泛型
泛型
类型参数
泛型类
Scala通过[T]指定类型参数:
scala> class Pair[T, S](val first: T, val second: S) defined class Pair
通过传入构造器的参数类型可以推导出生成的实例类型: aaa
scala> val p = new Pair(42, "String") p: Pair[Int,String] = Pair@2f63e9a1
也可以手动指定实例类型:
scala> val p2 = new Pair[Any, Any](42, "String") p2: Pair[Any,Any] = Pair@7ffccfe3
泛型方法
方法的类型参数加了方法名后:
scala> def getMiddle[T](a: Array[T]) = a(a.length /2) getMiddle: [T](a: Array[T])T
也能按参数类型可以推导出生成的实例类型:
scala> getMiddle(Array("Marry","had","a","little","lamb"))
res0: String = a
或显式指定类型:
scala> val f = getMiddle[String] _
f: Array[String] => String = <function1>
scala> f(Array("Marry","had","a","little","lamb"))
res1: String = a
泛型必须指定类型
类型化参数能实现编写泛型类和特质。Scala中的泛型实例都应该写明具体类型(如:
Set[Int],Set[Int]) ,而不像Java中可以不带泛型类型。
例如:对于容器类来说,成员的类型很重要:
scala> import java.util._ import java.util._ scala> var la = new ArrayList[Any] la: java.util.ArrayList[Any] = [] scala> var lb = new ArrayList[String] lb: java.util.ArrayList[String] = [] scala> var ln = new ArrayList ln: java.util.ArrayList[Nothing] = []
注意没有类型参数的类型被定为了ArrayList[Nothing]。而Nothing是所有类的子类,
所以Queue特质创建实例时一定要加类型参数:
scala> def doesNotCompile(q: Queue) {}
<console>:5: error: trait Queue takes type parameters
def doesNotCompile(q: Queue) {}
当然AnyRef也是一种类型:
scala> def doesCompile(q: Queue[AnyRef]) {}
doesCompile: (Queue[AnyRef])Unit
中置类型
带两个类型参数的类型可以用中置语法表示,如:
Map[String, Int]
可以写为:
String Map Int
以数学表达式:
\[ A \times B = \{ (a,b) | a \in A, b \in B \} \]
为例,它表示从A与B两个范围中生成的对偶的集。Scala中对偶是用(A,B)表示的。如果
想用更加数学的风格来表现对偶,可以定义:
type ×[A, B] = (A, B)
这样以后再写对偶时可以不写:
(String, Int)
而是:
String × Int
中置类型的优先级和普通的操作符一样,而且如果不是以:结尾,默认就是左结合:
String × Int × Int
相当于:
((String, Int), Int)
中置类型的名称可以是任何操作符的字符序列,但不可以是*。因为会和变长参数声明
T*混淆。
类型变化
协变
Scala的泛型在默认情况下是非协变的(nonvariant),即:对于泛型Queue[T]来说,
Queue[String]不是Queue[AnyRef]的子类。
但还是可以设置为协变(covariant)的。用+表明子类型化协变,即Queue[String]是
Queue[AnyRef]的子类:
trait Queue[+T] { ... }
不可变类型可以安全协变
比如Scala默认的不可变List,是可以协变的类型:
val s:AnyRef = "abc"
var objects:List[AnyRef] = List[String]("abc","123")
相对的,如果用的是可变的List,就是不可协变:
scala> var l: java.util.ArrayList[Object] = new java.util.ArrayList[String]()
<console>:7: error: type mismatch;
found : java.util.ArrayList[String]
required: java.util.ArrayList[Object]
Note: String <: Object, but Java-defined class ArrayList is invariant in type E.
