Scala起步

入门
变量定义
val不可变变量;var可变变量。格式:
// 基本格式 val msg: java.lang.String = "Hello" // java.lang默认已经导入了 val msg: String = "Hello" // 自动推导类型 val msg = "Hello"
赋值没有返回值
Scala与Java不同,赋值操作是没有返回值的,所以下面的语句是错误的:
var a,b,c = 1 a = b = c
还有常用的控制结构赋值判断的形式也是不能用的:
while (null != input.readLine) { /* ... */ }
语句定义
Scala语句以分号结束,而且分号可以省略。默认一行结束了就是一行语句结束了, 除非以下三种情况,会认为语句还没有结束:
- 行尾是一个不能放在行尾的字符。
- 下一行的开头是不能放在行头的字符。
-
()和[]里,这里面不能放多条语句。
这是两个:
val s = "hello"; println(s)
if (x < 2)
println("too small")
else
println("ok")
这是两个:
x + y
一个:
(x + y)
一个:
x + y + z
注意一个容易出错的例子,
不要在repl中执行,以脚本执行上代码或用:paste贴入代码。
第一个列表赋值语句后加上了分号:
scala> :paste
// Entering paste mode (ctrl-D to finish)
val list1 = new java.util.ArrayList[Int];
{ println("Created list1") }
println(list1.getClass())
// Exiting paste mode, now interpreting.
Created list1
class java.util.ArrayList
list1: java.util.ArrayList[Int] = []
第二个没有分号的语句,
Scala解释器以为是要创建一个继承自ArrayList的匿名内部类:
scala> :paste
// Entering paste mode (ctrl-D to finish)
val list2 = new java.util.ArrayList[Int]
{ println ("created list2") }
println(list2.getClass())
// Exiting paste mode, now interpreting.
created list2
class $line4.$read$$iw$$iw$$anon$1
list2: java.util.ArrayList[Int] = []
函数定义
函数定义中的=很重要,对于有=的函数,比如下面这个比较大小的函数,函数体的最后
一行作为结果返回:
def max(x: Int, y: Int): Int = { if (x > y) x else y }
函数类型也能自动推导出来,可以省略。但在递归函数的情况下, 一定要明确地说明返回类型。
如果函数体只有一行,那花括号也可以省略:
scala> def max(x: Int, y: Int) = if (x > y) x else y max: (x: Int, y: Int)Int
类型Unit对应Java中的void。即没有参数又没有返回结果的函数定义:
scala> def greet() = println("Hello")
greet: ()Unit
Scala可以把任何类型转为Unit,以下方法最后的String类结果会转为Unit并丢弃:
scala> def f(): Unit = "This String is lost!" f: ()Unit
对于没有等号的方法来说返回类型一定是Unit。有了等号但没有类型会由编译器自动推导
:
scala> def f() { "This String is lost!" }
f: ()Unit
scala> def f() = { "This String get returned!" }
f: ()java.lang.String
scala> f
res2: java.lang.String = This String get returned!
避免显式return
Scala中默认把最后一句语句的结果作为函数的返回值。推荐不要显式地return,因为这样 就直接跳出了方法,至少会影响Scala自动推算返回类型的能力:
def check1() = true def check2(): Boolean = return true println(check1) // true println(check2) // true
对于有return语句,就是显式提供返回类型;不然编译不过。所以最好不显式用return语句 ,让编译器推断返回类型。
函数字面量(Function Literal)
函数字面量用=>来分隔参数表与函数体:
(x:Int, y:Int) => x + y
通过函数字面量来迭代处理参数的例子:
args.foreach((arg: String) => println(arg))
这里的String类型可以自动推导出来:
args.foreach(arg => println(arg))
在这种字面量只有一行而且只有一个参数情况下,可以省掉参数列表:
args.foreach(println)
for循环
scala> for (i <- 0 to 10) print(i) 012345678910
注意在for循环里每个i都是一个val而不是var。每次都创建一个新的val i。
方法与操作符
下面的语句产生一个从0到5的集合:
scala> 0 to 5 res9: scala.collection.immutable.Range.Inclusive = Range(0, 1, 2, 3, 4, 5)
其实这个to是一个方法的调用。Scala中对于方法调用时,如果方法只有一个参数的话
可以省略括号,原本的样子是:
(0).to(5)
scala中没有操作符的重载,因为操作符也是方法的名字:
1 + 2
相当于:
(1).+(2)
标识符
Scala语言规范 中定义了「\u0020-007F范围的字符
Unicode Sm [Symbol/Math]范围中除了括号与中括号[]()和点号以外的数学符号」。
例如可以用符号\(\pi\)或是美元符号:
