集合
集合类型
概览
scala包中主要特质Iterable,三个子特质:
-
Seq:有序集合。 -
Set:对于==方法不可重复的元素集合。 -
Map:键值映射。
特技Iterable有个抽象方法elements:
def elements: Iterator[A]
注意返回类型是一个迭代器iterator,不是iterate别看错了!
迭代器用来从头到尾遍历一遍集合。如果要再遍历一遍的话,只能用elements方法再生成
一个新的迭代器。。
迭代器Iterator继承自AnyRef。Iterator提供的具体方法都实现了next和
hasNext抽象方法实现:
def hasNext: Boolean def next: A
序列
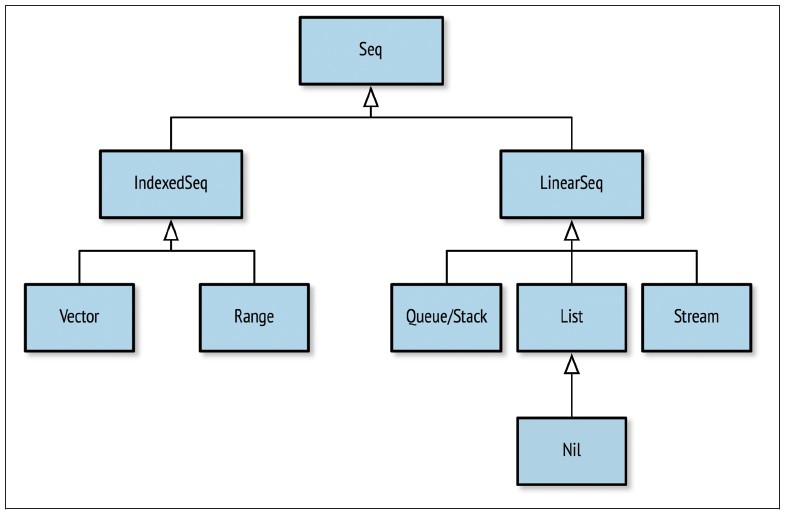
Seq是List()的快捷方式,IndexedSeq是Vector()的快捷方式:
scala> Seq("a", "b", "c")
res0: Seq[String] = List(a, b, c)
scala> List("a", "b", "c")
res1: List[String] = List(a, b, c)
scala> IndexedSeq("a", "b", "c")
res2: IndexedSeq[String] = Vector(a, b, c)
scala> Vector("a", "b", "c")
res3: scala.collection.immutable.Vector[String] = Vector(a, b, c)
列表
列表不能通过索引直接访问元素,只能遍历;但可以支持在头上快速添加和删除。这点像是 链式表。使用模式匹配的方式可以很好地在头上快速添加和删除元素。
但是因为只能对列表头快速访问,而尾部不行。所以如果要操作尾部的话可以先建一个反序
的列表,再reverse把顺序反过来。
列表缓存
还有一个方式是使用scala.collection.mutable.ListBuffer。
+=在尾部添加元素;+:加在头上;完成之后用toList生成List:
scala> import scala.collection.mutable.ListBuffer
import scala.collection.mutable.ListBuffer
scala> val buf = new ListBuffer[Int]
buf: scala.collection.mutable.ListBuffer[Int] = ListBuffer()
scala> buf += 1
scala> buf += 2
scala> buf
res11: scala.collection.mutable.ListBuffer[Int]
= ListBuffer(1, 2)
scala> 3 +: buf
res12: scala.collection.mutable.Buffer[Int]
= ListBuffer(3, 1, 2)
scala> buf.toList
res13: List[Int] = List(3, 1, 2)
List结合前置添加元素和递归算法增长列表时,如果用的递归算法不是尾递归,就有栈
溢出的风险;而ListBuffer可以结合循环替代递归。
数组
数组适合按索引快速访问元素。
按长度产数组:
scala> val fiveInts = new Array[Int](5) fiveInts: Array[Int] = Array(0, 0, 0, 0, 0)
按元素产数组:
scala> val fiveToOne = Array(5, 4, 3, 2, 1) fiveToOne: Array[Int] = Array(5, 4, 3, 2, 1)
通过()指定索引:
scala> fiveInts(0) = fiveToOne(4) scala> fiveInts res1: Array[Int] = Array(1, 0, 0, 0, 0)
数组缓存
ArrayBuffer可以在头尾添加元素,但在尾部的添加移除是高效的。常见的用法是先用
ArrayBuffer构建然后用它的toArray方法生成不可变的数组:
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
scala> val buf = new ArrayBuffer[Int]()
buf: scala.collection.mutable.ArrayBuffer[Int] =
ArrayBuffer()
scala> buf += 12
scala> buf += 15
scala> buf
res16: scala.collection.mutable.ArrayBuffer[Int] =
ArrayBuffer(12, 15)
scala> buf.length
res17: Int = 2
scala> buf(0)
res18: Int = 12
队列
不可变的队列:
