特质
特质(Traits)
trait是Scala里代码复用的基础单元。特质封装了方法和字段的定义,并可以通过混入到 类中重用它们。
抽象与实现
特质中的字段可以是抽象的也可以是抽象的。
实现字段
如果字段有初始值,就是已经实现的字段。
字段不可被再次继承
因为JVM中不可多重继承,所以特质中的字段只能作为混入类中的一个不能被子类继承的 成员。
抽象字段
如果字段没有初始值,就是抽象字段。它们必须被实现。
抽象方法
默认抽象
特质中没有实现的方法默认作为抽象方法,不用abstract修饰:
trait Logger {
def log(msg: String)
}
不用override
实现特质中的抽象方法不用加override:
class ConsoleLogger extends Logger {
def log(msg: String) { println(msg) }
}
实现方法
定义,关键字trait:
trait Philosophical {
def philosophize() {
println("I consume memory, therefore I am!")
}
}
需要重新编译
如果特质带有具体实现,那么这个特质一旦改变,所有已经混入该特质的类必须重新编译。
扩展类与对象
扩展特质的匿名类
在合建实例时,可以直接用类混入特质,产生只用一次的匿名类:
scala> class User(val name: String) {
| def suffix = ""
| override def toString = s"$name$suffix"
| }
defined class User
scala> trait Student
defined trait Student
scala> trait Teacher
defined trait Teacher
scala> new User("Leo") with Student
res3: User with Student = Leo
scala> new User("Adda") with Teacher
res4: User with Teacher = Adda
单例对象也可以扩展特质
不止是类,单例对象也可以扩展特质。
类层级
没有声明超类,因此和类一样,有个缺省的超类AnyRef。一旦特质被定义了,就可以使用
with关键字,把它混入到类中。如果这个类没有继承基类,可以直接用extends关键字
来混入特质:
class Frog extends Philosophical {
override def toString = "green"
}
类Frog是AnyRef(Philosophical的超类)的子类并混入了Philosophical。从特质
继承的方法可以像从超类继承的方法那样使用:
scala> val frog = new Frog frog: Frog = green scala> frog.philosophize() I consume memory, therefore I am!
特质同样也是类型。以下是把Philosophical用作类型的例子:
scala> val phil: Philosophical = frog phil: Philosophical = green scala> phil.philosophize() I consume memory, therefore I am!
phil的类型是Philosophical,一个特质。因此,变量phil可以被初始化为任何混入
了Philosophical特质的类的实例。
如果想把特质混入到显式扩展超类的类里,可以用extends指明待扩展的超类,用with
混入特质:
class Animal
class Frog extends Animal with Philosophical {
override def toString = "green"
}
如果想混入多个特质,都加在with子句里就可以了:
class Animal
trait HasLegs
class Frog extends Animal with Philosophical with HasLegs {
override def toString = "green"
}
目前为止你看到的例子中,类Frog都继承了Philosophical的philosophize实现。
或者,Frog也可以重载philosophize方法。语法与重载超类中定义的方法一样。
举例如下:
class Animal
class Frog extends Animal with Philosophical {
override def toString = "green"
override def philosophize() {
println("It ain't easy being "+ toString +"!")
}
}
因为Frog的这个新定义仍然混入了特质Philosophize,你仍然可以把它当作这种类型的
变量使用。但是由于Frog重载了Philosophical的philosophize实现,当你调用它的
时候,你会得到新的回应:
scala> val phrog: Philosophical = new Frog phrog: Philosophical = green scala> phrog.philosophize() It ain't easy being green!