scala> val π = 3.1415926 π: Double = 3.1415926 scala> val $ = "USD currency symbol" $: String = USD currency symbol
Scala在构成标识符方面有四种非常灵活的规则:
字母数字标识符(alphanumeric identifier)
字母数字标识符起始于一个字母或下划线,之后可以跟字母,数字,或下划线。
$也被当作是字母,但是被保留作为Scala编译器产生的标识符之用。尽管能够编译通过,
但用户程序里的标识符不应该包含美元字符。这样有可能导致与Scala编译器产生的标识符
发生名称冲撞。
Scala遵循Java的驼峰式标识符习俗。尽管下划线在标识符内是合法的,但在Scala程序里
并不常用,部分原因是为了保持与Java一致,同样也由于下划线在Scala代码里有许多其它
非标识符用法。因此,最好避免使用像to_string,__init__,或name这样的标识符
。
用下划线当标识符会引起的一个麻烦就是:如果你尝试写一个这样的定义:
val name_: Int = 1
会收到一个编译器错误。编译器会认为你正常是定义一个叫做name_:的变量。
要让它编译通过,你将需要在冒号之前插入一个额外的空格, 如:
val name_ : Int = 1
字段,方法参数,本地变量,还有函数的驼峰式名称,应该以小写字母开始,如:
length,flatMap,还有s。
类和特质的驼峰式名称应该以大写字母开始,如:BigInt,List,还有
UnbalancedTreeMap。
Scala与Java的习惯不一致的地方在于常量名。
Scala里,constant这个词并不等同于val。尽管val在被初始化之后的确保持不变,
但它还是个变量。比方说,方法参数是val,但是每次方法被调用的时候这些val都可以
代表不同的值。而常量更持久。比如scala.Math.Pi显然是个常量。
Java里习惯常量名全大写下划线分隔单词,如MAX_VALUE或PI。Scala里习惯用驼峰式
风格,如XOffset。
操作符标识符(operator identifier)
操作符字符是一些如+,:,?,~或#的可打印的ASCII字符。常见的例子:
+ ++ ::: <?> :->
Scala编译器将内部会把操作符标识符转码成包含$的合法的Java标识符。
例如,标识符:->将在内部将被表达为:
$colon$minus$greater
若你想从Java代码访问这个标识符,就应使用这个内部表达。
Scala里的操作符标识符可以有多个字符,因此在Java和Scala间有一些小差别。
Java里,输入x<-y将会被拆分成四个词汇符号,所以写成x < - y也没什么不同。Scala
里,<-将被作为一个标识符拆分,而得到x <- y。如果你想要得到Java里那样的解释,
你要在<和-字符间加一个空格。这大概不会是实际应用中的问题,因为没什么人会在
Java里写x<-y的时候不注意加空格或括号的。
混合标识符(mixed identifier)
混合标识符由字母数字组成,后面跟着下划线和一个操作符标识符。例如,unary_+
被用做定义一元的+操作符的方法名。或者,myvar_=被用做定义赋值操作符的方法名。
多说一句,混合标识符格式myvar_=是由Scala编译器产生的用来支持属性:
property的。在以后的章节「有状态对象」中进一步说明。
文本标识符(literal identifier)
文本标识符是用反引号包括的任意字串。如:
`x` `<clinit>` `yield`
在Java的Thread类中访问静态的yield方法是其典型的用例。因为yield是Scala
的保留字所以Thread.yield()是不合法的,因此在调用java的yield方法时要这样写:
Thread.`yield`()
它的思路是你可以把任何运行时认可的字串放在反引号之间当作标识符。结果总是Scala 标识符。即使包含在反引号间的名称是Scala保留字,这个规则也是有效的。
例如这样是错误的:
scala> val a.b = 25
<console>:7: error: not found: value a
val a.b = 25
^
加上反引号就可以作为正确的标识符:
scala> val `a.b` = 25 a.b: Int = 25
常用工具
数组
类型参数化数组
长度为3的数组,存放的元素类型为String:
scala> val gs: Array[String] = new Array[String](3)
gs: Array[String] = Array(null, null, null)
scala> val gs = new Array[String](3)
gs: Array[String] = Array(null, null, null)
scala> gs(0) = "aa"
scala> gs(1) = "bb"
scala> gs(2) = "cc"
scala> gs.foreach(print)
aabbcc
scala> val ns = Array("11","22","33")
ns: Array[java.lang.String] = Array(11, 22, 33)
scala> ns.foreach(print)
112233
数组的参数类型重载
My code looks like this:
val people = Array(Array("John", "25"), Array("Mary", "22"))
val headers = Seq("Name", "Age")
val myTable = new Table(people, headers)
I get this syntax error:
overloaded method constructor Table with alternatives:
(rows: Int,columns: Int)scala.swing.Table
<and>
(rowData: Array[Array[Any]],columnNames: Seq[_])scala.swing.Table
cannot be applied to
(Array [Array[java.lang.String]], Seq[java.lang.String])
I don't see why the second alternative isn't used. Is there a distinction
between Any and _ that's tripping me up here?