scala> import scala.collection.immutable.Queue import scala.collection.immutable.Queue scala> val empty = new Queue[Int] empty: scala.collection.immutable.Queue[Int] = Queue() // add one element scala> val has1 = empty.enqueue(1) has1: scala.collection.immutable.Queue[Int] = Queue(1) // use collection to add many elements scala> val has123 = has1.enqueue(List(2, 3)) has123: scala.collection.immutable.Queue[Int] = Queue(1,2,3) scala> val (element, has23) = has123.dequeue element: Int = 1 has23: scala.collection.immutable.Queue[Int] = Queue(2,3)
注意上面取后一个出队操作dequeue返回的是一个二元组,包括出来的元素和剩下的队列
。
可变的队列也差不多,就是用+=和++=添加元素,dequeue方法只返回一个出除的元素。
scala> import scala.collection.mutable.Queue
import scala.collection.mutable.Queue
scala> val queue = new Queue[String]
queue: scala.collection.mutable.Queue[String] = Queue()
scala> queue += "a"
scala> queue ++= List("b", "c")
scala> queue
res21: scala.collection.mutable.Queue[String] = Queue(a, b, c)
scala> queue.dequeue
res22: String = a
scala> queue
res23: scala.collection.mutable.Queue[String] = Queue(b, c)
栈
可变的栈:
scala> import scala.collection.mutable.Stack import scala.collection.mutable.Stack scala> val stack = new Stack[Int] stack: scala.collection.mutable.Stack[Int] = Stack() scala> stack.push(1) scala> stack res1: scala.collection.mutable.Stack[Int] = Stack(1) scala> stack.push(2) scala> stack res3: scala.collection.mutable.Stack[Int] = Stack(1, 2) scala> stack.top res8: Int = 2 scala> stack res9: scala.collection.mutable.Stack[Int] = Stack(1, 2) scala> stack.pop res10: Int = 2 scala> stack res11: scala.collection.mutable.Stack[Int] = Stack(1)
不可变的栈略。
字符串
因为Predef包含了从String到RichString的隐式转换,所以可以把任何字符串当作
Seq[Char]。
scala> def hasUpperCase(s: String) = s.exists(_.isUpperCase)
hasUpperCase: (String)Boolean
scala> hasUpperCase("Robert Frost")
res14: Boolean = true
scala> hasUpperCase("e e cummings")
res15: Boolean = false
exists方法不在String里,所以隐匿转换为包含exists方法的RichString类。
Set与Map
因为Predef对象通过type关键字指定默认引用了Set与Map的不可变版本:
object Predef {
type Set[T] = scala.collection.immutable.Set[T]
type Map[K, V] = scala.collection.immutable.Map[K, V]
val Set = scala.collection.immutable.Set
val Map = scala.collection.immutable.Map
// ...