特质继承
抽象方法延迟绑定
如果重写了特质中的抽象方法,要加上abstract修饰。
特质中的方法是抽象的:
trait Logger {
def log(msg: String)
}
在实现子类特质的时候,调用的相对父类的方法还是抽象的,所以下而的代码是编译不过 的:
trait TimestampLogger extends Logger {
override def log(msg: String) {
super.log(new java.util.Date() + " " + msg) // super.log()还是抽象的,错误
}
}
声明为抽象的方法中有一个super调用。这种调用对于普通的类来说是非法的,因为继承
的超类是个抽象类,所以在执行时将必然失败。然而对于特质来说,这样的调用实际能够
成功。因为特质里的super调用是动态绑定的,特质的super调用将直到被混入在另一个
特质或类之后,有了具体的方法定义时才工作。
所以要加上abstract override,说明要继承父特质(只有特质,类里是不能这样写的)
才能实际产生作用。
trait TimestampLogger extends Logger {
abstract override def log(msg: String) {
super.log(new java.util.Date() + " " + msg)
}
}
再来看一个例子:
在基类方法为抽象时情况比较复杂。比如下面这个抽象Writer类的抽象方法
writeMessage():
abstract class Writer {
def writeMessage(message: String)
}
这样在特质中一定要修饰方法为abstract override,这里两个特质的功能分别是转大写
与过滤敏感词:
trait UpperCaseWriter extends Writer {
abstract override def writeMessage(message: String) =
super.writeMessage(message.toUpperCase)
}
trait ProfanityFilteredWriter extends Writer {
abstract override def writeMessage(message: String) =
super.writeMessage(message.replace("stupid","s-----"))
}
特质的实现里调用了super.writeMessage(...),这样的调用要延迟绑定,以后混入这些
特质的类需要提供这个方法的实现。实现类如下:
class StringWriterDelegate extends Writer {
val writer = new java.io.StringWriter
def writeMessage(message: String) = writer.write(message)
override def toString(): String = writer.toString
}
混入特质并调用:
val wa = new StringWriterDelegate with UpperCaseWriter with ProfanityFilteredWriter val wb = new StringWriterDelegate with ProfanityFilteredWriter with UpperCaseWriter wa writeMessage "There is no sin except stupidity" wb writeMessage "There is no sin except stupidity" println(wa) println(wb)
输出结果:
THERE IS NO SIN EXCEPT S-----ITY THERE IS NO SIN EXCEPT STUPIDITY
特质也可以继承自类
IntQueue类有一个put方法把整数添加到队列中,和一个get方法移除并返回它们:
abstract class IntQueue {
def get(): [[Int]]
def put(x: Int)
}
BasicIntQueue类根据上面的特质实现了一个队列:
import scala.collection.mutable.ArrayBuffer
class BasicIntQueue extends IntQueue {
private val buf = new ArrayBuffer[Int]
def get() = buf.remove(0)
def put(x: Int) { buf += x }
}
运行一个队列的效果:
scala> val queue = new BasicIntQueue queue: BasicIntQueue = BasicIntQueue@24655f scala> queue.put(10) scala> queue.put(20) scala> queue.get() res9: Int = 10 scala> queue.get() res10: Int = 20
Doubling特质继承自类IntQueue,它把整数放入队列的时候对它加倍。
trait Doubling extends IntQueue {
abstract override def put(x: Int) { super.put(2 * x) }
}
特质只能混入基类的子类
定义了超类IntQueue这个定义意味着特质只能混入到扩展了IntQueue的类中。
还有前面提到的抽象绑定:
声明为抽象的方法中有一个super调用。这种调用对于普通的类来说是非法的,因为继承
的超类是个抽象类,所以在执行时将必然失败。然而对于特质来说,这样的调用实际能够
成功。因为特质里的super调用是动态绑定的,特质Doubling的super调用将直到被
混入在另一个特质或类之后,有了具体的方法定义时才工作。
所以要加上abstract override,说明要继承父特质(只有特质,类里是不能这样写的)
才能实际产生作用。
现在一行代码都不用写,下面只有一个extends和一个with就把类定义好了:
scala> class MyQueue extends BasicIntQueue with Doubling defined class MyQueue scala> val queue = new MyQueue queue: MyQueue = MyQueue@91f017 scala> queue.put(10) scala> queue.get() res12: Int = 20
这个队列即能入队出队,而且数字还是加倍的。
还可以更加简化到类名都不用写,直接new BasicIntQueue with Doubling这个父类名加
上特质就可以把实例拿到了:
scala> val queue = new BasicIntQueue with Doubling queue: BasicIntQueue with Doubling = $anon$1@5fa12d scala> queue.put(10) scala> queue.get() res14: Int = 20
特质的超类会成为类的超类
之前讨论过特质可以继承自类,那我们就从Exception扩展一个特质出来:
trait LoggedException extends Exception with Logged {
def log() { log(getMessage()) }
}
这里的getMessage方法是从Exception继承下来的。接下来把这个特质混入一个类中:
class UnhappyException exteds LoggedException {
override def getMessage() = "arggh!"
