线程基础
线程
windows下后台启动JVM:
@START /B javaw -Dfile.encoding=UTF-8 -cp clientupdate.jar com.ctrip.crawler.autoupdate.ClientUpgrader > autoupdate.log @START /B javaw -Dfile.encoding=UTF-8 -Xms256m -Xmx256m -cp C:/var/crawl/botexecutor.jar com.ctrip.Main > nohup.out 2>&1
创建线程
Runnable接口的run()方法是要运行的逻辑。
Thread类实现run()方法。方法里是执行的逻辑。start()方法表示启动新线程。
线程优先级
线程的成员方法setPriority。如设置当前线程的优先级为普通:
Thread.currentThread.setPriority(Thread.NORNAL_PRIORITY)
可用优先级:
-
NORMAL_PRIORITY -
MIN_PRIORITY -
MAX_PRIORITY - 等……
守护线程
分为「普通线程」和「守护线程」,区别是如果还有普通线程没有执行完毕,JVM是关不掉的。
普通线程创建的线程默认都是普通线程,除非用setDaemon(true)指定:
Thread t1 = new Thread(runnable); t1.setDaemon(true); t1.start();
多个线程相互协调
sleep、yield、join
暂停线程:Thread.sleep()
让出CPU:Thread.yield()
给其他线程执行的机会,如:循环处理多个记录的时候每个循环里yield()一下,或阻塞
在IO时yield()一下。
等待其他线程完毕:t1.join()
当前的线程停下,等这个t1的线程执行完了以后再执行当前线程。
中断
对一个线程发出停止信号,如:t1.interrupted()要求线程t1停止。
这样t1的执行就会抛出InterruptedException异常,它是受检查异常,表示当前线程
被其他线程打断。如下面的代码收到异常后就break了,那么线程就中断了:
class T1 extends Thread {
while(true) {
try {
/* do something */
} catch (InterruptedException e) {
break;
}
}
}
如果去掉上面的break那线程就中断不了了。
执行线程并中断的过程如下:
T1 t1 = new T1(); t1.start(); t1.join(); t1.interrupt();
Java里一个线程调用了Thread.interrupt()到底意味着什么?
首先,一个线程不应该由其他线程来强制中断或停止,而是应该由线程自己自行停止。
所以,Thread.stop,Thread.suspend,Thread.resume都已经被废弃了。
而Thread.interrupt的作用其实也不是中断线程,而是「通知线程应该中断了」,
具体到底中断还是继续运行,应该由被通知的线程自己处理。
具体来说,当对一个线程,调用interrupt()时:
-
如果线程处于被阻塞状态(例如处于
sleep,wait,join等状态), 那么线程将立即退出被阻塞状态,并抛出一个InterruptedException异常。 仅此而已。 -
如果线程处于正常活动状态,那么会将该线程的中断标志设置为
true,仅此而已。 被设置中断标志的线程将继续正常运行,不受影响。
interrupt()并不能真正的中断线程,需要被调用的线程自己进行配合才行。
也就是说,一个线程如果有被中断的需求,那么就可以这样做。
- 在正常运行任务时,经常检查本线程的中断标志位, 如果被设置了中断标志就自行停止线程。
-
在调用阻塞方法时正确处理
InterruptedException异常。 (例如,catch异常后就结束线程。)
Thread thread = new Thread(() -> {
while (!Thread.interrupted()) {
// do more work.
}
});
thread.start();
// 一段时间以后
thread.interrupt();
Thread.interrupted()清除标志位是为了下次继续检测标志位。
如果一个线程被设置中断标志后,选择结束线程那么自然不存在下次的问题,
而如果一个线程被设置中断标识后,进行了一些处理后选择继续进行任务,
而且这个任务也是需要被中断的,那么当然需要清除标志位了。
线程协作
每个对象都有wait()与notify()和notifyAll()方法,选一个对象作为标志来同步:
* 以对象o为标志,当前线程停止,让给其他线程执行:
synchronized { o.wait(); } //当前线程停止,等待唤醒。
这样当前线程就不会再醒过来,除非其他线程里调用对象o的nodify或是nodifyAll
方法:
synchronized { o.notifyAll(); } // 唤醒所有以o为标志等待的线程
忙等待没有对运行等待线程的CPU进行有效的利用,除非平均等待时间非常短。否则, 让等待线程进入睡眠或者非运行状态更为明智,直到它接收到它等待的信号。
wait、notify和notifyAll
Java有一个内建的等待机制来允许线程在等待信号的时候变为非运行状态。
java.lang.Object类定义了三个方法,wait()、notify()和notifyAll()来实现
这个等待机制。
一个线程一旦调用了任意对象的wait()方法,就会变为非运行状态,
直到另一个线程调用了同一个对象的notify()方法。为了调用wait()或者notify(),
线程必须先获得那个对象的锁。
也就是说,线程必须在同步块里调用wait()或者notify()。
以下是MySingal的修改版本——使用了wait()和notify()的MyWaitNotify:
public class MonitorObject{ }
public class MyWaitNotify{
MonitorObject myMonitorObject = new MonitorObject();
public void doWait(){
synchronized(myMonitorObject){
try{
myMonitorObject.wait();
} catch(InterruptedException e){...}
}
}
public void doNotify(){
synchronized(myMonitorObject){
myMonitorObject.notify();
}
}
}
等待线程将调用doWait(),而唤醒线程将调用doNotify()。当一个线程调用一个对象的
notify()方法,正在等待该对象的所有线程中将有一个线程被唤醒并允许执行(校注:
这个将被唤醒的线程是随机的,不可以指定唤醒哪个线程)。同时也提供了一个
notifyAll()方法来唤醒正在等待一个给定对象的所有线程。
如你所见,不管是等待线程还是唤醒线程都在同步块里调用wait()和notify()。这是
强制性的!一个线程如果没有持有对象锁,将不能调用wait(),notify()或者
notifyAll()。否则,会抛出IllegalMonitorStateException异常。
(校注:JVM是这么实现的,当你调用wait时候它首先要检查下当前线程是否是锁的拥有者 ,不是则抛出IllegalMonitorStateExcept,参考JVM源码的 1422行。)
但是,这怎么可能?等待线程在同步块里面执行的时候,不是一直持有监视器对象(
myMonitor对象)的锁吗?等待线程不能阻塞唤醒线程进入doNotify()的同步块吗?