Array[Array[String]] is not a subtype of Array[Array[Any]] because Array's
type parameter is not covariant. This should fix it:
val people = Array(Array("John", "25"),
Array("Mary", "22")).asInstanceOf[Array[Array[Any]]];
As already said, you need to make your array covariant in his element type, because Scala's Arras are not covariant like Java's/C#'s.
This code will make it work for instance:
class Table[+T](rowData: Array[Array[T]],columnNames: Seq[_])
This just tells the compiler that T should be covariant (this is similar to Java's ? extends T or C#'s out T).
If you need more control about what types are allowed and which not, you can also use:
class Table[T <: Any](rowData: Array[Array[T]],columnNames: Seq[_])
This will tell the compiler that T can be any subtype of Any (which can be changed from Any to the class you require, like CharSequence in your example).
Both cases work the same in this scenario:
scala> val people = Array(Array("John", "25"), Array("Mary", "22"))
people: Array[Array[java.lang.String]] = Array(Array(John, 25), Array(Mary, 22))
scala> val headers = Seq("Name", "Age")
headers: Seq[java.lang.String] = List(Name, Age)
scala> val myTable = new Table(people, headers)
myTable: Table[java.lang.String] = Table@350204ce
Edit: If the class in question is not in your control, declare the type you want explicitly like this:
val people: Array[Array[Any]] =
Array(Array("John", "25"), Array("Mary", "22"))
Update
This is the source code in question:
// TODO: use IndexedSeq[_ <: IndexedSeq[Any]], see ticket [#2005][1]
def this(rowData: Array[Array[Any]], columnNames: Seq[_]) = {
数组的字符串化
因为类型擦除,不能用java.util.Arrays.toString或java.util.Arrays.deepToString()
。要用Scala的arr.mkString(",")或arr.deep.mkString(",")。
数组的常用方法
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
scala> Array(1,2,3).sum
res0: Int = 6
scala> ArrayBuffer("Mary","had","a","little","lamb").max
res1: String = little
scala> val l = ArrayBuffer(1,7,2,9)
l: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 7, 2, 9)
scala> val sl = l.sorted(_<_) // 注意是返回新的数组
ScalaDoc中的格式初学者可能难以理解,下面给出一些方法的导读:
def copyToArray[B >: A](xs: Array[B]): Unit
不同类型的数组复制,B类型必须是A的超类。
多维数组
和Java一样,通过数组的数组来实现多维数组,类型为Array[Array[Double]],可以用
ofDim方法来创建:
val matrix = Array.ofDim[Double](3, 4) // 三行四列 matrix(row)(column) = 42
通过指定每行长度不一样的方式来创建不规则数组:
val triangle = new Array[Array[Int]](10) for (i <- 0 until triangle.length) triangle(i) = new Array[Int](i + 1)
与Java互操作
Scala的数组是用Java的数组实现的,可以直接传递。
如果Java方法返回的类型是List,推荐用隐式转换。例如java.lang.ProcessBuilder类
有一个以List<String>为参数的构造器,Scala里可以这样调用:
import scala.collection.JavaConversions.bufferAsJavaList
import scala.collection.mutable.ArrayBuffer