}
现在特质LoggedException的超类Exception是UnhappyException的超类,对于生成的
Java类来说:
-
UnhappyException实现了LoggedException接口 -
UnhappyException继承了Exception类
只能有一个超类
因为Java没有多继承,所以类的超类和特质的超类不能关联到不同的类:
class UnhappyFrame extends JFrame with LoggedException
不能同时把JFrame和Exception作为超类。
但如果类的超类是特质超类的子类就没有问题:
class UnhappyException extends IOException with LoggedException
保证特质能调用到需要的方法
以记录异常log为例:
trait LoggedException {
def log() { log(getMessage()) } // error
}
我们要保证LoggerException混入的类要有getMessage()方法,因为在log()方法中
会调用到它。
为了保证特质一定能调用到指定的方法(如:getMessage),可以有两种方案:
-
特质扩展自指定的类(如:
Exception) -
用自身类型限制只能混入指定的类(如:
Exception)
如果特质是扩展子一个类B,那么所以混入这个特质的类都可以作为B的子类。
自身类型
Scala还可以通过自身类型(self type),限制只能被混入到指定的类中:
this: MyType =>
注意这里的标识符this可以换成其他的标识符(不成文的规则是使用self,
这样即能表示自身的意思,也不会和自身引用的那个this混淆)。
作用:
-
如果
MyType是一个类,保证特质只能被混入MyType的子类中。 -
如果
MyType是一个特质,相当之前也要混入这个类。
scala> class User(val name: String) {
| def suffix = ""
| override def toString = s"$name$suffix"
| }
defined class User
scala> trait Attorney { self: User => override def suffix = " , esq." }
defined trait Attorney
scala> trait Wizard { self: User => override def suffix = " , Wizard." }
defined trait Wizard
scala> trait Reverser { self: User => override def toString = super.toString.reverse }
defined trait Reverser
scala> new User("Harry Potter") with Wizard
res0: User with Wizard = Harry Potter , Wizard.
scala> new User("Ginny W") with Attorney
res1: User with Attorney = Ginny W , esq.
scala> new User("Luna L") with Wizard with Reverser
res2: User with Wizard with Reverser = .draziW , L anuL
例子,要根据现有的日志工具类Logged扩展出一个适用于异常日志的LoggedException
:
trait LoggedException extends Logged {
this: Exception =>
def log() { log(getMessage()) }
}
因为限制在Exception的子类中,所以可以保证肯定会有getMessage()方法。
通过this: Type来限制类型比继承超类的版本更加灵活。可以避免两个彼此需要的特质
循环依赖。
自身类型不会继承
前面的LoggedException的自身类型并不会继承给子类,如果它有子类要再次声明自身
类型:
trait ManagedException extends LoggedException {
this: Exception =>
...
}
this的别名
如果把this改成别的名字那么在子类中还可以使用这个别名。如:
trait Group {
outer: Network =>
class Member { ... }
}
这里把this改成outer。Grout特质只能在Network的子类中,而在Member中,
可以用outer来代替Group.this。
自身类型也可以不给出类名,而用结构类型(structural type)来说明要有指定方法:
trait LoggedException extends Logged {
this: { def getMessage(): String} =>
def log() { log(getMessage()) }
}
这样就可以混入任何有getMessage方法的类了。
trait LoggedException extends Logged {
this: { def getMessage(): String }=>
def log() { log(getMessage()) }
}
混入多个特质
混入多个特质的类型被称作复合类型。如果想混入多个特质,都加在with子句里就可以了
:
class Animal
trait HasLegs
class Frog extends Animal with Philosophical with HasLegs {
override def toString = "green"
}
在容器的类型参数里也可以这样用:
val image = new ArrayBuffer[java.awt.Shape with java.io.Serializable]
存放的成员必须是满足这两个条件的类型,如Rectangle
image += new Rectangle(5, 10, 20, 30) // OK image += new Area(rect) // error Area类型不是Serializable的
结构类型也可添加到简单类型或是复合类型的声明中:
val image = new ArrayBuffer[Shape with Serializable { def contains(p: Point): Boolean } ]
上面的定义不仅要是Shape和Serializable,还要有一个contains()方法。
从技术上来说,如下的结构类型:
AnyRef { def append(str: String): Any }
可以简写为:
{ def append(str: String): Any }
这样的复合类型:
Shape with Serializable {}
可以简写为:
Shape with Serializable
特质的super引用是动态的
类和特质的另一个差别在于:在类中任何地方,super调用都是静态绑定的,在特质中
,它们是动态绑定的。如果你在类中写下super.toString,你很明确哪个方法实现将被
调用。然而如果你在特质中写了同样的东西,在你定义特质的时候super调用的方法实现
尚未被定义。调用的实现将在每一次特质被混入到具体类的时候才被决定。这种处理
super的有趣的行为是使得特质能以可堆叠的改变(stackable modifications)方式
工作的关键。
特质的叠加栈
有两个特质,一个在入队时把值加1;另一个过滤掉负数:
trait Incrementing extends IntQueue {
abstract override def put(x: Int) { super.put(x + 1) }
}
trait Filtering extends IntQueue {
abstract override def put(x: Int) {
if (x >= 0) super.put(x)
}
}
队列能够即过滤负数又对每个进队列的数字增量:
scala> val queue = (new BasicIntQueue
| with Incrementing with Filtering)
queue: BasicIntQueue with Incrementing with Filtering...
