目标检测
Boosting Theory
目标识别的基本过程就是在图片上定义多个窗口,一个个地检查是否是预定的目标。 机器学习中通过分类来分类每一个输入的类别。比如人脸识别就定义两人个分类: 是人脸或不是人脸。
Adaboost
Adaboost(Adaptive Boosting)不是一个具体的算法,但是一个可以帮助建立 分类器的元算法。它按权重综合多个较差的分类器生成一个更好的分类器:
\[ H(x) = sign(a_1h_1(x) + a_2h_2(x) + a_3h_3(x) + \cdots + a_Th_T(x)) \]
分类器sign只返回1或-1表示「是」或「不是」。依据是\(T\)个分类器,
每个分类器\(h_T\)都有一个对应的权重\(a_T\)。
例如,按多个指定的分类器为人的性别分类:
- \(h_1\)是身高,大于1.75cm分为男。
- \(h_2\)是否长发。
- \(h_3\)是否生过孩子。这个与性别几乎是完全关联,所以权重也应该是最高的
| Name | Height (h1) | Hair (h2) | Beard(h3) | Gender (f(x)) |
|---|---|---|---|---|
| Katherine | 1.69 | Long | Absent | Female |
| Dan | 1.76 | Short | Absent | Male |
| Sam | 1.80 | Short | Absent | Male |
| Laurent | 1.83 | Short | Present | Male |
| Sara | 1.77 | Short | Absent | Female |
定义训练用的数据(h1, h2, h3)
val data = new Mat(5, 3, CvType.CV_32FC1, new Scalar(0)) data.put(0, 0, Array[Float](1.69f, 1, 0)) data.put(1, 0, Array[Float](1.76f, 0, 0)) data.put(2, 0, Array[Float](1.80f, 0, 0)) data.put(3, 0, Array[Float](1.77f, 0, 0)) data.put(4, 0, Array[Float](1.83f, 0, 1))
定义用来验证的答案:
val responses = new Mat(5, 1, CvType.CV_32SC1, new Scalar(0)) responses.put(0,0, Array[Int](0, 1, 1, 0, 1))
准备好了数据以后,还要设置相关的参数:
val boost = Boost.create() boost.setBoostType(Boost.DISCRETE) // use Discrete Adaboost boost.setWeakCount(3) boost.setMinSampleCount(4)
-
setBoostType()设置Discrete Adaboost,其他的方法还有Real AdaBoost、LogitBoost 和Gentle AdaBoost。 -
setWeakCount()设置需要用到几个弱分类器。 -
setMinSampleCount()设置最小的节点样本数量,默认是10,我们例子的样本太小, 所以设置为4。这时在节点是Boost用到的DTree(decision-trees)结构的概念。 节点中样本的数量小于最小样本数,节点就不可再分。
数据和参数都准备好了,就可以用train()方法开始进行训练:
boost.train(data, Ml.ROW_SAMPLE, responses)
-
第一个参数
trainData是训练数据的矩阵。 -
第二个参数
tflag用来定义特征是放在矩阵的行里还是列里的,在这里被设置为Ml.ROW_SAMPLE -
第三个参数
response是正确答案。
用predict()方法列出训练数据得到的结果:
//This will simply show the input data is correctly classified
for (i <- 0 until 5) { logDebug("Result = {}", boost.predict(data.row(i))) }
// Result = 0.0
// Result = 1.0
// Result = 1.0
// Result = 0.0
// Result = 1.0
用新的数据验证训练的成果:
val newPerson = new Mat(1, 3, CvType.CV_32FC1, new Scalar(0))
newPerson.put(0, 0, Array[Float](1.60f, 1,0))
logDebug(newPerson.dump()) // [1.6, 1, 0]
logDebug("New (woman) = {}", boost.predict(newPerson)) // New (woman) = 0.0
newPerson.put(0, 0, Array[Float](1.8f, 0,1))
logDebug(newPerson.dump()) // [1.8, 0, 1]
logDebug("New (man) = {}", boost.predict(newPerson)) // New (man) = 1.0
newPerson.put(0, 0, Array[Float](1.7f, 1,0))
logDebug(newPerson.dump()) // [1.7, 1, 0]
logDebug("New (?) = {}", boost.predict(newPerson)) // New (?) = 0.0
层级分类器
把面部识别分为两个问题:
- 目标识别,通过分类器检索到目标所在的坐标。
- 通过训练,生成一个严格的分类器。
OpenCV层级分类器(Cascade classifier)通过名为Viola-Jones 侦测器的算法实现了面部识别功能,实现了Haar-likes特性。 通过把原始图像分为不同的矩形区域,计算差异与总值,得到的阈值为基础。之后, 这些分类器还可以使用LBP特性(Local Binary Patterns), 即用取整值进行对照Haar-like特性,这样可以用更少的时间得到差不多的效果。