val command = ArrayBuffer("ls", "-al", "/home/morgan")
val pb = new ProcessBuilder(command)
这样ArrayBuffer被自动转成了列表。
下面把返回的java.util.List转成Buffer,注意只能保证是Buffer,不一定是
ArrayBuffer:
import scala.collection.JavaConversions.asScalaBuffer import scala.collection.mutable.Buffer val cmd: Buffer[String] = pb.command()
apply与update方法
对一个对象的后面加上括号的操作其实是调用了这个对象的apply方法。
所以数组的元素索引操作其实是apply方法调用:
gs(0)
//相当于:
gs.apply(0)
val ns = Array("11","22","33")
//相当于:
val ns = Array.apply("11","22","33")
对带有括号并包括一到多个参数的变量赋值时,编译器使用对象的update方法对括号里的
参数(索引值)和等号右边的对象执行调用:
gs(0) = "aa" //相当于: gs.update(0, "aa")
列表
与java.util.List不同,scala.List是不可变的。不可变的对象更加符合函数式风格。
scala> val ll = List(1,2,3) ll: List[Int] = List(1, 2, 3)
::(读作cons)把一个元素加到列表的头上; 用:::连起两个列表:
scala> 0 :: ll res12: List[Int] = List(0, 1, 2, 3) scala> val ll2 = List(4,5,6) ll2: List[Int] = List(4, 5, 6) scala> ll ::: ll2 res11: List[Int] = List(1, 2, 3, 4, 5, 6)
一个元素也没有的空列表用Nil表示,作为一个空的列表,它可以把其他的元素给串起来:
scala> val nl = 1 :: 2 :: 3 :: Nil nl: List[Int] = List(1, 2, 3)
List只能把元素加在头上,如果要加在后面的话,一个方法是在加到头上以后再调用
reverse()方法;还有一个方案是使用ListBuffer,它有append()方法。
LinkedList
对于可变的链表,不能通过把next引用设置为Nil的方法将其设置为最后结点。应该是
LinkedList.empty。
DoubleLinkedList
双向链表,prev引用指向前一个节点。
List常用方法
List() 或 Nil // 空List
List("Cool", "tools", "rule") // 创建带有三个值"Cool","tools"和"rule"的新List[String]
val thrill = "Will"::"fill"::"until"::Nil // 创建带有三个值"Will","fill"和"until"的新List[String]
List("a", "b") ::: List("c", "d") // 叠加两个列表(返回带"a","b","c"和"d"的新List[String])
thrill(2) // 返回在thrill列表上索引为2(基于0)的元素(返回"until")
thrill.count(s => s.length == 4) // 计算长度为4的String元素个数(返回2)
thrill.drop(2) // 返回去掉前2个元素的thrill列表(返回List("until"))
thrill.dropRight(2) // 返回去掉后2个元素的thrill列表(返回List("Will"))
thrill.exists(s => s == "until") // 判断是否有值为"until"的字串元素在thrill里(返回true)
thrill.filter(s => s.length == 4) // 依次返回所有长度为4的元素组成的列表(返回List("Will", "fill"))
thrill.forall(s => s.endsWith("1")) // 辨别是否thrill列表里所有元素都以"l"结尾(返回true)
thrill.foreach(s => print(s)) // 对thrill列表每个字串执行print语句("Willfilluntil")
thrill.foreach(print) // 与前相同,不过更简洁(同上)
thrill.head // 返回thrill列表的第一个元素(返回"Will")
thrill.init // 返回thrill列表除最后一个以外其他元素组成的列表(返回List("Will", "fill"))
thrill.isEmpty // 说明thrill列表是否为空(返回false)
thrill.last // 返回thrill列表的最后一个元素(返回"until")
thrill.length // 返回thrill列表的元素数量(返回3)
thrill.map(s => s + "y") // 返回由thrill列表里每一个String元素都加了"y"构成的列表(返回List("Willy", "filly", "untily"))
thrill.mkString(", ") // 用列表的元素创建字串(返回"will, fill, until")
thrill.remove(s => s.length == 4) // 返回去除了thrill列表中长度为4的元素后依次排列的元素列表(返回List("until"))
thrill.reverse // 返回含有thrill列表的逆序元素的列表(返回List("until", "fill", "Will"))
thrill.sort((s, t) => s.charAt(0).toLowerCase < t.charAt(0).toLowerCase)
// 返回包括thrill列表所有元素,并且第一个字符小写按照字母顺序排列的列表(返回List("fill", "until", "Will"))