scala> queue.put(-1); queue.put(0); queue.put(1)
scala> queue.get()
res15: Int = 1
scala> queue.get()
res16: Int = 2
粗略地说,越靠近右侧的特质越先起作用。如果那个方法调用了super,它调用其左侧
特质的方法,以此类推。
前面的例子里,Filtering的put首先被调用,因此它移除了开始的负整数。
Incrementing的put第二个被调用,因此它对剩下的整数增量。
如果你逆转特质的次序,那么整数首先会加1,然后如果仍然是负的才会被抛弃:
scala> val queue = (new BasicIntQueue
| with Filtering with Incrementing)
queue: BasicIntQueue with Filtering with Incrementing...
scala> queue.put(-1); queue.put(0); queue.put(1)
scala> queue.get()
res17: Int = 0
scala> queue.get()
res18: Int = 1
scala> queue.get()
res19: Int = 2
指定调用特质栈
除了用super.method()调用下个特质,还可以用super[traid].method()来调用指定
具体特质。注意指定的一定是直接一级,不能使用继承层级中更远的特质类。
特质的构造过程
特质构造器
特质构造器是由字段初始化和其他特质体中的语句构成的。特质所混入对象被构造时,这些 语句被执行。顺序为:
- 调用超类的构造器
- 特质构造器在超类构造器之后,当前类的构造器之前执行
- 特质从左到右被构造,每个特质的你特质先被构造。
- 如果多个特质共有一个你特质,而且父特质已经被构造过了,不会再次构造
- 所有特质构造完毕,当前类构造器被执行
特质不能有构造器参数
特质不能有任何「类」参数,也就是说,传递给类的主构造器的参数。换句话说, 尽管你可以定义如下的类:
class Point(x: Int, y: Int)
预初始化字段
由于特质不能有参数,所以要用别的方法在初始化时传入值。
比如,不能有参数,所以用以下的方法指定日志文件是不行的:
val acct = new SavingAccount with FileLogger("mylog.log")
另一个方案:
用抽象字段filenam来存文件名,这样混入这个特质的类可以重写这个字段:
trait FileLogger extends Logger {
val filename: String
val out = new PrintStream(filename)
def long(msg: String) { out.println(msg); out.flush() }
但是由于特质的构造器比当前类更先执行,所以特质构造时取得的filename还是没有被
子类初始化,抛出空指针异常。
有效的解决方案有两个:
- 预初始化字段。
- 懒加载。
应用于实例
把初始化块放在new之后:
val acct = new {
val filename = "mylog.log"
} with SavingAccount whith FileLogger
应用于类
初始化块放在extends前:
clas SavingAccount extends {
val filename = "mylog.log"
} with Account with FileLogger {
// ...
}
懒加载
除了预初始化外的另一个方案是懒加载:
trait FileLogger extends Logger {
val filename: String
lazy val out = new PrintStream(filename)
def long(msg: String) { out.println(msg); out.flush() }
}
初始化输出流的操作只有在用到out时才执行。
Scala特质生成Java接口
只有抽象方法
只有抽象方法的特质简单地转为Java接口。
Scala特质:
trait Logger {
def log(msg: String)
}
生成的接口:
public interface Logger {
void log(String msg);
}
有方法实现的情况
会创建一个伴生类,它的静态方法里存放特质的方法。
trait ConsoleLogger exteds Logger {
def log(msg: String) { println(msg) }
}
转换成:
public interface ConsoleLogger extends Logger {
void log(String msg);
}
伴生类:
public class ConsoleLogger$class {
public static void log(ConsoleLogger self, String msg) {
println(msg);
}
// ...