答案是:的确不能。一旦线程调用了wait()方法,它就释放了所持有的监视器对象上的锁
。这将允许其他线程也可以调用wait()或者notify()。
一旦一个线程被唤醒,不能立刻就退出wait()的方法调用,直到调用notify()的线程
退出了它自己的同步块。换句话说:被唤醒的线程必须重新获得监视器对象的锁,才可以
退出wait()的方法调用,因为wait方法调用运行在同步块里面。如果多个线程被
notifyAll()唤醒,那么在同一时刻将只有一个线程可以退出wait()方法,因为每个
线程在退出wait()前必须获得监视器对象的锁。
sleep与wait的区别
对于wait()和sleep()貌似都会阻塞线程,但是它们确实是很大的区别的。
从设计的定位上来说:
-
sleep()是线程类Thread里面的静态的方法,不能改变对象的机锁,所以当在一个 Synchronized块中调用sleep方法时,线程虽然休眠了,但是对象的机锁并木有被释放, 其他线程无法访问这个对象(即使睡着也持有对象锁); -
而
wait()是Object类的方法。当一个线程执行到wait方法时,它就进入到一个和 该对象相关的等待池中,同时失去(释放)了对象的机锁(暂时失去机锁,wait(long timeout)超时时间到后还需要返还对象锁),其他线程可以访问; -
sleep()使当前线程进入停滞状态(阻塞当前线程),让出CUP的使用、目的是不让 当前线程独自霸占该进程所获的CPU资源,以留一定时间给其他线程执行的机会; 在sleep()休眠时间期满后,该线程不一定会立即执行, 这是因为其它线程可能正在运行而且没有被调度为放弃执行, 除非此线程具有更高的优先级。
所以在使用上:
-
sleep()方法不需要被notify唤醒;而wait()使用notify或者notifyAlll或者指定睡眠时间(如wait(10))来唤醒当前等待池中的线程。 -
wait()因为涉及到锁的战胜,所以必须放在synchronized块中,否则会在程序运行时 会抛出java.lang.IllegalMonitorStateException异常。
所以sleep()和wait()方法的最大区别是:
-
sleep()睡眠时,保持对象锁,仍然占有该锁; -
而
wait()睡眠时,释放对象锁。
但是wait()和sleep()都可以通过interrupt()方法打断线程的暂停状态,
从而使线程立刻抛出InterruptedException(但不建议使用该方法)。
丢失的信号(Missed Signals)
notify()和notifyAll()方法不会保存调用它们的方法,因为当这两个方法被调用时,
有可能没有线程处于等待状态。通知信号过后便丢弃了。
因此,如果一个线程先于被通知线程调用wait()前调用了notify(),
等待的线程将错过这个信号。这可能是也可能不是个问题。不过,在某些情况下,
这可能使等待线程永远在等待,不再醒来,因为线程错过了唤醒信号。
为了避免丢失信号,必须把它们保存在信号类里。在MyWaitNotify的例子中,
通知信号应被存储在MyWaitNotify实例的一个成员变量里。
以下是MyWaitNotify的修改版本:
public class MyWaitNotify2{
MonitorObject myMonitorObject = new MonitorObject();
boolean wasSignalled = false;
public void doWait(){
synchronized(myMonitorObject){
if(!wasSignalled){
try{
myMonitorObject.wait();
} catch(InterruptedException e){...}
}
//clear signal and continue running.
wasSignalled = false;
}
}
public void doNotify(){
synchronized(myMonitorObject){
wasSignalled = true;
myMonitorObject.notify();
}
}
}
留意doNotify()方法在调用notify()前把wasSignalled变量设为true。同时,
留意doWait()方法在调用wait()前会检查wasSignalled变量。事实上,
如果没有信号在前一次doWait()调用和这次doWait()调用之间的时间段里被接收到,
它将只调用wait()。
(校注:为了避免信号丢失, 用一个变量来保存是否被通知过。在notify前,设置自己 已经被通知过。在wait后,设置自己没有被通知过,需要等待通知。)
假唤醒
由于莫名其妙的原因,线程有可能在没有调用过notify()和notifyAll()的情况下醒来。
这就是所谓的假唤醒(spurious wakeups)。无端端地醒过来了。
如果在MyWaitNotify2的doWait()方法里发生了假唤醒,
等待线程即使没有收到正确的信号,也能够执行后续的操作。
这可能导致你的应用程序出现严重问题。
为了防止假唤醒,保存信号的成员变量将在一个while循环里接受检查, 而不是在if表达式里。这样的一个while循环叫做自旋锁(校注:这种做法要慎重, 目前的JVM实现自旋会消耗CPU,如果长时间不调用doNotify方法,doWait方法会一直自旋, CPU会消耗太大)。
打个比方,你和你的哥们儿在火车站候车大厅等车。由于离火车到站还有段时间, 你决定去睡一觉。以下几种情况会让你醒过来:
- 睡到自然醒(timeout)
- 车站广播:「开往XX的列车即将到站」(notified)
- 哥们儿把你拖起来吃鸡(interrupted)
- 做噩梦(spurious wakeup)
如果是做噩梦醒来,你得看看火车是不是快到了,如果没到则继续睡。 如果你运气很背,可能会做好几个噩梦,所以要while循环。
被唤醒的线程会自旋直到自旋锁(while循环)里的条件变为false。
以下MyWaitNotify2的修改版本展示了这点:
public class MyWaitNotify3{
MonitorObject myMonitorObject = new MonitorObject();
boolean wasSignalled = false;
public void doWait(){
synchronized(myMonitorObject){
while(!wasSignalled){
try{
myMonitorObject.wait();
} catch(InterruptedException e){...}
}
//clear signal and continue running.
wasSignalled = false;
}
}
public void doNotify(){
synchronized(myMonitorObject){
wasSignalled = true;
myMonitorObject.notify();
}
}
}
留意wait()方法是在while循环里,而不在if表达式里。
如果等待线程没有收到信号就唤醒,wasSignalled变量将变为false,
while循环会再执行一次,促使醒来的线程回到等待状态。
多个线程等待相同信号
如果你有多个线程在等待,被notifyAll()唤醒,但只有一个被允许继续执行,
使用while循环也是个好方法。每次只有一个线程可以获得监视器对象锁,
意味着只有一个线程可以退出wait()调用并清除wasSignalled标志(设为false)。
一旦这个线程退出doWait()的同步块,其他线程退出wait()调用,
并在while循环里检查wasSignalled变量值。但是,
这个标志已经被第一个唤醒的线程清除了,所以其余醒来的线程将回到等待状态,
直到下次信号到来。
不要在字符串常量或全局对象中调用wait
(校注:本章说的字符串常量指的是值为常量的变量)
本文早期的一个版本在MyWaitNotify例子里使用字符串常量("")作为管程对象。以下是
那个例子:
public class MyWaitNotify{
String myMonitorObject = "";
boolean wasSignalled = false;
public void doWait(){
synchronized(myMonitorObject){
while(!wasSignalled){
try{
myMonitorObject.wait();
} catch(InterruptedException e){...}
}
//clear signal and continue running.
