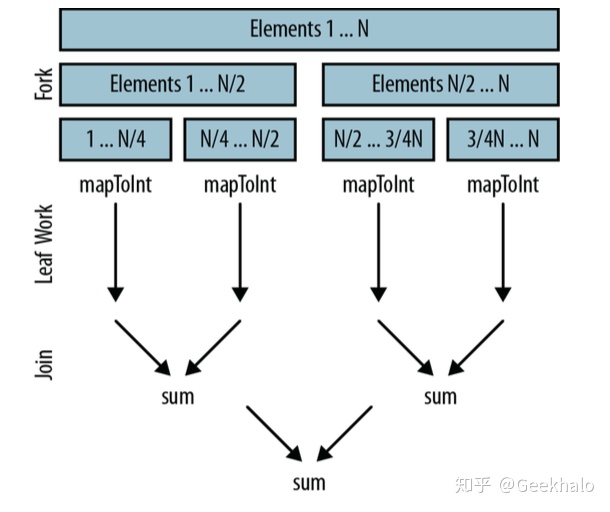
并行流底层使用 fork/join 框架,fork递归式的分解问题,然后每个段并行执行, 最终有 join 合并结果,返回最后的值。
阻塞 IO VS 非阻塞 IO
BIO VS NIO
BIO 阻塞式 IO,是一种通用且容易理解的方式, 与程序交互时通常都符合这种顺序执行的方式, 但其主要的缺陷在于每个 socket 会绑定一个 Thread 进行操作, 当长链过多时会消耗大量的 Server 资源,从而导致其扩展性性下降。
NIO 非阻塞 IO,一般指的是 IO 多路复用, 可以使用一个线程同时对多个 socket 的读写进行监控, 从而使用少量线程服务于大量 Socket。
由于客户端开发的简便性,大多数的驱动都是基于 BIO 实现,包括 MySQL、Redis、Mongo 等;在服务器端,由于其高性能的要求,基本上是 NIO 的天下, 以最大限度的提升系统的可扩展性。
由于客户端存在大量的 BIO 操作,我们的客户端线程会不停的被 BIO 阻塞, 以等待操作返回值,因此线程的效率会大打折扣。因为线程在 IO 与 CPU 之间不停切换, 走走停停,同时线程也没有办法释放,一直等到任务完成。
Future
构建并发操作的另一种方案便是 Future,Future 是一种凭证,调用方法不是直接返回值, 而是返回一个 Future 对象,刚创建的 Future 为一个空对象,由后台线程执行耗时操作, 并在结束时将结果写回到 Future 中。
当调用 Future 对象的 get 方法获取值时,会有两个可能,如果后台线程已经运行完成, 则直接返回;如果后台线程没有运行完成,则阻塞调用线程,知道后台线程运行完成或超时。
使用 Future 方式,可以以并行的方式运行多个子任务。
当主线程需要调用比较耗时的操作时,可以将其放在辅助线程中执行, 并在需要数据的时候从 future 中获取,如果辅助线程已经运行完成, 则立即拿到返回的结果,如果辅助线程还没有运行完成,则主线程等待, 并在完成时获取结果。
一种常见的场景是在Controller中从多个Service中获取结果, 并将其封装成一个View对象返回给前端用于显示,假设需要从三个接口中获取结果, 每个接口的平均响应时间是20ms,那按照串行模式,总耗时为 \(sum(i1, i2, i3) = 60ms\);如果按照Future并发模式将加载任务交由辅助线程处理, 总耗时为max\((i1, i2, i3 ) = 20ms\), 大大减少了系统的响应时间。
private ExecutorService executorService = Executors.newFixedThreadPool(20);
private User loadUserByUid(Long uid) {
sleep(20);
return new User();
}
private Address loadAddressByUid(Long uid) {
sleep(20);
return new Address();
}
private Account loadAccountByUid(Long uid) {
sleep(20);
return new Account();
}
/**
* 总耗时 sum(LoadUser, LoadAddress, LoadAccount) = 60ms
* @param uid
* @return
*/
public View getViewByUid1(Long uid) {
User user = loadUserByUid(uid);
Address address = loadAddressByUid(uid);
Account account = loadAccountByUid(uid);
View view = new View();
view.setUser(user);
view.setAddress(address);
view.setAccount(account);
return view;
}
/**
* 总耗时 max(LoadUser, LoadAddress, LoadAccount) = 20ms
* @param uid
* @return
* @throws ExecutionException
* @throws InterruptedException
*/
public View getViewByUid(Long uid)
throws ExecutionException, InterruptedException
{
Future<User> userFuture = executorService.submit(()->loadUserByUid(uid));
Future<Address> addressFuture = executorService.submit(()->loadAddressByUid(uid));
Future<Account> accountFuture = executorService.submit(()->loadAccountByUid(uid));
View view = new View();
view.setUser(userFuture.get());
view.setAddress(addressFuture.get());
view.setAccount(accountFuture.get());
return view;
}
private void sleep(long time) {
try {
TimeUnit.MILLISECONDS.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Data
class View{
private User user;
private Address address;
private Account account;
}
class User{ }
class Address{ }
class Account{ }
Future 方式存在一个问题,及在调用 get 方法时会阻塞主线程,这是资源的极大浪费, 我们真正需要的是一种不必调用 get 方法阻塞当前线程, 就可以操作 future 对象返回的结果。
上例中只是子任务能够拆分并能并行执行的一种典型案例,在实际开发过程中, 我们会遇到更多、更复杂的场景,比如:
- 将两个 Future 结果合并成一个,同时第二个又依赖于第一个的结果