You may wish to investigate a wildcard type such as `_ <: Object`. (SLS 3.2.10)
var l: java.util.ArrayList[Object] = new java.util.ArrayList[String]()
^
可变类型的协变会有问题
Scala默认禁止协变是因为协变会产生问题:
在纯函数式中,许多类型都是自然协变的。然而一旦引入了可变数据,情况就改变了。假设 一个简单的只能读写一个元素的单元格(Cell)类型:
class Cell[T](init: T) {
private[this] var current = init
def get = current
def set(x: T) { current = x }
}
上面的Cell是非协变的。我们现成假设它是协变的,声明为Cell[+T]并发送给Scala
编译器。于是我们可以构建如下存在问题的语句序列:
val c1: Cell[String] = new Cell[String]("abc")
val c2: Cell[Any] = c1
这里要注意的是,同一个实例,有两个类型指向它:
c1: Cell[String]和c2:Cell[Any]:
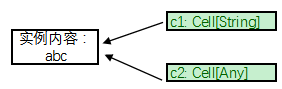
问题就出在Cell容器中的成员是可变的:
c2.set(1) // 把内容从`String`变成了`Int`
虽然c2是Cell[Any],所以存数字也OK。
但是这样c1: Cell[String]的变量类型就和所指向的实例的真正类型不符合了:
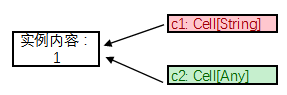
c1类型是Cell[String],赋给字符串也OK。但实际存的内容已经是Int了:
val s: String = c1.get
上面四行单独看从语法上都OK,但是从执行逻辑上来说是错误的:
val c1 = new Cell[String]("abc")
val c2: Cell[Any] = c1
c2.set(1)
val s: String = c1.get
Cell.scala:7: error: covariant type T occurs in
contravariant position in type T of value x
def set(x: T) = current = x
^
问题出在第二行,Cell[Any]和Cell[String]的类型的协变引起了错误。
Java数组是协变的
以前面的Cell类为例与Java中的数组比较,Java中的数组是协变的:
// this is Java
String[] a1 = { "abc" };
Object[] a2 = a1;
a2[0] = new Integer(17);
String s = a1[0];
虽然可以通过编译,但是运行时第四行会报错。Java运行时保存了数组元素类型,在更新时
对新元素进行合法性校验。类型错误时抛出ArrayStore:
Exception in thread "main" java.lang.ArrayStoreException:
java.lang.Integer
at JavaArrays.main(JavaArrays.java:8)
这样看起来好像即没有用又浪费性能。按James Gosling的说法是希望有一个通用处理数组 的简单方法,如需要排序所有元素时:
void sort(Object[] a, Comparator cmp) { ... }
这样确保任意类型参数的数组都可以传入排序方法。当然后来Java有了泛型以后数组的协变 不再有用了,为了向以前老版本兼容才留着。
Scala数组是非协变的
Scala中数组是不可协变的:
scala> val a1 = Array("abc")
a1: Array[java.lang.String] = Array(abc)
scala> val a2: Array[Any] = a1
<console>:5: error: type mismatch;
found : Array[java.lang.String]
required: Array[Any]
val a2: Array[Any] = a1
^
但有时还是要数组能泛型手段与Java遗留方法进行交互。所以Scala允许把T类型的数组
转型为任意T的超类的数组:
scala> val a2: Array[Object] =
| a1.asInstanceOf[Array[Object]]
a2: Array[java.lang.Object] = Array(abc)
逆变
与协变相反的[-T]表示逆变。这样MyClass[AnyRef]可以作为MyClass[String]的子类
。
先看一个例子,出版物为父类类型,图书为子类。方法getTitle根据出版物取得它的标题
:
class Publication(val title: String) class Book(title: String) extends Publication(title) def getTitle(p: Publication): String = p.title
现在用一个单例对象Library来模拟图书馆,里面用一个Set来存放许多图。还有方法
printBookList()输出所有图书的信息,这个方法需要有一个取得书名的函数作为参数,
类型为Book => AnyRef:
object Library {
val books: Set[Book] = Set(
new Book("Programming in Scala"),
new Book("Walden")