}
特质中的字段
伴生类中不会有字段,字段对应的getter和setter方法加入到实现了特质的类中:
trait ShortLogger extends Logger {
val maxLength = 15
// ...
}
被翻译成:
public interface ShortLogger extends Logger {
public abstract int maxLength();
public abstract void weird_prefix$maxLength_$eq(int);
// ...
}
以weird开头的setter方法是用来初始化字段的。初始化发生在伴生类的一个初始化
方法内:
public class ShortLogger$class {
public void $init$(ShortLogger self) {
self.weired-prefix$maxLength_$eq(15)
}
// ...
}
被混入的类会有带getter和setter的maxLength字段,上面的构造器会被调用以初始
化字段。
如果特质扩展自某个超类,则伴生类并不继承这个超类。该超类会被任何实现该特质的类 继承。
特质与类的差异
特质就像是带有具体方法的Java接口,不过其实它能做的更多。比方说,特质可以声明字段 和维持状态值。
实际上,你可以用特质定义做任何用类定义做的事,并且语法也是一样的,除了两点:
- 特质不能有构造器参数。
-
特质的
super引用是动态的。
比如是下面定义特质有构造参数,所以不能通过编译:
trait NoPoint(x: Int, y: Int) // Does not compile
应用场景
为什么不是多重继承
特质是一种继承多个类似于类的结构的方式,但是它与许多语言中的多重继承有很重要的
差别。其中的一个尤为重要:super的解释。对于多重继承来说,super调用导致的方法
调用可以在调用发生的地方明确决定。而对于特质来说,方法调用是由类和被混入到类的
特质的线性化(linearization)所决定的。这种差别让前一节所描述的改动的堆叠成为
可能。
在关注线性化之前,请花一点儿时间考虑一下在传统的多重继承语言中如何堆叠改动。假想 有下列的代码,但是这次解释为多重继承而不是特质混入:
val q = new BasicIntQueue with Incrementing with Doubling q.put(42) // which put would be called?
第一个问题是,哪个put方法会在这个调用中被引用?或许规则会决定最后一个超类胜出
,本例中的Doubling将被调用。Doubling将加倍它的参数并调用super.put,大概
就是这样。增量操作将不会发生!同样,如果规则决定第一个超类胜出,那么结果队列将
增量整数但不会加倍它们。因此怎么排序都不会有效。
或许你会满足于允许程序员显式地指定在他们说super的时候他们想要的到底是哪个超类
方法。比方说,假设下列Scala类似代码,super似乎被显式地指定为Incrementing和
Doubling调用:
trait MyQueue extends BasicIntQueue
with Incrementing with Doubling {
def put(x: Int) {
Incrementing.super.put(x) // (Not real Scala)
Doubling.super.put(x)
}
}
这种方式将带给我们新的问题。这种尝试的繁冗几乎不算是问题。实际会发生的是基类的
put方法将被调用两次——一次带了增量的值另一次带了加倍的值,但是没有一次是带了
增量加倍的值。
显然使用多重继承对这个问题来说没有好的方案。你不得不返回到你的设计并分别提炼出
代码。相反,Scala里的特质方案很直接。你只要简单地混入Incrementing和Doubling
,Scala对super的特别照顾让它迎刃而解。这与传统的多重继承相比必然有不同的地方
,但这是什么呢?