}
所以可变版的要手动声明:
scala> import scala.collection.mutable import scala.collection.mutable scala> val mutaSet = mutable.Set(1, 2, 3) mutaSet: scala.collection.mutable.Set[Int] = Set(3, 1, 2)
使用Set
Set的关键在于用对象的==检查唯一性。
例子:统计出现的单词
用正则[ !,.]+分隔成单词:
scala> val text = "See Spot run. Run, Spot. Run!"
text: java.lang.String = See Spot run. Run, Spot. Run!
scala> val wordsArray = text.split("[ !,.]+")
wordsArray: Array[java.lang.String] =
Array(See, Spot, run, Run, Spot, Run)
建立Set并存入:
scala> val words = mutable.Set.empty[String]
words: scala.collection.mutable.Set[String] = Set()
scala> for (word <- wordsArray)
| words += word.toLowerCase
scala> words
res25: scala.collection.mutable.Set[String] =
Set(spot, run, see)
常用方法:
| val nums = Set(1, 2, 3) | 建立集合 |
| nums + 5 | 添加元素 |
| nums - 3 | 去除元素 |
| nums ++ List(5, 6) | 添加多个元素 |
| nums -- List(1, 2) | 去除多个元素 |
| nums ** Set(1, 3, 5, 7) | 交集(返回Set(1,3)) |
| nums.size | |
| nums.contains(3) | |
| import scala.collection.mutable | 引入可变的 |
| val words = mutable.Set.empty[String] | 创建空的可变集 |
| words += "the" | |
| words -= "the" | |
| words ++= List("do", "re", "mi") | |
| words --= List("do", "re") | |
| words.clear | 清空所有元素 |
Map
使用可变的Map:
scala> val map = mutable.Map.empty[String, Int]
map: scala.collection.mutable.Map[String,Int] = Map()
scala> val map = mutable.Map.empty[String, Int]
map: scala.collection.mutable.Map[String,Int] = Map()
scala> map("hello") = 1
scala> map("there") = 2
scala> map
res28: scala.collection.mutable.Map[String,Int] =
Map(hello -> 1, there -> 2)
scala> map("hello")
res29: Int = 1
统计单词出现次数的例子:
scala> def countWords(text: String) = {
| val counts = mutable.Map.empty[String, Int]
| for (rawWord <- text.split("[ ,!.]+")) {
| val word = rawWord.toLowerCase
| val oldCount =
| if (counts.contains(word)) counts(word)
| else 0
| counts += (word -> (oldCount + 1))
| }
| counts
| }
countWords: (String)scala.collection.mutable.Map[String,Int]
scala> countWords("See Spot run! Run, Spot. Run!")
res30: scala.collection.mutable.Map[String,Int] =
Map(see -> 1, run -> 3, spot -> 2)
常用方法:
| val nums = Map("i"->1, "ii"->2) | 创建不可变 |
| nums + ("vi"->6) | |
| nums - "ii" | |
| nums ++ List("iii"->3, "v"->5) | |
| nums -- List("i", "ii") | |
| nums.size | |
| nums.contains("ii") | |
| nums("ii") | |
| nums.keys | 返回key迭代器 |
| nums.keySet | 返回key的集合(Set) |
| nums.values | 返回value迭代器 |
| nums.isEmpty | 返回value的集合(Set) |
| import scala.collection.mutable | 引入可变的版本 |
| val words = mutalbe.Map.empty[String, Int] | |
| words += ("one"->1) | |
| words -= "one" | |
| words ++= List("one"->1, "two"->2, "three"->3)) | |
| words --= List("one", "two") |
默认的Set和Map
不可变的Set与Map会根据元素的数量优化一些工厂方法,这样返回的类就不一定是指定的 类型。
不可变的scala.collection.immutable.Set()工厂方法返回:
| 元素的数量 | 实现 |
|---|---|