wasSignalled = false;
}
}
public void doNotify(){
synchronized(myMonitorObject){
wasSignalled = true;
myMonitorObject.notify();
}
}
}
在空字符串作为锁的同步块(或者其他常量字符串)里调用wait()和notify()
产生的问题是,JVM / 编译器内部会把常量字符串转换成同一个对象。这意味着,
即使你有2个不同的MyWaitNotify实例,它们都引用了相同的空字符串实例。
同时也意味着存在这样的风险:
在第一个MyWaitNotify实例上调用doWait()的线程会被在第二个MyWaitNotify
实例上调用doNotify()的线程唤醒。这种情况可以画成以下这张图:
String
/ \
MyWaitNotify1 MyWaitNotify2
/ \ / \
Thread-A Thread-B Thread-C Thread-D
起初这可能不像个大问题。毕竟,如果doNotify()在第二个MyWaitNotify实例上被调用
,真正发生的事不外乎线程A和B被错误的唤醒了 。这个被唤醒的线程(A或者B)
将在while循环里检查信号值,然后回到等待状态,因为doNotify()并没有在第一个
MyWaitNotify实例上调用,而这个正是它要等待的实例。
这种情况相当于引发了一次假唤醒。线程A或者B在信号值没有更新的情况下唤醒。
但是代码处理了这种情况,所以线程回到了等待状态。
记住,即使4个线程在相同的共享字符串实例上调用wait()和notify(),doWait()和
doNotify()里的信号还会被2个MyWaitNotify实例分别保存。
在MyWaitNotify1上的一次doNotify()调用可能唤醒MyWaitNotify2的线程,
但是信号值只会保存在MyWaitNotify1里。
问题在于:
由于doNotify()仅调用了notify()而不是notifyAll(),即使有4个线程在相同的
字符串(空字符串)实例上等待,只能有一个线程被唤醒。所以,如果线程A或B被发给
C或D的信号唤醒,它会检查自己的信号值,看看有没有信号被接收到,
然后回到等待状态。而C和D都没被唤醒来检查它们实际上接收到的信号值,
这样信号便丢失了。这种情况相当于前面所说的丢失信号的问题。C和D被发送过信号,
只是都不能对信号作出回应。
如果doNotify()方法调用notifyAll(),而非notify(),
所有等待线程都会被唤醒并依次检查信号值。线程A和B将回到等待状态,
但是C或D只有一个线程注意到信号,并退出doWait()方法调用。
C或D中的另一个将回到等待状态,因为获得信号的线程在退出doWait()
的过程中清除了信号值(置为false)。
看过上面这段后,你可能会设法使用notifyAll()来代替notify(),
但是这在性能上是个坏主意。在只有一个线程能对信号进行响应的情况下,
没有理由每次都去唤醒所有线程。
所以:在wait / notify机制中,不要使用全局对象,字符串常量等。 应该使用对应唯一的对象。
例如,每一个MyWaitNotify3的实例(前一节的例子)拥有一个属于自己的监视器
对象,而不是在空字符串上调用wait /notify。
注:管程(英语:Monitors,也称为监视器)是对多个工作线程实现互斥访问共享资源的 对象或模块。这些共享资源一般是硬件设备或一群变量。管程实现了在一个时间点,最多 只有一个线程在执行它的某个子程序。与那些通过修改数据结构实现互斥访问的并发程序 设计相比,管程很大程度上简化了程序设计。
本地线程变量
ThreadLocal类给每个线程都准备一个资源的副本。保证每个资源只有当前线程可以
访问。
ThreadLocal对象不能简单地赋值就完了。因为它管理的每个线程的内容都要初始化,
所以它每次都会调用自己的initialValue()方法。重写这个方法可以完成每个线程的
初始化。
private static ThreadLocal<List<String>> threadLod =
new ThreadLocal<List<String>>() {
protected List<String> initialValue() {
return new ArrayList<String>();
}
}
ThreadLocal是什么
从线程的角度看,目标变量就象是线程的本地变量,这也是类名中Local所要表达的意思。
线程局部变量并不是Java的新发明,很多语言(如IBM IBM XL FORTRAN)在语法层面就提供
线程局部变量。在Java中没有提供在语言级支持,而是变相地通过ThreadLocal的类提供
支持。
所以,在Java中编写线程局部变量的代码相对来说要笨拙一些,因此造成线程局部变量没有 在Java开发者中得到很好的普及。
一个TheadLocal实例
下面,我们通过一个具体的实例了解一下ThreadLocal的具体使用方法。
package com.baobaotao.basic;
public class SequenceNumber {
// 通过匿名内部类覆盖ThreadLocal的initialValue()方法,指定初始值
private static ThreadLocal seqNum = new ThreadLocal() {
public Integer initialValue() {
return 0;
}
};
// 获取下一个序列值
public int getNextNum(){
seqNum.set(seqNum.get()+1);
return seqNum.get();
}
public static void main(String[] args) {
SequenceNumber sn = new SequenceNumber();
// 3个线程共享sn,各自产生序列号
TestClient t1 = new TestClient(sn);
TestClient t2 = new TestClient(sn);
TestClient t3 = new TestClient(sn);
t1.start();
t2.start();
t3.start();
}
private static class TestClient extends Thread {
private SequenceNumber sn;
public TestClient(SequenceNumber sn) {
this.sn = sn;
}
public void run() {
// 每个线程打出3个序列值
for (int i = 0; i < 3; i++) {
System.out.println("thread[" + Thread.currentThread().getName()
+ "] sn[" + sn.getNextNum() + "]");
}
}
}
}
通常我们通过匿名内部类的方式定义ThreadLocal的子类,提供初始的变量值。
TestClient线程产生一组序列号,生成3个TestClient,它们共享同一个
SequenceNumber实例。运行以上代码,在控制台上输出以下的结果:
thread[Thread-2] sn[1] thread[Thread-0] sn[1] thread[Thread-1] sn[1] thread[Thread-2] sn[2] thread[Thread-0] sn[2] thread[Thread-1] sn[2] thread[Thread-2] sn[3] thread[Thread-0] sn[3] thread[Thread-1] sn[3]
考察输出的结果信息,我们发现每个线程所产生的序号虽然都共享同一个SequenceNumber
实例,但它们并没有发生相互干扰的情况,而是各自产生独立的序列号,这是因为我们通过
ThreadLocal为每一个线程提供了单独的副本。
ThreadLocal的接口方法
ThreadLocal类接口很简单,只有4个方法,我们先来了解一下:
-
void set(Object value)设置当前线程的线程局部变量的值。 -
public Object get()该方法返回当前线程所对应的线程局部变量。 -