thrill.tail // 返回除掉第一个元素的thrill列表(返回List("fill", "until"))
方法关联性
所有以:结尾的方法其实是后一个操作数调用前一个操作数,所以:
0 :: ll // 其实是 ll.::(0) ll ::: ll2 // 其实是 ll2.:::(ll)
回到前面的串列表操作:
val nl = 1 :: 2 :: 3 :: Nil
如果没有最后的Nil,就变成了3.::(2)。因为数字没有::方法,这样就会报错。
元组(Tuple)
元组像列表,但可以放不同类型的元素。这样类似于Java Bean,但写起来更加简单。
元组的类型按字段个数来识别,有2个字段的就是Tuple2、3个就是Tuple3,
Scala最多支持到Tuple22:
scala> val pair = (99, "Luft") pair: (Int, java.lang.String) = (99,Luft)
创建二元组的另一个方法是使用箭头符号:
scala> val pair = 99 -> "Luft" pair: (Int, java.lang.String) = (99,Luft)
访问字段通过_序号来实现。不能像数组一样用()的原因是:如果要用apply方法,
那定义方法的时候就要声明返回类型,而同一个元组中元素的类型是不同的,
所以写不出这个apply方法。
scala> print(pair._1) 99 scala> print(pair._2) Luft
集(Set)和映射(Map)
对于Map和Set,Scala都分别提供了可变和不变的版本(放一不同的包里)。 可变版本的操作会在本地修改,不可变的版本会返回一个新的对象。 一般默认会使用不可变版本。
虽然都提供了+=()方法添加元素,但不可变实现都是返回一个新的对象。
Set
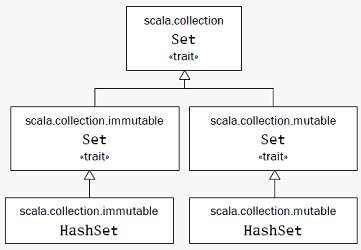
Set继承关系:
scala> var jetSet = Set("Boeing", "Airbus")
jetSet: scala.collection.immutable.Set[java.lang.String] = Set(Boeing, Airbus)
scala> jetSet += "Lear"
scala> println(jetSet.contains("Cessna"))
false
scala> println(jetSet)
Set(Boeing, Airbus, Lear)
有些情况下想要指定使用可变版本的:
scala> import scala.collection.mutable.Set
import scala.collection.mutable.Set
scala> val movieSet = Set("Hitch", "Poltergeist")
movieSet: scala.collection.mutable.Set[java.lang.String] = Set(Poltergeist, Hitch)
scala> movieSet += "Shrek"
res3: movieSet.type = Set(Shrek, Poltergeist, Hitch)
scala> println(movieSet)
Set(Shrek, Poltergeist, Hitch)
指定要使用HashSet:
scala> import scala.collection.immutable.HashSet
import scala.collection.immutable.HashSet
scala> val hashSet = HashSet("Tomatoes", "Chilies")
hashSet: scala.collection.immutable.HashSet[java.lang.String] = Set(Chilies, Tomatoes)
scala> println(hashSet + "Coriander")
Set(Chilies, Tomatoes, Coriander)
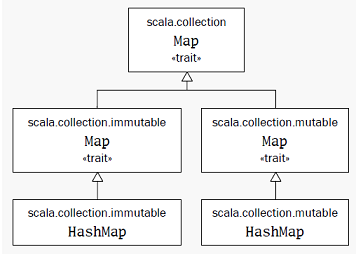
Map继承关系:
Map
默认的Map用不可变的类型:
scala> val romanNumberal = Map( 1 -> "I", 2 -> "II", 3 -> "III",
| 4 -> "IV", 5 -> "V")
romanNumberal: scala.collection.immutable.Map[Int,java.lang.String] = Map(5 -> V, 1 -> I, 2 -> II, 3 -> III, 4 -> IV)
scala> println(romanNumberal(4))
IV
使用一个可变的Map
scala> import scala.collection.mutable.Map import scala.collection.mutable.Map scala> val treasureMap = Map[Int, String]() treasureMap: scala.collection.mutable.Map[Int,String] = Map() scala> treasureMap += (1 -> "Go to inland.") res6: treasureMap.type = Map(1 -> Go to inland.) scala> treasureMap += (2 -> "Find big X on ground.") res7: treasureMap.type = Map(1 -> Go to inland., 2 -> Find big X on ground.) scala> treasureMap += (3 -> "Dig.") res8: treasureMap.type = Map(3 -> Dig., 1 -> Go to inland., 2 -> Find big X on ground.) scala> println(treasureMap(2)) Find big X on ground.