)
def printBookList(getInfo: Book => AnyRef) {
for (book <- books) println(getInfo(book))
}
}
把之前的getTitle()方法作为实参传递给printBookList()打印出所有书的书名:
scala> Library.printBookList(getTitle) Programming in Scala Walden
这个例子的重点在于把getTitle: Publication => String赋值给了
getInfo: Book => AnyRef先来看参数:
因为形参getInfo: Book => AnyRef以Book作为参数的类型,
所以在实际调用到getInfo()时传入的实参类型肯定是Book类型(或是Book的子类);
又因为getTitle: Publication => String的参数类型是Book的父类Publication,
所以最终是把Book类型的实参赋值给了Publication类型的形参。
再来看返回值:
因为形参getInfo: Book => AnyRef以AnyRef作为参数的类型,
实参getTitle: Publication => String把String类型的赋值返回给了AnyRef。
println()方法会用到toString()方法,所以getInfo()方法的返回类型只要是AnyRef
的子类都可以。
从函数参数的角度来看是把Publication => String赋值给Book => AnyRef。在这里:
-
参数必须是
Book的父类; -
结果必须是
AnyRef的子类;
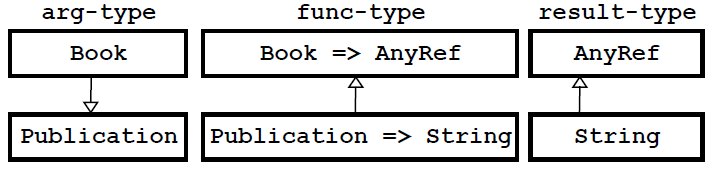
从赋值的过程来说,每次赋值操作都是把子类赋值给超类:
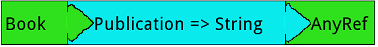
用函数类型来表达逆变
Scala函数特质中对于S => T类型的函数会定义trait Function[S, T],这时对参数S
逆变而对结果T协变就是一种常用的策略:
trait Function1[-S, +T] {
def apply(x: S): T
}
LSP
对于两个类U和T。如果可以用T可以提供U要用到的功能,并且用起来限制更少,
就可以假设T是U的子类(里氏原则:Liskov Substitution Principle,LSP)。
trait OutputChannel[-T] {
def write(x: T)
}
class Canyref extends OutputChannel[AnyRef] {
def write(x: AnyRef) {println(x)}
}
class Cstring extends OutputChannel[String] {
def write(x: String) {println(x)}
}
对于OutputChannel[AnyRef]来说,它的write方法可以接受任何AnyRef类型的实参:
val anyref = new Canyref anyref write "Hello ~" anyref write 1 :: 2 :: 3 :: Nil
但是对于OutputChannel[String]来说,它的write方法只能接受String类型的实参:
val string = new Cstring string write "Hello ~" string write 1 :: 2 :: 3 :: Nil // error
这种情况下OutputChannel[AnyRef]作为OutputChannel[String]的子类型。
因为:
-
它们都支持都支持
write操作。 -
OutputChannel[AnyRef]比OutputChannel[String]适用范围更广泛。
所以把一个OutputChannel[AnyRef]赋给OutputChannel[String]是安全的,反过来把一个
OutputChannel[String]赋给OutputChannel[AnyRef]却是不安全的。
检查变化类型注解
禁止方法参数协变
前面已经看到了通常在函数的参数上采用逆变并在返回值上采用协变。概括地说:
对于对象的消费适合逆变,而对产出的结果适用协变。如果一个对象同时消费和产出某值, 则类型应该保持不变。
只要把泛型类型作为方法类型参数,包含它的类或特质就有可能不能与这个类型参数一起 协变。如形式:
class Queue[+T] {
def append(x: T) =
...
}
编译器会报错提示不能放在逆变位置:
Queues.scala:11: error: covariant type T occurs in
contravariant position in type T of value x
def append(x: T) =
^
把前面的队列改成协变的,然后创建指定元素类型为Int的队列。并重载append方法
使其在添加前先输出它参数的平方根:
class StrangeIntQueue extends Queue[Int] {
override def append(x: Int) = {
println(Math.sqrt(x))
super.append(x)
}
}
假设上面的代码是协变的,对应以下的调用:
val x: Queue[Any] = new StrangeIntQueue
x.append("abc")
上面的因为协变所以第一行是有效的,但第二行就有问题了,因为不能对字符串求平方根。
禁止可变的字段协变
不要对可重新赋值的字段使用+的协变类型参数。如var x:T在Scala里被看作自带