public void remove()JDK 5.0新增。线程结束后本来就会自动回收,显式调用并不是必要的。 -
protected Object initialValue()返回初始值,显然是为了让子类覆盖而设计的。
initialValue()是一个延迟调用方法,在线程第1次调用get()或set(Object)时才
执行,并且仅执行1次。ThreadLocal中的缺省实现直接返回一个null。
值得一提的是,在JDK5.0中,ThreadLocal已经支持泛型变为ThreadLocal<T>。API方法
也相应进行了调整,新版本的API方法分别是void set(T value)、T get()以及
T initialValue()。
实现原理
ThreadLocal是如何做到为每一个线程维护变量的副本的呢?其实实现的思路很简单:
线程类Thread中有一个成员threadLocals,它的类型是ThreadLocal类中的静态内部类ThreadLocalMap。
ThreadLocalMap的key是ThreadLocal对象本身,value是ThreadLocal容器内存放的对象。
比如拿以下代码为例:
ThreadLocal<SimpleDateFormat> sdf = new ThreadLocal<SimpleDateFormat>() {
@Override
protected SimpleDateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
}
};
那么在当前线程中有一个threadLocals,其中一个key是sdf,
对应的value是SimpleDateFormat对象的实例。
ThreadLocalMap
首先来看一下内部定义的 ThreadLocalMap 静态内部类:
static class ThreadLocalMap {
// 弱引用的key,继承自 WeakReference
static class Entry extends WeakReference<ThreadLocal<?>> {
/** ThreadLocal 修饰的对象 */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
/** 初始化大小,必须是二次幂 */
private static final int INITIAL_CAPACITY = 16;
/** 承载键值对的表,长度必须是二次幂 */
private Entry[] table;
/** 记录键值对表的大小 */
private int size = 0;
/** 再散列阈值 */
private int threshold; // Default to 0
// 构造方法
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
// 构造方法
private ThreadLocalMap(ThreadLocalMap parentMap) {
Entry[] parentTable = parentMap.table;
int len = parentTable.length;
setThreshold(len);
table = new Entry[len];
for (int j = 0; j < len; j++) {
Entry e = parentTable[j];
if (e != null) {
@SuppressWarnings("unchecked")
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();
if (key != null) {
Object value = key.childValue(e.value);
Entry c = new Entry(key, value);
int h = key.threadLocalHashCode & (len - 1);
while (table[h] != null)
h = nextIndex(h, len);
table[h] = c;
size++;
}
}
}
}
// 省略相应的方法实现
}
ThreadLocalMap是一个定制化的 Map 实现,可以简单将其理解为一般的 Map,
用作键值存储的内存数据库,至于为什么要专门实现而不是复用已有的 HashMap,我们在后面进行说明。
对于 ThreadLocal 来说,对外暴露的方法主要有 get、set,以及 remove 三个,下面逐一展开分析。
获取线程私有值
与一般的 Map 取值操作不同,这里的ThreadLocal#get方法并没有要求提供查询的 key,
也正如前面所说的,这里的 key 就是调用 ThreadLocal#get 方法的 ThreadLocal 对象自身:
public T get() {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 获取当前线程对象的 threadLocals 属性
ThreadLocalMap map = getMap(t);
if (map != null) {
// 以 ThreadLocal 对象为 key 获取目标线程私有值
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
如果当前线程对应的内存数据库 map 对象还未创建,则会调用
ThreadLocal#setInitialValue方法执行创建,如果在构造 ThreadLocal 对象时覆盖实现了
ThreadLocal#initialValue方法,则会调用该方法获取构造的初始化值并记录到创建的 map 对象中:
private T setInitialValue() {
// 调用模板方法 initialValue 获取指定的初始值
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
// 以当前 ThreadLocal 对象为 key 记录初始值
map.set(this, value);
else
// 创建 map 并记录初始值
createMap(t, value);
return value;
}
设置线程私有值
再来看一下ThreadLocal#set方法,因为 key 就是当前 ThreadLocal 对象,所以 ThreadLocal#set 方法也不需要指定 key:
public void set(T value) {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 获取当前线程对象的 threadLocals 属性
ThreadLocalMap map = getMap(t);
if (map != null)
// 以当前 ThreadLocal 对象为 key 记录线程私有值
map.set(this, value);
else
createMap(t, value);
}
和 ThreadLocal#get 方法的流程大致一样,都是操作当前线程私有的内存数据库 ThreadLocalMap,并记录目标值。
删除线程私有值
方法ThreadLocal#remove以当前 ThreadLocal 对象为 key,从当前线程内存数据库
ThreadLocalMap 中删除目标值,具体逻辑比较简单:
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
// 以当前 ThreadLocal 对象为 key
m.remove(this);
}
ThreadLocal 对外暴露的功能虽然有点小神奇,但是具体对应到内部实现并没有什么复杂的逻辑。 如果我们把每个线程持有的专属 ThreadLocalMap 对象理解为当前线程的私有数据库, 那么也就不难理解 ThreadLocal 的运行机制。每个线程自己维护自己的数据,彼此相互隔离, 不存在竞争,也就没有线程安全问题可言。
线程安全隐患
虽然对于每个线程来说数据是隔离的,但这也不表示任何对象丢到 ThreadLocal 中就万事大吉了,思考一下下面几种情况:
- 如果记录在 ThreadLocal 中的是一个线程共享的外部对象呢?
- 引入线程池,情况又会有什么变化?
- 如果 ThreadLocal 被 static 关键字修饰呢?