就像在前面暗示的,答案就是线性化。当你使用new实例化一个类的时候,Scala把这个类
和所有它继承的类还有它的特质以线性(linear)的次序放在一起。然后,当你在其中的
一个类中调用super,被调用的方法就是链子的下一节。除了最后一个调用super之外的
方法,其净结果就是可堆叠的行为。
线性化的精确次序由语言的规格书描述。虽然有一点儿复杂,但你需要知道的主旨就是,在
任何的线性化中,某个类总是被线性化在所有其超类和混入特质之前。因此,当你写了一个
调用super的方法时,这个方法必将改变超类和混入特质的行为,没有其它路可走。
Scala的线性化的主要属性可以用下面的例子演示:假设你有一个类Cat,继承自超类
Animal以及两个特质Furry和FourLegged。FourLegged又扩展自另一个特质
HasLegs:
class Animal trait Furry extends Animal trait HasLegs extends Animal trait FourLegged extends HasLegs class Cat extends Animal with Furry with FourLegged
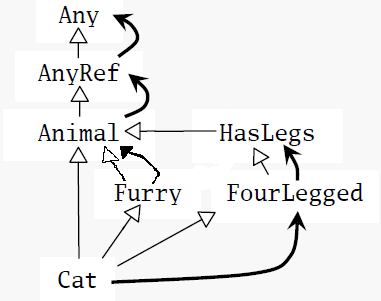
类型的线性化看起来是这样的:
Animal : Any < AnyRef < Animal
Furry : Any < AnyRef < Animal < Furry
HasLegs : Any < AnyRef < Animal < HasLegs
FourLegged : Any < AnyRef < Animal < HasLegs < FourLegged
Cat : Any < AnyRef < Animal < Furry < HasLegs < FourLegged < Cat
因为Animal没有显式扩展超类或混入任何超特质,因此它缺省地扩展了AnyRef,并
随之扩展了Any。
Animal : Any < AnyRef < Animal
第二部分是第一个混入,特质Furry的线性化,但是所有已经在Animal的线性化之中的
类现在被排除在外,因此Cat的线性化中每个类仅出现1次。结果是:
Furry : Any < AnyRef < Animal < Furry
它之前是FourLegged的线性化,任何已被复制到线性化中的超类及第一个混入再次被排除
在外:
FourLegged : Any < AnyRef < Animal < HasLegs < FourLegged
最后,Cat线性化的第一个类是Cat自己:
当这些类和特质中的任何一个通过super调用了方法,那么被调用的实现将是它线性化的
右侧的第一个实现。
Cat : Any < AnyRef < Animal < Furry < HasLegs < FourLegged < Cat
比较瘦接口与胖接口
瘦接口与胖接口的对阵体现了面向对象设计中常会面临的在实现者与接口用户之间的权衡。
胖接口有更多的方法,对于调用者来说更便捷。客户可以捡一个完全符合他们功能需要的 方法。另一方面瘦接口有较少的方法,对于实现者来说更简单。然而调用瘦接口的客户因此 要写更多的代码。由于没有更多可选的方法调用,他们或许不得不选一个不太完美匹配他们 所需的方法并为了使用它写一些额外的代码。
Java的接口常常是过瘦而非过胖。例如,从Java 1.4开始引入的CharSequence接口,是
对于字串类型的类来说通用的瘦接口,它持有一个字符序列。下面是把它看作Scala特质的
定义:
trait CharSequence {
def charAt(index: Int): Char
def length: Int
def subSequence(start: Int, end: Int): CharSequence
def toString(): String
}
尽管类String里现有的成打的方法中的大多数都可以用在任何CharSequence上,Java的
CharSequence接口定义仅提供了4个方法。如果CharSequence代以包含全部String
接口,那它将为CharSequence的实现者压上沉重的负担。任何实现JavaCharSequence
接口的程序员将不得不定义一大堆方法。因为Scala特质可以包含具体方法,这使得创建
胖接口大为便捷。
在特质中添加具体方法使得胖瘦对阵的权衡大大倾向于胖接口。不像在Java里那样,在 Scala中添加具体方法是一次性的劳动。你只要在特质中实现方法一次,而不再需要在每个 混入特质的方法中重新实现它。因此,与没有特质的语言相比,Scala里的胖接口没什么 工作要做。
要使用特质丰满接口,只要简单地定义一个具有少量抽象方法的特质——特质接口的瘦部分—— 和潜在的大量具体方法,所有的都实现在抽象方法之上。然后你就可以把丰满了的特质混入 到类中,实现接口的瘦部分,并最终获得具有全部胖接口内容的类。
什么情况下要用特质
没有固定的规律,但是包含了几条可供考虑的导则。
如果行为不会被重用,那么就把它做成具体类。具体类没有可重用的行为。
如果要在多个不相关的类中重用,就做成特质。只有特质可以混入到不同的类层级中。
如果你希望从Java代码中继承它,就使用抽象类。因为特质和它的代码没有近似的Java模拟 ,在Java类里继承特质是很笨拙的。而继承Scala的类和继承Java的类完全一样。除了一个 例外,只含有抽象成员的Scala特质将直接翻译成Java接口,因此即使你想用Java代码继承 ,也可以随心地定义这样的特质。要了解让Java和Scala一起工作的更多信息请看后面其他 的章节。
注意:如果你计划以编译后的方式发布它,并且你希望外部组织能够写一些继承自它的类, 你应更倾向于使用抽象类。原因是当特质获得或失去成员,所有继承自它的类就算没有改变 也都要被重新编译。如果外边客户仅需要调用行为,而不是继承自它,那么使用特质没有 问题。