通过了解层级分类器的工作原理可以明白它的使用范围。基本原则是,层级分类器 擅长识别有固定不变纹理的物体。层级分类器处理一系列尺寸与直方图相同的图片, 分别标记上是否包含要检测的目标。为了最大可能地排除不包含目标的矩形, 层级分类器使用某种形式的AdaBoost过滤器作为排除层级,以尽早地排除不包含的矩形。 通过AdaBoost把多个弱分类器按不同的权值进行求和:
\[ F = sign(w_1f_1 + w_2f_2 + w_3f_3 + \cdots + w_nf_n) \]通过层层过滤留下包含目标(比如说人脸)的矩形:
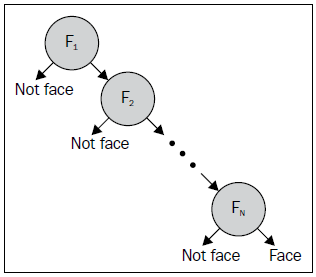
侦测目标
OpenCV内置大量训练好的层级,用来侦测目标,可以直接拿来用:
import org.opencv.objdetect.CascadeClassifier val faceDetector = new CascadeClassifier( "testdata/cascades/lbpcascade_frontalface.xml")
从图上找到目标,并用方框框起来:
def detectAndDrawFace(image: Mat, faceDetector: CascadeClassifier) {
val faceDetections = new MatOfRect();
faceDetector.detectMultiScale(image, faceDetections, 1.1, 7, 0,
new Size(250, 40), new Size());
// Draw a bounding box around each face.
for (rect <- faceDetections.toArray()) {
Imgproc.rectangle(image, new Point(rect.x, rect.y),
new Point(rect.x + rect.width, rect.y + rect.height),
new Scalar(0, 255, 0));
}
}
训练样本
训练样本分为需要包含的样本的Positive Sample和需要排除的样本的Negative Sample。
在目录opencv/build/x86/vc11/bin里有OpenCV训练用的工具,opencv_createsamples
和opencv_traincascade工具分别用于准备训练样本和生成层级过滤器。
示例代码中的cardata中放的是训练用的数据。cardata/TrainImages
里放的是由Shivani Agarwal,Aatif Awan和Dan Roth收集的汽车图片,格式为PMG。
PGM是便携式灰度图像格式(portable graymap file format),
在黑白超声图像系统中经常使用PGM格式的图像。文件的后缀名为.pgm,
PGM格式图像格式分为两类:P2和P5类型。
准备样本
与样本相配地要一个info文件cardata\cars.info,格式为:
# filename quantity rect-x rect-y rect-width rect-height TrainImages\pos-0.pgm 1 0 0 100 40 TrainImages\pos-1.pgm 1 0 0 100 40 TrainImages\pos-2.pgm 1 0 0 100 40
- 文件名
- 包含的目标数量
- 矩形范围x
- 矩形范围y
- 矩形宽度
- 矩形高度
准备好了训练文件以后,可以用opencv_createsamples来创建训练样本:
opencv_createsamples -info cars.info -num 550 -w 48 -h 24 -vec cars.vec
-
-info:info文件。 -
-num:样本的数量。 -
-vec:输出文件,是.vec格式,只是调整了样本图片的大小,不进行任何扭曲。 -
-w:输出样本的宽度。 -
-h:输出样本的高度。
训练样本
有了Positive Sample以后,再在准备Negative Sample,用来指定需要排除的目标,
Negative Sample也要用一个info文件cars-neg.info列出来,每一行只有一个文件名:
TrainImages\neg-0.pgm TrainImages\neg-1.pgm TrainImages\neg-2.pgm TrainImages\neg-3.pgm TrainImages\neg-4.pgm TrainImages\neg-5.pgm TrainImages\neg-6.pgm
再用opencv_traincascade进行训练:
opencv_traincascade -featureType LBP -numStages 10 -vec cars.vec -bg cars-neg.info -numPos 500 -numNeg 500 -w 48 -h 24 -data data
-
-featureType:类型,可以是Haar-like或是LBP。LBP可以以少许质量下降的代价换回更高的速度。 -
-numStages:指定需要训练层级阶段的数量。 -
-vec:正面训练样本所在的vec文件。 -
-bg:负面训练样本所在的vec文件。 -
-numPos:正面训练样本的数量。 -
-numNeg:负面训练样本的数量。 -
-w:训练后可以侦测到目标的最小宽度。 -
-h:训练后可以侦测到目标的最小高度。 -
-data:输出训练结果的目录。
训练的结果cascade.xml会放在-data参数指定的目录中,该目录中的其他文件都是
可以删除的临时文件。CascadeClassifier可以加载这个训练结果来侦测目标。
因为训练样本的时间可以长达数小时到数天,所以不一定要等到最终训练结果出来, 可以用以下命令得到一个中间分类器的xml文件来检验一下分类器是如何工作的:
convert_cascade --size="48x24" haarcascade haarcascade-inter.xml