ThreadLocal 对象被外部共享
先来看 第 1 个问题,如果我们记录的是一个外部线程共享的对象,虽然我们以当前线程私有的 ThreadLocal 对象作为 key 对其进行了存储,但是恶魔终究是恶魔,共享的本质并不会因此而改变, 这种情况下的访问还是需要进行同步控制,最好的方法就是从源头屏蔽掉这类问题。我们来举个例子:
public class ThreadLocalWithSharedInstance implements Runnable {
// list 是一个事实共享的实例,即使被 ThreadLocal 修饰
private static List<String> list = new ArrayList<>();
private ThreadLocal<List<String>> threadLocal = ThreadLocal.withInitial(() -> list);
@Override
public void run() {
for (int i = 0; i < 5; i++) {
List<String> li = threadLocal.get();
li.add(Thread.currentThread().getName() + "_" + RandomUtils.nextInt(0, 10));
threadLocal.set(li);
}
System.out.println("[Thread-" + Thread.currentThread().getName() + "], list=" + threadLocal.get());
}
public static void main(String[] args) throws Exception {
Thread ta = new Thread(new ThreadLocalWithSharedInstance(), "a");
Thread tb = new Thread(new ThreadLocalWithSharedInstance(), "b");
Thread tc = new Thread(new ThreadLocalWithSharedInstance(), "c");
ta.start(); ta.join();
tb.start(); tb.join();
tc.start(); tc.join();
}
}
以上程序最终的输出如下:
[Thread-a], list=[a_2, a_7, a_4, a_5, a_7] [Thread-b], list=[a_2, a_7, a_4, a_5, a_7, b_3, b_3, b_4, b_7, b_7] [Thread-c], list=[a_2, a_7, a_4, a_5, a_7, b_3, b_3, b_4, b_7, b_7, c_8, c_3, c_4, c_7, c_5]
可以看到虽然使用了 ThreadLocal 修饰,但是 list 还是以共享的方式在多个线程之间被访问,如果不加控制则会存在线程安全问题。
引入线程池
再来看 第 2 个问题,相对问题 1 来说引入线程池就更加可怕,因为大部分时候我们都不会意识到问题的存在, 直到代码暴露出奇怪的现象。这一场景并没有违背线程私有的本质,只是一个线程被复用来处理多个业务, 而这个被线程私有的对象也会在多个业务之间被共享。例如:
public class ThreadLocalWithThreadPool implements Callable<Boolean> {
private static final int NCPU = Runtime.getRuntime().availableProcessors();
private ThreadLocal<List<String>> threadLocal = ThreadLocal.withInitial(() -> {
System.out.println("thread-" + Thread.currentThread().getId() + " init thread local");
return new ArrayList<>();
});
@Override
public Boolean call() throws Exception {
for (int i = 0; i < 5; i++) {
List<String> li = threadLocal.get();
li.add(Thread.currentThread().getId() + "_" + RandomUtils.nextInt(0, 10));
threadLocal.set(li);
}
System.out.println("[Thread-" + Thread.currentThread().getId() + "], list=" + threadLocal.get());
return true;
}
public static void main(String[] args) throws Exception {
System.out.println("cpu core size : " + NCPU);
List<Callable<Boolean>> tasks = new ArrayList<>(NCPU * 2);
ThreadLocalWithThreadPool tl = new ThreadLocalWithThreadPool();
for (int i = 0; i < NCPU * 2; i++) {
tasks.add(tl);
}
ExecutorService es = Executors.newFixedThreadPool(2);
List<Future<Boolean>> futures = es.invokeAll(tasks);
for (final Future<Boolean> future : futures) {
future.get();
}
es.shutdown();
}
}
以上程序的最终输出如下:
cpu core size : 8 thread-12 init thread local thread-11 init thread local [Thread-12], list=[12_8, 12_8, 12_4, 12_0, 12_1] [Thread-11], list=[11_3, 11_3, 11_4, 11_8, 11_4] [Thread-12], list=[12_8, 12_8, 12_4, 12_0, 12_1, 12_6, 12_7, 12_8, 12_8, 12_8] [Thread-11], list=[11_3, 11_3, 11_4, 11_8, 11_4, 11_0, 11_2, 11_1, 11_7, 11_9] [Thread-12], list=[12_8, 12_8, 12_4, 12_0, 12_1, 12_6, 12_7, 12_8, 12_8, 12_8, 12_8, 12_2, 12_8, 12_0, 12_6] [Thread-11], list=[11_3, 11_3, 11_4, 11_8, 11_4, 11_0, 11_2, 11_1, 11_7, 11_9, 11_0, 11_6, 11_1, 11_2, 11_9] [Thread-12], list=[12_8, 12_8, 12_4, 12_0, 12_1, 12_6, 12_7, 12_8, 12_8, 12_8, 12_8, 12_2, 12_8, 12_0, 12_6, 12_6, 12_3, 12_3, 12_1, 12_1] [Thread-11], list=[11_3, 11_3, 11_4, 11_8, 11_4, 11_0, 11_2, 11_1, 11_7, 11_9, 11_0, 11_6, 11_1, 11_2, 11_9, 11_7, 11_5, 11_0, 11_6, 11_9] [Thread-12], list=[12_8, 12_8, 12_4, 12_0, 12_1, 12_6, 12_7, 12_8, 12_8, 12_8, 12_8, 12_2, 12_8, 12_0, 12_6, 12_6, 12_3, 12_3, 12_1, 12_1, 12_0, 12_0, 12_1, 12_9, 12_5] [Thread-11], list=[11_3, 11_3, 11_4, 11_8, 11_4, 11_0, 11_2, 11_1, 11_7, 11_9, 11_0, 11_6, 11_1, 11_2, 11_9, 11_7, 