| 0 | scala.collection.immutable.EmptySet |
| 1 | scala.collection.immutable.Set1 |
| 2 | scala.collection.immutable.Set2 |
| 3 | scala.collection.immutable.Set3 |
| 4 | scala.collection.immutable.Set4 |
| >=5 | scala.collection.immutable.HashSet |
不可变的scala.collection.immutable.Map()工厂方法返回:
| 元素的数量 | 实现 |
|---|---|
| 0 | scala.collection.immutable.EmptyMap |
| 1 | scala.collection.immutable.Map1 |
| 2 | scala.collection.immutable.Map2 |
| 3 | scala.collection.immutable.Map3 |
| 4 | scala.collection.immutable.Map4 |
| >=5 | scala.collection.immutable.HashMap |
Map的遍历操作
import scala.collection.JavaConversions.propertiesAsScalaMap
def printJavaProperties() = {
val properties: scala.collection.Map[String, String] = System.getProperties()
val maxLength = properties.keySet.map(_.length).max
for ((key, value) <- properties) {
print(key)
print(" " * (maxLength - key.length))
print("|")
println(value)
}
}
Scala与Java中的Map相互转换
// 从Java Map到Scala Map,适用于可变树形映射 import scala.collection.JavaConversions.mapAsScalaMap // 从Java Properties到Scala Map import scala.collection.JavaConversions.propertiesAsScalaMap // 从Scala Map到Java Map import scala.collection.JavaConversions.mapAsJavaMap
有序的集体和映射
TreeSet和TreeMap分别实现了SortedSet和SortedMap特质。都用红黑树保存元素,
顺序由Ordered特质决定。这些类只有不可变的版本:
scala> import scala.collection.immutable.TreeSet
import scala.collection.immutable.TreeSet
scala> val ts = TreeSet(9, 3, 1, 8, 0, 2, 7, 4, 6, 5)
ts: scala.collection.immutable.SortedSet[Int] =
Set(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> val cs = TreeSet('f', 'u', 'n')
cs: scala.collection.immutable.SortedSet[Char] = Set(f, n, u)
scala> import scala.collection.immutable.TreeMap
import scala.collection.immutable.TreeMap
scala> var tm = TreeMap(3 -> 'x', 1 -> 'x', 4 -> 'x')
tm: scala.collection.immutable.SortedMap[Int,Char] =
Map(1 -> x, 3 -> x, 4 -> x)
scala> tm += (2 -> 'x')
scala> tm
res38: scala.collection.immutable.SortedMap[Int,Char] =
Map(1 -> x, 2 -> x, 3 -> x, 4 -> x)
同步的Set和Map
把SynchronizedMap特质混入到实现中。下面单例对象中的makeMap方法:
import scala.collection.mutable.{Map,
SynchronizedMap, HashMap}
object MapMaker {
def makeMap: Map[String, String] = {
new HashMap[String, String] with
SynchronizedMap[String, String] {
override def default(key: String) =
"Why do you want to know?"
}
}
}
上面的方法会返回一个HashMap并且重写了default方法在没有对应的key时有默认的返回。
单线程访问的情况如下:
scala> val capital = MapMaker.makeMap
capital: scala.collection.mutable.Map[String,String] = Map()
scala> capital ++ List("US" -> "Washington",
| "Paris" -> "France", "Japan" -> "Tokyo")
res0: scala.collection.mutable.Map[String,String] =
Map(Paris -> France, US -> Washington, Japan -> Tokyo)
scala> capital("Japan")
res1: String = Tokyo
scala> capital("New Zealand")
res2: String = Why do you want to know?