- 等待 Future 集合中所有记录的完成
- 等待 Future 集合中的最快的任务完成
- 定义任务完成后的操作
对此,我们引入了CompletableFuture对象。
CompletableFuture
- CompletableFuture 结合了 Future 和回调两种策略,以更好的处理事件驱动任务。
- CompletableFuture 与Stream 的设计思路一致,通过注册 Lambda 表达式, 把高阶函数链接起来,从而定制更复杂的处理流程。
CompletableFuture 提供了一组函数用于定义流程,其中包括:
创建函数
CompletableFuture 提供了一组静态方法用于创建 CompletableFuture 实例:
使用已经创建好的值,创建CompletableFuture对象:
public static <U> CompletableFuture<U> completedFuture(U value)
基于Runnable创建CompletableFuture对象,返回值为void,及没有返回值:
public static CompletableFuture<void> runAsync(Runnable runnable)
基于Runnable和自定义线程池创建CompletableFuture对象,返回值为void,
及没有返回值:
public static CompletableFuture<Void> runAsync( Runnable runnable, Executor executor)
基于Supplier创建CompletableFuture对象,返回值为U:
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)
基于 Supplier 和自定义线程池创建CompletableFuture对象,返回值为U:
public static <U> CompletableFuture<U> supplyAsync( Supplier<U> supplier, Executor executor)
以Async结尾并且没有指定Executor的方法会使用ForkJoinPool.commonPool()
作为它的线程池执行异步代码。
方法的参数类型都是函数式接口,所以可以使用 Lambda 表达式实现异步任务。
计算结果完成后
当CompletableFuture计算完成或者计算过程中抛出异常时进行回调。
public CompletableFuture<T> whenComplete( BiConsumer<? super T,? super Throwable> action) public CompletableFuture<T> whenCompleteAsync( BiConsumer<? super T,? super Throwable> action) public CompletableFuture<T> whenCompleteAsync( BiConsumer<? super T,? super Throwable> action, Executor executor) public CompletableFuture<T> exceptionally( Function<Throwable,? extends T> fn)
参数action的类型是BiConsumer<? super T,? super Throwable>
它可以处理正常的计算结果,或者异常情况。
方法不以Async结尾,意味着参数action使用相同的线程执行,
而Async可能会使用其他线程执行(如果是使用相同的线程池,
也可能会被同一个线程选中执行)。
exceptionally方法针对异常情况进行处理,
当原始的CompletableFuture抛出异常的时候,
就会触发这个CompletableFuture的计算。
下面一组方法虽然也返回CompletableFuture对象,
是对象的值和原来的CompletableFuture计算的值不同。
当原先的CompletableFuture的值计算完成或者抛出异常的时候,
会触发这个CompletableFuture对象的计算,结果由BiFunction参数计算而得。
因此这组方法兼有 whenComplete 和转换的两个功能。
public <?U> CompletableFuture<?U> handle( BiFunction<? super T,Throwable,? extends U> fn) public <?U> CompletableFuture<?U> handleAsync( BiFunction<? super T,Throwable,? extends U> fn) public <?U> CompletableFuture<?U> handleAsync( BiFunction<? super T,Throwable,? extends U> fn, Executor executor)
转化函数
转化函数类似于 Stream 中的惰性求助函数,
主要对CompletableFuture的中间结果进行流程定制:
public <U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn)
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn)
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn,
Executor executor)
通过函数完成对CompletableFuture中的值得转化,Async在线的线程池中处理,
参数executor可以自定义线程池。
纯消费函数
上面的方法当计算完成的时候,会生成新的计算结果(thenApply, handle),
或者返回同样的计算结果whenComplete,CompletableFuture还提供了一种处理结果的方法,
只对结果执行 Action,而不返回新的计算值,因此计算值为void:
public CompletableFuture<Void> thenAccept(Consumer<? super T> action) public CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action) public CompletableFuture<Void> thenAcceptAsync(Consumer<? super T> action, Executor executor)