如果效率非常重要,倾向于类。大多数Java运行时都能让类成员的虚方法调用快于接口方法 调用。特质被编译成接口,因此会付出微小的性能代价。然而,仅当你知道那个存疑的特质 构成了性能瓶颈,并且有证据说明使用类代替能确实解决问题,才做这样的选择。
例子
样例:长方形实例
为了使这些长方形实例便于使用,如果库能够提供诸如width,height,left,
right,topLeft,等等方法。
没有特质的代码的话,首先会有一些基本的集合类如Point和Rectangle:
class Point(val x: Int, val y: Int)
class Rectangle(val topLeft: Point, val bottomRight: Point) {
def left = topLeft.x
def right = bottomRight.x
def width = right - left
// and many more geometric methods...
}
这个Rectangle类在它的主构造器中带两个点,分别是左上角和右下角的坐标。然后它
通过对这两个点执行简单的计算实现了许多便捷方法诸如left,right,和width。
图库应该有的另一个类是2-D图像工具:
abstract class Component {
def topLeft: Point
def bottomRight: Point
def left = topLeft.x
def right = bottomRight.x
def width = right - left
// and many more geometric methods...
}
注意left,right,和width在两个类中的定义是一模一样。除了少许的变动外,他们
将在任何其他的长方形实例的类中保持一致。
这种重复可以使用特质消除。这个特质应该具有两个抽象方法:一个返回实例的左上角坐标 ,另一个返回右下角的坐标。然后他就可以应用到所有其他的几何查询的具体实现中:
trait Rectangular {
def topLeft: Point
def bottomRight: Point
def left = topLeft.x
def right = bottomRight.x
def width = right - left
// and many more geometric methods...
}
类Component可以混入这个特质并获得Rectangular提供的所有的几何方法:
abstract class Component extends Rectangular {
// other methods...
}
可以创建Rectangle实例并对它调用如width或left的几何方法:
scala> val rect = new Rectangle(new Point(1, 1),
| new Point(10, 10))
rect: Rectangle = Rectangle@3536fd
scala> rect.left
res2: Int = 1
scala> rect.right
res3: Int = 10
scala> rect.width
res4: Int = 9
实现Ordered特质来排序
以前面我们实现的实数类型来说,原来已经有了四个比较大小的方法:
class Rational(n: Int, d: Int) {
// ...
def < (that: Rational) =
this.numer * that.denom > that.numer * this.denom
def > (that: Rational) = that < this
def <= (that: Rational) = (this < that) || (this == that)
def >= (that: Rational) = (this > that) || (this == that)
}
Scala专门提供了Ordered特质来简化比较工作。只要实现Ordered特质中的compare
方法,就可以自动实现其他的<、>、<=、>=功能:
class Rational(n: Int, d: Int) extends Ordered[Rational] {
// ...
def compare(that: Rational) =
(this.numer * that.denom) - (that.numer * this.denom)
}
上面定义compare方法来比较两个实例,类Rational现在具有了所有4种比较方法:
scala> val half = new Rational(1, 2) half: Rational = 1/2 scala> val third = new Rational(1, 3) third: Rational = 1/3 scala> half < third res5: Boolean = false scala> half > third res6: Boolean = true
考虑下面的抽象简化了四个比较操作符的实现:
trait Ordered[T] {
def compare(that: T): Int
def <(that: T): Boolean = (this compare that) < 0
def >(that: T): Boolean = (this compare that) > 0
def <=(that: T): Boolean = (this compare that) <= 0
def >=(that: T): Boolean = (this compare that) >= 0
}