scala> capital += ("New Zealand" -> "Wellington")
scala> capital("New Zealand")
res3: String = Wellington
类似地,也可以实现同步的Set:
val synchroSet =
new mutable.HashSet[Int] with
mutable.SynchronizedSet[Int]
可变与不可变集合的比较
可变集合与不可变集合对照:
| 不可变集合类型 | 可变集合类型 |
|---|---|
| collection.immutable.List | collection.mutable.Buffer |
| collection.immutable.Set | collection.mutable.Set |
| collection.immutable.Map | collection.mutable.Map |
为了方便在可变与不可变类型之间地转换,Scala提供了一些语法糖。
如,不可变类型不支持+=操作:
scala> val people = Set("Nancy", "Jane")
people: scala.collection.immutable.Set[java.lang.String] =
Set(Nancy, Jane)
scala> people += "Bob"
<console>:6: error: reassignment to val
people += "Bob"
^
但是如果把变量从val改成var,Scala还是可以返回一个添加后的新对象来模拟:
scala> var people = Set("Nancy", "Jane")
people: scala.collection.immutable.Set[java.lang.String] =
Set(Nancy, Jane)
scala> people += "Bob"
scala> people
res42: scala.collection.immutable.Set[java.lang.String] =
Set(Nancy, Jane, Bob)
类似的还有其他的操作:
scala> people -= "Jane"
scala> people ++= List("Tom", "Harry")
scala> people
res45: scala.collection.immutable.Set[java.lang.String] =
Set(Nancy, Bob, Tom, Harry)
这样的语法糖方便在可变与不可变类型之间转换:
var capital = Map("US" -> "Washington", "France" -> "Paris")
capital += ("Japan" -> "Tokyo")
println(capital("France"))
import scala.collection.mutable.Map // only change needed!
var capital = Map("US" -> "Washington", "France" -> "Paris")
capital += ("Japan" -> "Tokyo")
println(capital("France"))
这样的语法糖还可以用在其他类型上。如浮点:
scala> var roughlyPi = 3.0 roughlyPi: Double = 3.0 scala> roughlyPi += 0.1 scala> roughlyPi += 0.04 scala> roughlyPi res48: Double = 3.14
基本上+=、-=、*=这类以=结尾的操作符都可以。
初始化集合
最典型的是用伴生对象的工厂方法:
scala> List(1, 2, 3)
res0: List[Int] = List(1, 2, 3)
scala> Set('a', 'b', 'c')
res1: scala.collection.immutable.Set[Char] = Set(a, b, c)
scala> import scala.collection.mutable
import scala.collection.mutable
scala> mutable.Map("hi" -> 2, "there" -> 5)
res2: scala.collection.mutable.Map[java.lang.String,Int] =
Map(hi -> 2, there -> 5)
scala> Array(1.0, 2.0, 3.0)
res3: Array[Double] = Array(1.0, 2.0, 3.0)
会根据工厂方法推断类型:
scala> import scala.collection.mutable
import scala.collection.mutable
scala> val stuff = mutable.Set(42)
stuff: scala.collection.mutable.Set[Int] = Set(42)
scala> stuff += "abracadabra"
<console>:7: error: type mismatch;
found : java.lang.String("abracadabra")
required: Int
stuff += "abracadabra"
^
但是可以手动声明类型:
scala> val stuff = mutable.Set[Any](42) stuff: scala.collection.mutable.Set[Any] = Set(42)
还有一种情况,不能直接把List传递给Set的工厂方法:
scala> val colors = List("blue", "yellow", "red", "green")
colors: List[java.lang.String] =
List(blue, yellow, red, green)
scala> import scala.collection.immutable.TreeSet
import scala.collection.immutable.TreeSet
scala> val treeSet = TreeSet(colors)
<console>:6: error: no implicit argument matching
parameter type (List[java.lang.String]) =>
Ordered[List[java.lang.String]] was found.