函数式风格
函数式风格极力避免使用变量(就是用到变量也尽量用val这种不可变的变量)与副作用。
典型的指令式风格
先来看一个指令式的for循环:
scala> val args = Array("11","22","33")
args: Array[java.lang.String] = Array(11, 22, 33)
scala> def printArgs(args: Array[String]): Unit = {
| var i = 0
| while (i < args.length) {
| println(args(i))
| i += 1
| }
| }
printArgs: (args: Array[String])Unit
去除变量的使用
通过去掉val的使用变得更加函数式风格:
scala> def printArgs(args: Array[String]): Unit = {
| for (arg <- args) println(arg)
| }
printArgs: (args: Array[String])Unit
当然更优雅的风格是这样的:
scala> def printArgs(args: Array[String]): Unit = {
| args.foreach(println)
| }
printArgs: (args: Array[String])Unit
去除副作用
光去掉了变量的使用还不是函数式的。因为这个打印到输出流这个操作也是副作用。
所以我们在这里把字符串的格式化与打印输出分成两个功能来做:
scala> def formatArgs(args: Array[String]) = args.mkString("\n")
formatArgs: (args: Array[String])String
scala> println(formatArgs(args))
11
22
33
这样才真正算是函数式风格。鼓励程序员尽量设计出没有副作用,没有变量的代码。
读取文本文件
一个读取文本文件的方法,统计每个行里的字符数:
import scala.io.Source
if (args.length > 0) {
for (line <- Source.fromFile(args(0)).getLines)
println(line.length + " " + line)
} else {
Console.err.println("Please enter filename")
}
执行一下:
$ scala readFile.scala readFile.scala
22 import scala.io.Source
0
22 if (args.length > 0) {
48 for (line <- Source.fromFile(args(0)).getLines)
35 println(line.length + " " + line)
8 } else {
45 Console.err.println("Please enter filename")
1 }
执行的结束不错,但是没有排版……强化一下,先遍历一次得到最长的统计参数。
import scala.io.Source
def widthOfLength(s: String) = s.length.toString.length
if (args.length > 0) {
val lines = Source.fromFile(args(0)).getLines.toList
/* 找到最长的一行,不用for循环, 显得更加函数式一些 */
val longestLine = lines.reduceLeft(
(a, b) => if (a.length > b.length) a else b)
val maxWidth = widthOfLength(longestLine)
for (line <- lines) {
val numSpaces = maxWidth - widthOfLength(line)
val padding = " " * numSpaces
println(padding + line.length + " | " + line)
}
} else {
Console.err.println("Please enter filename")
}
输出格式为:
$ scala readFile.scala readFile.scala
22 | import scala.io.Source
0 |
55 | def widthOfLength(s: String) = s.length.toString.length
0 |
22 | if (args.length > 0) {
53 | val lines = Source.fromFile(args(0)).getLines.toList
0 |
36 | val longestLine = lines.reduceLeft(
45 | (a, b) => if (a.length > b.length) a else b
2 | )
42 | val maxWidth = widthOfLength(longestLine)
0 |
22 | for (line <- lines) {
48 | val numSpaces = maxWidth - widthOfLength(line)
31 | val padding = " " * numSpaces
47 | println(padding + line.length + " | " + line)
2 | }
8 | } else {
45 | Console.err.println("Please enter filename")
1 | }
基本类型
基本类型包括java.lang包下的String和scala包下的Byte、Short、Int、
Long、Float、Double、Char、Boolean。
还有在scala.runtime包下对应的包装器类Rich...。
如:Int对应的包装器类型为scala.runtime.RichInt。
基本类型转换
高精度类型的to<Type>方法可以把高精度类型转为低精度基本类型:
scala> val pi = 3.1415926 pi: Double = 3.1415926 scala> pi.toFloat res1: Float = 3.1415925
字符串
除了和Java一样的字符串字面量表示方式以外,Scala还提供了原始字符串(raw string) 方便照原文解读:
println("""Welcome to Ultamix 3000.