11_5, 11_0, 11_6, 11_9, 11_2, 11_7, 11_0, 11_8, 11_0] [Thread-12], list=[12_8, 12_8, 12_4, 12_0, 12_1, 12_6, 12_7, 12_8, 12_8, 12_8, 12_8, 12_2, 12_8, 12_0, 12_6, 12_6, 12_3, 12_3, 12_1, 12_1, 12_0, 12_0, 12_1, 12_9, 12_5, 12_3, 12_6, 12_6, 12_0, 12_9] [Thread-11], list=[11_3, 11_3, 11_4, 11_8, 11_4, 11_0, 11_2, 11_1, 11_7, 11_9, 11_0, 11_6, 11_1, 11_2, 11_9, 11_7, 11_5, 11_0, 11_6, 11_9, 11_2, 11_7, 11_0, 11_8, 11_0, 11_0, 11_9, 11_2, 11_7, 11_2] [Thread-12], list=[12_8, 12_8, 12_4, 12_0, 12_1, 12_6, 12_7, 12_8, 12_8, 12_8, 12_8, 12_2, 12_8, 12_0, 12_6, 12_6, 12_3, 12_3, 12_1, 12_1, 12_0, 12_0, 12_1, 12_9, 12_5, 12_3, 12_6, 12_6, 12_0, 12_9, 12_5, 12_7, 12_7, 12_9, 12_7] [Thread-11], list=[11_3, 11_3, 11_4, 11_8, 11_4, 11_0, 11_2, 11_1, 11_7, 11_9, 11_0, 11_6, 11_1, 11_2, 11_9, 11_7, 11_5, 11_0, 11_6, 11_9, 11_2, 11_7, 11_0, 11_8, 11_0, 11_0, 11_9, 11_2, 11_7, 11_2, 11_4, 11_9, 11_7, 11_5, 11_5] [Thread-12], list=[12_8, 12_8, 12_4, 12_0, 12_1, 12_6, 12_7, 12_8, 12_8, 12_8, 12_8, 12_2, 12_8, 12_0, 12_6, 12_6, 12_3, 12_3, 12_1, 12_1, 12_0, 12_0, 12_1, 12_9, 12_5, 12_3, 12_6, 12_6, 12_0, 12_9, 12_5, 12_7, 12_7, 12_9, 12_7, 12_6, 12_1, 12_7, 12_8, 12_7] [Thread-11], list=[11_3, 11_3, 11_4, 11_8, 11_4, 11_0, 11_2, 11_1, 11_7, 11_9, 11_0, 11_6, 11_1, 11_2, 11_9, 11_7, 11_5, 11_0, 11_6, 11_9, 11_2, 11_7, 11_0, 11_8, 11_0, 11_0, 11_9, 11_2, 11_7, 11_2, 11_4, 11_9, 11_7, 11_5, 11_5, 11_8, 11_5, 11_0, 11_2, 11_2]
示例中,我用一个大小为 2 的线程池进行了模拟,可以看到初始化方法被调用了两次, 所有线程的操作都是复用这两个线程。
回忆一下前文所说的,ThreadLocal 的本质就是为每个线程维护一个线程私有的内存数据库来记录线程私有的对象, 但是在线程池情况下线程是会被复用的,也就是说线程私有的内存数据库也会被复用, 如果在一个线程被使用完准备回放到线程池中之前,我们没有对记录在数据库中的数据执行清理, 那么这部分数据就会被下一个复用该线程的业务看到,从而间接的共享了该部分数据。
ThreadLocal 对象用 static 关键字进行修饰
最后我们再来看一下 第 3 个问题,我们尝试将 ThreadLocal 对象用 static 关键字进行修饰:
public class ThreadLocalWithStaticEmbellish implements Runnable {
private static final int NCPU = Runtime.getRuntime().availableProcessors();
private static ThreadLocal<List<String>> threadLocal = ThreadLocal.withInitial(() -> {
System.out.println("thread-" + Thread.currentThread().getName() + " init thread local");
return new ArrayList<>();
});
@Override
public void run() {
for (int i = 0; i < 5; i++) {
List<String> li = threadLocal.get();
li.add(Thread.currentThread().getId() + "_" + RandomUtils.nextInt(0, 10));
threadLocal.set(li);
}
System.out.println("[Thread-" + Thread.currentThread().getName() + "], list=" + threadLocal.get());
}
public static void main(String[] args) throws Exception {
ThreadLocalWithStaticEmbellish tl = new ThreadLocalWithStaticEmbellish();
for (int i = 0; i < NCPU + 1; i++) {
Thread thread = new Thread(tl, String.valueOf((char) (i + 97)));
thread.start(); thread.join();
}
}
}
以上程序的最终输出如下:
thread-a init thread local [Thread-a], list=[11_4, 11_4, 11_4, 11_8, 11_0] thread-b init thread local [Thread-b], list=[12_0, 12_9, 12_0, 12_3, 12_3] thread-c init thread local [Thread-c], list=[13_6, 13_7, 13_5, 13_2, 13_0] thread-d init thread local [Thread-d], list=[14_1, 14_5, 14_5, 14_9, 14_2] thread-e init thread local [Thread-e], list=[15_4, 15_2, 15_6, 15_0, 15_8] thread-f init thread local [Thread-f], list=[16_7, 16_3, 16_8, 16_0, 16_0] thread-g init thread local [Thread-g], list=[17_6, 17_3, 17_8, 17_7, 17_1] thread-h init thread local [Thread-h], list=[18_0, 18_4, 18_5, 18_9, 18_3] thread-i init thread local [Thread-i], list=[19_7, 19_3, 19_7, 19_2, 19_0]
由程序运行结果可以看到 static 修饰并没有引出什么问题,实际上这也是很容易理解的, ThreadLocal 采用 static 修饰仅仅是让数据库中记录的 key 是一样的, 但是每个线程的内存数据库还是私有的,并没有被共享,就像不同的公司都有自己的用户信息表, 即使一些公司之间的用户 ID 是一样的,但是对应的用户数据却是完全隔离的。
内存泄露
关于 ThreadLocal 导致内存泄露的问题,曾经有一段时间在网上争得沸沸扬扬,那么到底会不会导致内存泄露呢?这里先给出答案: 如果使用不恰当,存在内存泄露的可能性。
我们来分析一下内存泄露的条件和原因,在最开始看 ThreadLocal 源码的时候,我就有一个疑问, ThreadLocal 为什么要专门实现 ThreadLocalMap,而不是采用已有的 HashMap 代替?