val treeSet = TreeSet(colors)
^
可行的方案是建立空的TreeSet[String]对象并用TreeSet的++操作把元素加进去:
scala> val treeSet = TreeSet[String]() ++ colors
treeSet: scala.collection.immutable.SortedSet[String] =
Set(blue, green, red, yellow)
数组与列表之间转换
scala> treeSet.toList res54: List[String] = List(blue, green, red, yellow) scala> treeSet.toArray res55: Array[String] = Array(blue, green, red, yellow)
由于实现机制是一个一个元素地复制,所以元素多的话速度会慢。
Set与Map的可变与不可变互转
在转为不可变类型时,一般是建一个空的不可变集,再一个一个加上去:
scala> import scala.collection.mutable
import scala.collection.mutable
scala> treeSet
res5: scala.collection.immutable.SortedSet[String] =
Set(blue, green, red, yellow)
scala> val mutaSet = mutable.Set.empty ++ treeSet
mutaSet: scala.collection.mutable.Set[String] =
Set(yellow, blue, red, green)
scala> val immutaSet = Set.empty ++ mutaSet
immutaSet: scala.collection.immutable.Set[String] =
Set(yellow, blue, red, green)
scala> val muta = mutable.Map("i" -> 1, "ii" -> 2)
muta: scala.collection.mutable.Map[java.lang.String,Int] =
Map(ii -> 2, i -> 1)
scala> val immu = Map.empty ++ muta
immu: scala.collection.immutable.Map[java.lang.String,Int] =
Map(ii -> 2, i -> 1)
元组
元组可以存放不同的类型:
(1, "hello", Console)
元组经常被用来返回多个函数结果,如下面的函数要同时返回单词和索引:
def longestWord(words: Array[String]) = {
var word = words(0)
var idx = 0
for (i <- 1 until words.length)
if (words(i).length > word.length) {
word = words(i)
idx = i
}
(word, idx)
}
scala> val longest =
| longestWord("The quick brown fox".split(" "))
longest: (String, Int) = (quick,1)
然后可以访问各个元素:
scala> longest._1 res56: String = quick scala> longest._2 res57: Int = 1
还可以赋值给自己的变量(其实就是模式匹配):
scala> val (word, idx) = longest word: String = quick idx: Int = 1 scala> word res58: String = quick
注意括号不能去掉,不然就是给两个变量赋值了两份:
scala> val word, idx = longest word: (String, Int) = (quick,1) idx: (String, Int) = (quick,1)
惰性求值
迭代器
迭代器相对于集合来说是一个惰性求值的替代品,不会为没有取得的元素消耗资源。
流
迭代器有个缺点:只能一个方向向后走。如果需要访问已经走过元组,可以用流来实现。
流可以是有限的也可以是无限的,有限集合的流以Stream.Empty结尾。
scala> def inc(i: Int): Stream[Int] = Stream.cons(1, inc(i + 1)) inc: (i: Int)Stream[Int]
流是一个不可变的列表,但尾部的元素是被惰性求值的,只有用到时才会被计算。
已经算出来的部分被缓存,不会重复计算,还没有计算的部分用?来表示:
scala> val s = inc(1) s: Stream[Int] = Stream(1, ?)
通过take方法取指定个数的成员:
scala> val lst1 = s.take(5) lst1: scala.collection.immutable.Stream[Int] = Stream(1, ?)
take并不计算结果,返回的是一个有5个元素的新流,而只有第一个元素被计算出来:
scala> lst1 res25: scala.collection.immutable.Stream[Int] = Stream(1, ?) scala> s res26: Stream[Int] = Stream(1, ?)
但是当把结果转换为列表时,前5个元素被计算出来了, 同样原始的流也有5个元素被计算出来了:
scala> lst1.toList res27: List[Int] = List(1, 2, 3, 4, 5) scala> lst1 res28: scala.collection.immutable.Stream[Int] = Stream(1, 2, 3, 4, 5) scala> s res29: Stream[Int] = Stream(1, 2, 3, 4, ?)
还有语法糖,操作符#::用于构造一个流,例:
scala> def numsFrom(n: BigInt): Stream[BigInt] = n #:: numsFrom(n + 1) numsFrom: (n: BigInt)Stream[BigInt]
它所产生的流对象尾部的内容都是未知的:
scala> val tenOrMore = numsFrom(10) tenOrMore: Stream[BigInt] = Stream(10, ?)
在被使用到时才会求值,如用tail来取下一个值:
scala> tenOrMore.tail.tail.tail res0: scala.collection.immutable.Stream[BigInt] = Stream(13, ?)
对应的操作也是惰性求值的:
scala> val squares = numsFrom(1).map(x => x * x) squares: scala.collection.immutable.Stream[scala.math.BigInt] = Stream(1, ?)