Type "HELP" for help.""")
输出的内容包括所有的转义字符和空格:
Welcome to Ultamix 3000.
Type "HELP" for help.
有些情况下希望在源代码里也能排版提好看一点,所以字符串里提供stripMargin
方法可以通过管道符|来取得想要的部分:
println("""|Welcome to Ultamix 3000.
|Type "HELP" for help.""".stripMargin)
结果:
Welcome to Ultamix 3000. Type "HELP" for help.
而:
scala> println(""" \| hello
| |aa|aa.""".stripMargin)
结果:
\| hello
aa|aa.
如果管道符号|有别的作用,可以用stripMargin()方法的变体来设置其他的边缘(
margin)符号。
字符串还支持乘法操作:
scala> "Na " * 16 + "Batman!" res2: String = Na Na Na Na Na Na Na Na Na Na Na Na Na Na Na Na Batman!
字符串插值
Scala从版本2.11开始,字符串插值可以用$变量名的格式进行格式化字符串工作。
如果要输入$,
那个就用两个来转义$$。
字符串插值三种形式:
s前缀的字符串插值
字符串s前缀还可以结合取值与printf风格的格式控制:
scala> val name = "unmi"
name: String = unmi
scala> s"Hello $name" // 使用变量
res0: String = Hello unmi
scala> s"This is ${name}'s pen." // 大括号分隔变量名与文本
res1: String = This is unmi's pen.
scala> s"1 + 1 = ${1 + 1}" // 还可以用表达式
res2: String = 1 + 1 = 2
scala> class Person(val name: String) {
| def say(what: String) = s"Say: $what"
| }
defined class Person
scala> val person = new Person("Unmi")
person: Person = Person@7a791b66
scala> s"Hello ${person.name}, ${person.say(person.name)}"
res3: String = Hello Unmi, Say: Unmi
f前缀的字符串插值
字符串f前缀可以用printf风格指定变量显示的格式:
scala> val height=1.9d height: Double = 1.9 scala> val name="James" name: String = James scala> println(f"$name%s is $height%2.2f meters tall") James is 1.90 meters tall
f插值器是类型安全的。如果试图向只支持int的格式化串传入一个double值,
编译器则会报错。
f插值器利用了java中的字符串数据格式。
这种以%开头的格式在[Formatter javadoc]中有相关概述。
如果在具体变量后没有%,则格式化程序默认使用%s(串型)格式。
raw 插值器
而raw插值器会忽略转义字符:
scala>raw"a\nb" res1:String=a\nb
当不想输入\n被转换为回车的时候,raw插值器是非常实用的。
StringContext类
除了以上三种字符串插值器外,使用者可以自定义插值器。
StringContext隐式类为字符串增加了插值功能,具体方法见:
相关文档。
Scala会预处理所以的字符串字面量。例如:
id"String content"
都会被替换成以下形式:
StringContext.call(id)
这个方法在隐式范围内仍然可用。只要建立一个隐式类,给StringContext
实例添加一个新的方法。例如,定义自己的字符串插值类:
// 注意:为了避免运行时实例化,我们从AnyVal中继承。
// 更多信息请见值类的说明
implicit class JsonHelper(val sc:StringContext) extends AnyVal {
def json(args:Any*): JSONObject = {
val strings = sc.parts.iterator
val expressions = args.iterator
var buf = new StringBuffer(strings.next)
while (strings.hasNext) {
buf append expressions.next
buf append strings.next
}
parseJson(buf)
}
}
该方法的功能是把编译器遇到的:
"{name: $name, id:$id"}"
都重写为:
new StringContext("{name: ", " id: ", "}").json(name, id)
隐式类则被重写为:
new JsonHelper(new StringContext("{name: ", " id: ", "}")).json(name, id)
符号
格式为'symb,这里的symb可以是任何字母或数字。这种字面量被直接映射为类
scala.Symbol的实例,解释器调用apply工厂方法Symbol("symb")产生。
例,符号'id是scala.Symbol("id")的简写形式。
符号可以包含空格,如Symbol("Programming Scala")中的空格也是符号的一部分。
符号变量是被限定(interned)的,如果同一个字面量出现两次,
其实指向的是同一个Symble实例。
符号变量什么事情都做不了,只能显示自己的名字:
scala> val s = 'aSymbol s: Symbol = 'aSymbol scala> s.name res3: String = aSymbol
那符号能用来干嘛?典型应用是作为动态语言中的标签符。比如说,
下面的函数用来更新记录,两个参数field是字段名、value是值:
scala> def updateRecordByName(field: Symbol, value: Any){ }
updateRecordByName: (field: Symbol, value: Any)Unit
Scala是静态语言,所以不可以随便写一个标识符:
scala> updateRecordByName(pcOK, "OK Computer")
<console>6: error : not fount: value pcOK
updateRecordByName: (field: Symbol, value: Any)Unit
这是就要用到符号了:
scala> updateRecordByName('pcOK, "OK Computer")
操作符与方法
操作符也是普通方法的另一种写法。方法可以当操作符写;操作符也可以当作方法写; 操作符的重载也就是方法的重载。
这引出了另一个问题:既然Scala没有操作符,那么操作符的优先级特性怎么实现的呢?