后来分析具体实现时看到执行存储时的 key 为当前 ThreadLocal 对象,不需要专门指定 key
能够在一定程度上简化使用,但这并不足以为此专门去实现 ThreadLocalMap。继续阅读我发现
ThreadLocalMap 在实现 Entry 的时候有些奇怪,居然继承了WeakReference:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
从而让 key 成为一个弱引用,我们知道弱引用对象拥有非常短暂的生命周期,在垃圾收集器线程扫描其所管辖的内存区域过程中, 一旦发现了弱引用对象,不管当前内存空间是否足够都会回收它的内存。也就是说这样的设计会很容易导致 ThreadLocal 对象被回收,线程所执行任务的时间长度是不固定的,这样的设计能够方便垃圾收集器回收线程私有的变量。
由此可以看出作者这样设计的目的是为了防止内存泄露,那怎么就变成了被很多文章所分析的是内存泄漏的导火索呢? 这些文章的共同观点就是 key 被回收了,但是 value 是一个强引用没有被回收,这些 value 就变成了一个个的僵尸。 这样的分析没有错,value 确实存在,且和线程是同生命周期的,但是如下策略可以保证尽量避免内存泄露:
- ThreadLocal 在每次执行 get 和 set 操作的时候都会去清理 key 为 null 的 value 值。
- value 与线程同生命周期,线程死亡之时,也是 value 被 GC 之日。
策略 1 没啥好说的,看看源码就知道,我们来举例验证一下策略 2:
public class ThreadLocalWithMemoryLeak implements Callable<Boolean> {
private class My50MB {
private byte[] buffer = new byte[50 * 1024 * 1024];
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("gc my 50 mb");
}
}
private class MyThreadLocal<T> extends ThreadLocal<T> {
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("gc my thread local");
}
}
private MyThreadLocal<My50MB> threadLocal = new MyThreadLocal<>();
@Override
public Boolean call() throws Exception {
System.out.println("Thread-" + Thread.currentThread().getId() + " is running");
threadLocal.set(new My50MB());
threadLocal = null;
return true;
}
public static void main(String[] args) throws Exception {
ExecutorService es = Executors.newCachedThreadPool();
Future<Boolean> future = es.submit(new ThreadLocalWithMemoryLeak());
future.get();
// gc my thread local
System.out.println("do gc");
System.gc();
TimeUnit.SECONDS.sleep(1);
// sleep 60s
System.out.println("sleep 60s");
TimeUnit.SECONDS.sleep(60);
// gc my 50 mb
System.out.println("do gc");
System.gc();
es.shutdown();
}
}
以上程序的最终输出如下:
Thread-11 is running do gc gc my thread local sleep 60s do gc gc my 50 mb
可以看到 value 最终还是被 GC 了,虽然第 1 次 GC 的时候没有被回收,这也验证 value
和线程是同生命周期的,之所以示例中等待 60 秒是因为Executors#newCachedThreadPool
中的线程默认生命周期是 60 秒,如果生命周期内该线程没有被再次复用则会死亡,
我们这里就是要等待线程死亡,一但线程死亡,value 也就被 GC 了。
所以 出现内存泄露的前提必须是持有 value 的线程一直存活 ,这在使用线程池时是很正常的, 在这种情况下 value 一直不会被 GC,因为线程对象与 value 之间维护的是强引用。此外就是 后续线程执行的业务一直没有调用 ThreadLocal 的 get 或 set 方法 ,导致不会主动去删除 key 为 null 的 value 对象,在满足这两个条件下 value 对象一直常驻内存,所以存在内存泄露的可能性。
那么我们应该怎么避免呢?前面我们分析过线程池情况下使用 ThreadLocal 存在小地雷, 这里的内存泄露一般也都是发生在线程池的情况下,所以在使用 ThreadLocal 时, 对于不再有效的 value 主动调用一下 remove 方法来进行清除,从而消除隐患,这也算是最佳实践吧。
InheritableThreadLocal
InheritableThreadLocal 继承自 ThreadLocal,实现上也比较简单(如下), 那么 InheritableThreadLocal 与 ThreadLocal 到底有什么区别呢?
public class InheritableThreadLocal<T> extends ThreadLocal<T> {
@Override
protected T childValue(T parentValue) {
return parentValue;
}
@Override
ThreadLocalMap getMap(Thread t) {
return t.inheritableThreadLocals;
}
@Override
void createMap(Thread t, T firstValue) {
t.inheritableThreadLocals = new ThreadLocalMap(this, firstValue);
}
}
在开始分析之前,我们先演示一个 ThreadLocal 的案例,如下:
private static ThreadLocal<String> tl = new ThreadLocal<>();
public static void main(String[] args) {
tl.set("zhenchao");
System.out.println("Main thread: " + tl.get());
Thread thread = new Thread(() -> System.out.println("Sub thread: " + tl.get()));
thread.start();
}
运行上述示例,输出如下:
Main thread: zhenchao Sub thread: null
可以看出,子线程拿不到主线程设置的 ThreadLocal 变量,当然这也是可以理解的, 毕竟主线程和子线程之间仍然是两个线程,但是在一些场景下我们希望对于主线程和子线程这种关系而言, ThreadLocal 变量能够被继承。这个时候就可以使用 InheritableThreadLocal 来实现, 对于上述示例而言,只需要将 ThreadLocal 改为 InheritableThreadLocal 即可, 具体实现比较简单,读者可以自己尝试一下。
下面我们来分析一下 InheritableThreadLocal 是如何做到让 ThreadLocal 变量在主线程和子线程之间进行继承的。
由 InheritableThreadLocal 的实现来看,InheritableThreadLocal 使用了inheritableThreadLocals变量替换了
ThreadLocal 的threadLocals变量,而这两个变量都是 ThreadLocalMap 类型。子线程在初始化时会判断父线程的
inheritableThreadLocals 是否为 null,如果不为 null,则使用父类的 inheritableThreadLocals
变量初始化自己的 inheritableThreadLocals,实现如下(位于 Thread#init 方法中):
// 如果父线程的 inheritableThreadLocals 变量不为空,则复制给子线程
if (inheritThreadLocals && parent.inheritableThreadLocals != null) {
this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
}
而 ThreadLocal#createInheritedMap 的实现如下:
static ThreadLocalMap createInheritedMap(ThreadLocalMap parentMap) {
return new ThreadLocalMap(parentMap);
}
private ThreadLocalMap(ThreadLocalMap parentMap) {