可用tail来取下一个元素,也可用take(num)来取多个元素,再用force强制计算这些
结果:
scala> squares.take(5).force res0: scala.collection.immutable.Stream[scala.math.BigInt] = Stream(1, 4, 9, 16, 25)
警告:因为之前定义的numsFrom()方法是一个无限递归的方法,所以是一定要在force
前加上take(num)限制个数。
用迭代器创建流
Iterator.toStream方法可以创建一个流,例:
文本文件:
11111 22222 33333 44444 55555 66666 77777 88888
scala> val words = Source.fromFile("tmp/test.txt").getLines.toStream
words: scala.collection.immutable.Stream[String] = Stream(11111, ?)
scala> words
res3: scala.collection.immutable.Stream[String] = Stream(11111, ?)
scala> words(5)
res4: String = 66666
scala> words
res5: scala.collection.immutable.Stream[String] = Stream(11111, 22222, 33333, 44444, 55555, 66666, ?)
懒视图
对于集合类型,可以使用它们的view方法来取得一个懒求值的集合版本。
例:
scala> import scala.math._ import scala.math._ scala> val powers = (0 until 1000).view.map(pow(10, _)) powers: scala.collection.SeqView[Double,Seq[_]] = SeqViewM(...)
对于流来说,第一个元素会求出值,而上面的视图中连第一个值也没有求出。
下面的代码求出的是pow(10,100):
scala> powers(100) res0: Double = 1.0E100
集合中其他的值并没有被计算。注意这里和流不一样,得到的结果不会被缓存,如果再次 调用,得到的值还是一样的:
scala> powers(100) res0: Double = 1.0E100
和流一样可用force方法强制求值。
应用场景
懒集合常见的应用场景是当需要以多种方式进行变换的大型集合,因为它省去了构建大型 中间集合的操作。
例:
scala> (0 to 1000).map(pow(10, _)).map(1 / _) res2: scala.collection.immutable.IndexedSeq[Double] = Vector(1.0, 0.1, ...
这里会先对每个元素按\(10^n\)建立一个集合,在这个集合的基础上再对每个元素执行 \(\frac{1}{n}\)。
如果是以懒视图,就只会在用到中间值时才会计算中间值。相当于就是对每个元素连续执行 两个操作:
scala> (0 to 1000).view.map(pow(10, _)).map(1 / _).force res3: Seq[Double] = Vector(1.0, 0.1, 0.01, 0.001, 1.0E-4, 1.0E-5 ...
常用的类型转换操作
-
格式化为字符串:
List(1, 2, 3).mkString(",") -
输出为字符串:
List(1, 2, 3).toString -
不可变集合的可变版本:
List(1, 2, 3).toBuffer -
集合转为List:
Map("a" -> 1, "b" -> 2).toList -
把元素为二元组的集合转为Map:
Set("a" -> 1, "b" -> 2).toMap -
把集合转为Set:
List(1, 2, 3).toSet
与Java集合互操作
collection.JavaConverters
Scala集合与Java集合相互转换:
scala> import collection.JavaConverters._ import collection.JavaConverters._ scala> List(1, 2, 3).asJava res5: java.util.List[Int] = [1, 2, 3] scala> new java.util.ArrayList(5).asScala res6: scala.collection.mutable.Buffer[Nothing] = Buffer()
scala.collection.JavaConversions
JavaConversions对象提供了很多工具:
scala> import scala.collection.JavaConversions._
也可以只导入指定的转换方法:
scala> import scala.collection.JavaConversions.propertiesAsScalaMap
import scala.collection.JavaConversions.propertiesAsScalaMap
scala> val props: scala.collection.mutable.Map[String, String] =
| System.getProperties()
props: scala.collection.mutable.Map[String,String] =
这里转换出来的props是包装器。它会调用Java对象的接口。
props("com.horstmann.scala") = "impatient"
实际会调用Java中Properties对象的方法put("com.horstmann.scala","impatient")。
Scala集合转Java
| 隐式转换函数 | 从scala.collection | 到java.util |
|---|---|---|
| asJavaCollection | Iterable | Collection |