其实Scala定义了方法的优先级。
中缀操作符(infix)
scala> val s = "Hello, world!"
s: java.lang.String = Hello, world!
scala> s indexOf 'o'
res6: Int = 4
scala> s indexOf ('o', 5)
res7: Int = 8
前缀操作符
前缀操作符只能有四个:+、-、!、~。
定义方法以unary_开头。也就是unary_+、unary_-、unary_!、unary_~
这四个分别对应+、-、!、~。
scala> - 2.0 res8: Double = -2.0 scala> (2.0).unary_- res9: Double = -2.0
其他的符号就算定义了也不能作为前置操作符解释,如果定义了p.unary_*,在调用
*p会被Scala解释为*.p。
后缀操作符
后缀操作符其实就是没有参数的函数。一般习惯上有副作用的话就加上括号,如:
println();如果没有副作用就不加括号,如:String.toLowerCase
scala> "Hello".toLowerCase res10: java.lang.String = hello scala> "Hello" toLowerCase res11: java.lang.String = hello
没有参数的成员方法推荐只省略(),不要省略.。不然的话代码可读性差:
scala> "Hello".toString() // 调用成员方法 scala> "Hello".toString // 方法看起来像是属性,但不影响阅读 scala> "Hello" toString // 这样的代码就比较难读懂
Scala在2.10版本以后可以开启警告,防止这种可读性比较差的代码出现:
$ scala -feature // 打开feature新特性
...
scala> 1 toString
<console>:12: warning: postfix operator toString should be enabled
by making the implicit value scala.language.postfixOps visible.
This can be achieved by adding the import clause 'import scala.language.postfixOps'
or by setting the compiler option -language:postfixOps.
See the Scaladoc for value scala.language.postfixOps for a discussion
why the feature should be explicitly enabled.
1 toString
^
res1: String = 1
scala> import scala.language.postfixOps // 导入后缀操作符语法
import scala.language.postfixOps // 另一种方法是编译器的开关: -language:postfixOps
scala> 1 toString // 不显示警告了
res2: String = 1
位操作
位与&、位或|、位异或^,还有一元前缀操作符取位补码~(定义就是前面说过的
unary_~)。
左移<<(填零)、右移>>(填符号位)、无符号右移>>>(填零)。
对象相等性
操作符==与!=与Java中的不同,更加像Java中的equals比较是内容的含意是否相等。
而且在Scala中不仅比较基本类型,也可以比较对象,甚至是不同类的对象也可以比较,
也可以和null比不会有异常抛出:
scala> 1 == 2
res12: Boolean = false
scala> 1 != 2
res13: Boolean = true
scala> List(1, 2, 3) == List(1, 2, 3)
res14: Boolean = true
scala> List(1, 2, 3) == List(4, 5, 6)
res15: Boolean = false
scala> 1 == 1.0
res16: Boolean = true
scala> List(1, 2, 3) == "hello"
res17: Boolean = false
scala> List(1, 2, 3) == null
res18: Boolean = false
scala> null == List(1, 2, 3)
res19: Boolean = false
scala> ("he" + "llo") == "hello"
res20: Boolean = true
而且与Java中==和!=类似的比较是否是同一个实例的操作分别是eq和ne。