其他的参数类型与之前的含义一致,不同的是函数接口Consumer,这个接口只有输入,
没有返回值。
thenAcceptBoth以及相关方法提供了类似的功能,
当两个CompletionStage都正常完成计算的时候,就会执行提供的 action,
它用来组合另外一个异步的结果:
public <U> CompletableFuture<Void> thenAcceptBoth( CompletionStage<? extends U> other, BiConsumer<? super T,? super U> action) public <U> CompletableFuture<Void> thenAcceptBothAsync( CompletionStage<? extends U> other, BiConsumer<? super T,? super U> action) public <U> CompletableFuture<Void> thenAcceptBothAsync( CompletionStage<? extends U> other, BiConsumer<? super T,? super U> action, Executor executor)
组合函数
组合函数主要应用于后续计算需要CompletableFuture计算结果的场景:
public <U> CompletableFuture<U> thenCompose( Function<? super T,? extends CompletionStage<U>> fn) public <U> CompletableFuture<U> thenComposeAsync( Function<? super T,? extends CompletionStage<U>> fn) public <U> CompletableFuture<U> thenComposeAsync( Function<? super T,? extends CompletionStage<U>> fn, Executor executor)
这一组方法接受一个Function作为参数,这个Function的输入是当前的
CompletableFuture的计算值,返回结果将是一个新的CompletableFuture,
这个新的CompletableFuture会组合原来的CompletableFuture和函数返回的
CompletableFuture。
因此它的功能类似:
A +–> B +—> C
下面的一组方法thenCombine用来复合另外一个CompletionStage的结果。
两个CompletionStage是并行执行的,它们之间并没有先后依赖顺序,
other并不会等待先前的CompletableFuture执行完毕后再执行,
当两个CompletionStage全部执行完成后,统一调用BiFunction函数,
计算最终的结果:
public <U,V> CompletableFuture<V> thenCombine( CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn) public <U,V> CompletableFuture<V> thenCombineAsync( CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn) public <U,V> CompletableFuture<V> thenCombineAsync( CompletionStage<? extends U> other, BiFunction<? super T,? super U,? extends V> fn, Executor executor)
Either
Either系列方法不会等两个CompletableFuture都计算完成后执行计算,
而是当任意一个CompletableFuture计算完成的时候就会执行:
public CompletableFuture<Void> acceptEither( CompletionStage<? extends T> other, Consumer<? super T> action) public CompletableFuture<Void> acceptEitherAsync( CompletionStage<? extends T> other, Consumer<? super T> action) public CompletableFuture<Void> acceptEitherAsync( CompletionStage<? extends T> other, Consumer<? super T> action, Executor executor) public <U> CompletableFuture<U> applyToEither( CompletionStage<? extends T> other, Function<? super T,U> fn) public <U> CompletableFuture<U> applyToEitherAsync( CompletionStage<? extends T> other, Function<? super T,U> fn) public <U> CompletableFuture<U> applyToEitherAsync( CompletionStage<? extends T> other, Function<? super T,U> fn, Executor executor)
辅助方法
辅助方法主要指allOf和anyOf,这两个静态方法用于组合多个CompletableFuture:
allOf方法是当所有的CompletableFuture都执行完后执行计算:
public static CompletableFuture<Void> allOf(CompletableFuture<?>... cfs)
anyOf方法是当任意一个CompletableFuture执行完后就会执行计算:
public static CompletableFuture<Object> anyOf(CompletableFuture<?>... cfs)