| asJavaIterable | Iterable | iterable |
| asjavaIterator | Iterator | Iterator |
| asJavaEnumeration | Iterator | Enumeration |
| seqAsJavaList | Seq | List |
| mutableSeqAsjavaList | mutable.Seq | List |
| bufferAsJavaList | mutable.Buffer | List |
| setAsJavaSet | Set | Set |
| mutableSetAsJavaMap | mutable.Set | Set |
| mapAsJavaMap | Map | Map |
| mutableMapAsJavaMap | mutable.Map | Map |
| asJavaDirectionary | Map | Dictionary |
| asJavaCurrentMap | mutable.CurrentMap | concurrent.ConcurrentMap |
从Java集合到Scala集合
| 方法 | 从java.util | 到scala.collection |
|---|---|---|
| collectionAsScalaIterable | Collection | Iterable |
| iterableAsScalaIterable | Iterable | Iterable |
| asScalaIterator | Iterator | Iterator |
| enumerationAsScalaIterator | Enumeration | Iterator |
| asScalaBuffer | List | mutable.Buffer |
| asScalaSet | Set | mutable.Set |
| mapAsScalaMap | Map | mutable.Map |
| dictionaryAsScalaMap | Dictionary | mutable.Map |
| propertiesAsScalaMap | Properties | mutable.Map |
| asScalaConcurrentMap | concurrent.ConcurrentMap | mutable.ConcurrentMap |
线程安全的集合
Scala类库提供的六个特质,混入它们就可以让集合操作变成同步:
- SynchronizedBuffer
- SynchronizedMap
- SynchronizedPriorityQueue
- SynchronizedQueue
- SynchronizedSet
- SynchronizedStack
例,得到一个同步的对象:
scala> val scores = new scala.collection.mutable.HashMap[String, Int] with
| scala.collection.mutable.SynchronizedMap[String, Int]
scores: scala.collection.mutable.HashMap[String,Int] with scala.collection.mutable.SynchronizedMap[String,Int] = Map()
并发操作集合
par方法会把一个集合的遍历操作分成多个段并行操作,多个段的结果汇总在一起。
如,统计偶数个数:
scala> val coll = 0 until 100 scala> coll.par.count(_ % 2 == 0) res6: Int = 50
通过下面的例子可以看出,顺序是并行执行的:
scala> for (i <- (0 until 100).par) print( i + ", ") 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 56, 57, 58, 59, 60, 61, 50, 51, 52, 53, 54, 55,
for-yield循环按顺序执行
但是在for-yield循环中是按顺序执行的:
scala> for (i <- (0 until 100).par) yield i res8: scala.collection.parallel.immutable.ParSeq[Int] = ParVector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99)
不要用共享变量
绝对不要这样写,结果不要预知:
var count = 0
for (c <- coll.par) { if (c % 2 == 0) count += 1 }
ParIterable接口
par方法返回的并行集合类型扩展自ParIterable接口的子接口,如ParSeq、ParSet
或ParMap特质。
注意Parable不是Iterable的子类型,所以不能把并行集合传递给Iterable、Seq
、set与Map,但可以用ser方法转过去。还可以传递给通用的类型GenIterable、
GenSeq、GenSet、GenMap
适用范围
并不是所有的方法都可以并行化,因为有些操作关系到操作顺序。
reduce
reduceLeft和reduceRight是顺序相关的。
reduce方法无关顺序,但具体执行的操作可能与顺序相关。如:\((a+b)+c = a+(b+c)\),
但是\((a-b)-c \neq a-(b-c)\)。
fold
fold方法的两个操作参数必须都是当前集合的成员,如:coll.par.fold(0)(_ + _),
不能进行如foldLeft和foldRight该当那样更加复杂的折叠操作。
aggregate
解决方案是用aggregate方法将操作应用于于集合的不同部分,然后再用另一个操作符
组合各部分的结果。例:
str.par.aggregate(Set[Char]())(_ + _, _ ++ _)
等同于:
str.foldLeft(Set[Char]())(_ + _)
产出的结果是一个str里所有不同的字符集。