Entry[] parentTable = parentMap.table;
int len = parentTable.length;
setThreshold(len);
table = new Entry[len];
for (int j = 0; j < len; j++) {
Entry e = parentTable[j];
if (e != null) {
@SuppressWarnings("unchecked")
ThreadLocal<Object> key = (ThreadLocal<Object>) e.get();
if (key != null) {
// 调用 InheritableThreadLocal 的 childValue 方法
Object value = key.childValue(e.value);
Entry c = new Entry(key, value);
int h = key.threadLocalHashCode & (len - 1);
while (table[h] != null) {
h = nextIndex(h, len);
}
table[h] = c;
size++;
}
}
}
}
方法 InheritableThreadLocal#childValue 的实现只是简单返回了父线程中的值, 所以上述过程本质上就是一个拷贝父线程中 ThreadLocal 变量值的过程。
由上述实现我们可以看到,父线程和子线程在 ThreadLocal 变量的存储上仍然是隔离的, 只是在初始化子线程时会拷贝父线程的 ThreadLocal 变量,之后在运行期间彼此互不干涉, 也就是说在子线程启动起来之后,父线程和子线程各自对同一个 InheritableThreadLocal 实例的改动并不会被对方所看见。
Thread同步机制的比较
ThreadLocal和线程同步机制相比有什么优势呢?ThreadLocal和线程同步机制都是为了
解决多线程中相同变量的访问冲突问题。
在同步机制中,通过对象的锁机制保证同一时间只有一个线程访问变量。这时该变量是多个 线程共享的,使用同步机制要求程序慎密地分析什么时候对变量进行读写,什么时候需要 锁定某个对象,什么时候释放对象锁等繁杂的问题,程序设计和编写难度相对较大。
而ThreadLocal则从另一个角度来解决多线程的并发访问。ThreadLocal会为每一个线程
提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有
自己的变量副本,从而也就没有必要对该变量进行同步了。ThreadLocal提供了线程安全
的共享对象,在编写多线程代码时,可以把不安全的变量封装进ThreadLocal。
由于ThreadLocal中可以持有任何类型的对象,低版本JDK所提供的get()返回的是
Object对象,需要强制类型转换。但JDK 5.0通过泛型很好的解决了这个问题,在一定
程度地简化ThreadLocal的使用。
概括起来说,对于多线程资源共享的问题,同步机制采用了「以时间换空间」的方式,而
ThreadLocal采用了「以空间换时间」的方式。前者仅提供一份变量,让不同的线程排队
访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
Spring使用ThreadLocal解决线程安全问题
我们知道在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring中,
绝大部分Bean都可以声明为singleton作用域。就是因为Spring对一些Bean(如
RequestContextHolder、TransactionSynchronizationManager、
LocaleContextHolder等)中非线程安全状态采用ThreadLocal进行处理,让它们也成为
线程安全的状态,因为有状态的Bean就可以在多线程中共享了。
一般的Web应用划分为展现层、服务层和持久层三个层次,在不同的层中编写对应的逻辑, 下层通过接口向上层开放功能调用。在一般情况下,从接收请求到返回响应所经过的所有 程序调用都同属于一个线程,如图所示:
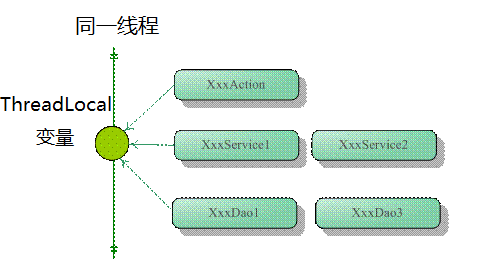
这样你就可以根据需要,将一些非线程安全的变量以ThreadLocal存放,在同一次请求
响应的调用线程中,所有关联的对象引用到的都是同一个变量。
下面的实例能够体现Spring对有状态Bean的改造思路:
非线程安全:
public class TopicDao {
//一个非线程安全的变量
private Connection conn;
public void addTopic(){
//引用非线程安全变量
Statement stat = conn.createStatement();
// ...
}
}
由于conn是成员变量,因为addTopic()方法是非线程安全的,必须在使用时创建一个新
TopicDao实例(非singleton)。下面使用ThreadLocal对conn这个非线程安全的
「状态」进行改造:
线程安全:
import java.sql.Connection;
import java.sql.Statement;
public class TopicDao {
// 使用ThreadLocal保存Connection变量
private static ThreadLocal connThreadLocal = new ThreadLocal();
public static Connection getConnection() {
// 如果connThreadLocal没有本线程对应的Connection
// 创建一个新的Connection,并将其保存到线程本地变量中。
if (connThreadLocal.get() == null) {
Connection conn = ConnectionManager.getConnection();
connThreadLocal.set(conn);
return conn;
}else{
return connThreadLocal.get();//③直接返回线程本地变量
}
}
public void addTopic() {
// 从ThreadLocal中获取线程对应的Connection
Statement stat = getConnection().createStatement();
}
}
不同的线程在使用TopicDao时,先判断connThreadLocal.get()是否是null,如果是
null,则说明当前线程还没有对应的Connection对象,这时创建一个Connection对象
并添加到本地线程变量中;如果不为null,则说明当前的线程已经拥有了Connection
对象,直接使用就可以了。这样,就保证了不同的线程使用线程相关的Connection,而
不会使用其它线程的Connection。因此,这个TopicDao就可以做到singleton共享了。
当然,这个例子本身很粗糙,将Connection的ThreadLocal直接放在DAO只能做到本DAO
的多个方法共享Connection时不发生线程安全问题,但无法和其它DAO共用同一个
Connection,要做到同一事务多DAO共享同一Connection,必须在一个共同的外部类
使用ThreadLocal保存Connection。
小结
ThreadLocal是解决线程安全问题一个很好的思路,它通过为每个线程提供一个独立的
变量副本解决了变量并发访问的冲突问题。在很多情况下,ThreadLocal比直接使用
synchronized同步机制解决线程安全问题更简单,更方便,且结果程序拥有更高的并发性
。
内置锁
synchronized针对一个对象加锁,如果修饰类静态方法,那锁来自于所在的类Class
对象。
代码执行到synchronized同步块里时会取得锁,而离开时(无论是正常离开还是异常)
都会放开锁。
重入
注意内置锁的粒度是「线程」而不是「调用」。一个线程取得了锁,其他线程都不能再 取得锁。但是本线程还是可以在不同的锁代码块中执行,因为锁的粒度是线程而不是 代码块或线程。这就叫「重入」。
例如:父类的方法是synchronized的。子类重写了这个方法,并在方法中调用了父类:
public class Widget {
public synchronized void doSomething() {
//...
}
}
public class LogginWidget extends Widget {
public synchronized void doSomething() {
//...
super.doSomething();
//...
}
}
上面的代码中,如果锁的粒度是方法调用,那线程就锁死了。但因为粒度是线程,所以可以 顺利执行。
避免重入锁死有两个选择:
- 编写代码时避免再次获取已经持有的锁
- 使用可重入锁
至于哪个选择最适合你的项目,得视具体情况而定。可重入锁通常没有不可重入锁那么好的表现,而且实现起来复杂,但这些情况在你的项目中也许算不上什么问题。无论你的项目用锁来实现方便还是不用锁方便,可重入特性都需要根据具体问题具体分析。
锁优化
处旋锁与自适应自旋
锁消除
锁粗化
轻量级锁
只有两个线程竞争时有用,对象头Mark World与线程栈相互指向来简单标记锁状态。
超过两个线程竞争时转为互斥锁。
偏向锁
消除在没有竞争状态下的同步原语,连CAS都省了。