getter方法def x:T、def x_= (y:T),所以将不是协变的。
class UserName[+T](var first: T, var second: T) // error
因为first与second会生成setter方法,而前面已经说过函数的参数处于逆变点:
first_=(value: T)
型变类型反转
如果函数的参数是函数,这个作为参数的函数型变是反转过来的:参数是协变面结果是
逆变的。例如Iterable[+A]的foldLeft方法:
foldLeft[B](z: B)(op: (B, A) => B): B
- + + - +
类型变化的验证规则
类型声明中可能会用到类型参数的地方被分为协变点、逆变点、中立。编译器检查类的类型 参数的每一个用法。
-
+的类型参数只能被用在协变点上, -
-的类型参数只能用在逆变点上。 - 没有变化的类型可以用于任何位置,所以它是唯一能有在中性位置上的类型参数。

编译器对位置分类是从类型声明开始进入更深的内嵌层。
处于声明类最顶层(位置1)被划为协变点的位置。默认情况下内层位置(位置2)的分类 会和外层一致。

但总有例外:
方法参数位置(位置3)是方法外部的位置的翻转类别,这里协变点转为逆变点,逆变点转 为协变点,而中性位置仍然保持中性。

方法的类型参数(位置4)的当前类别也会被翻转。

而类型参数的位置,如C[Arg]中的Arg也有可能被翻转,这取决于对应类型参数的变化
类型:
-
如果
C的类型参数标了+,那么类别不变;如果标了-,则当前类别被翻转; -
如果
C的类型参数没有变化型注解,那么当前类型将改为中性。

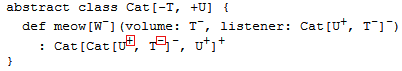
上面的类型定义中的若干位置变化弄被标了+或-:
类型参数W与两个值参数volume和listener的位置都是逆变点。

注意meow的结果类型Cat[Cat[U, T], U],第一个Cat[U, T]参数的位置是逆变点。
因为Cat的第一个类型参数[T]被标了-。这个参数中的类型U重新转为协变点(两次
翻转),而参数中的类型T仍然是逆变点。
总的来说:人脑想跟上变化型位置的变化是很困难的,所以Scala编译器自动来完成这项 工作。计算机变化型过程中,编译器检查每个类型参数是否仅用于分类协变点确的位置上。
就上面的例子来说,T仅用在逆变点位置上,而U仅用于协变点的位置上。所以这个
Cat类是协变的。
泛型变量的界定
可协变类型在逆变点要声明下界
当前类型T对于它的指定超类U来说,自己位于下界,格式:U >: T。
声明下界的作用是为了在参数位置实现协变。因为在成员方法的形参位于逆变点,
所以成员方法的类型不能是协变类型T,只能用超类U。形式为:
class MyClass[+T] {
def func01[U >: T](x: U) = { ... }
}
要注意对于同一个类来说,它即是自己的超类也是自己子类。所以T是U下界。
这样形参为U的地方传入T可以可以的。
例如:Pair类型是一个对偶,因为两个成员是不可变的,所以可以协变:
class Pair[+T](val first: T, val second: T)
添加一个替换第一个元素的方法:
class Pair[+T](val first: T, val second: T) {
def replaceFirst(newFirst: T): Pair[T] = new Pair[T](newFirst, second) // error
}
报错是因为方法的形参newFirst出现在了逆变点上,所以不能用可协变的类型T。
但实际上这个方法不会修改原来的对偶,因为它返回的是一个新的实例。
解决方案是给方法加上一个新的类型参数:
def replaceFirst[R >: T](newFirst: R): Pair[R] = new Pair[R](newFirst, second)
这样就把该方法的类型参数变成了另一个类型R的泛型。因为R没有类型变化,所以可以
放置在逆变点。
刚刚说了这么多的理论,现在还可以从直觉上理解一下。协变的目的是为了可以把
子类的范型实例赋值给父类,那么以后传给方法func01的实参类型也是父类的类型:
val item1: MyClass[Fruit] = new MyClass[Apple]() // 子类范型赋值给父火砖 val item2: Fruit = item1.func01(new Fruit()); // 方法的实参是父类
例:
要实现一个队列类型Queue[T],添加队列成员append(T)方法的参数是不能协变的,
所以为了实现协变的Queue[+T]要在appen方法中使用下界:
scala> class MyQueue[+T] (val ll: List[T]) {
| def append[U >: T](x: U) = new MyQueue[U](x :: ll)
| override def toString = ll.toString
| }
defined class MyQueue
append方法指定的类型参数U,并通过语法U >: T定义了T为U的下界,即:U
必须是T的超类。这里可以把T的任意超类U的对象添加进来,返回类型也成了
MyQueue[U]。
对于append方法来说,它不知道自己处理的是某一个子类。只知道处理的是超类U。
所以不会有类型错误。
其实上面的方法体中:
def append[U >: T](x: U) = new MyQueue[U](x :: ll) // 可以简写为: def append[U >: T](x: U) = new MyQueue(x :: ll)
编译器会自动推断方法的返回类型Queue为Queue[U]。
又一个例子:
对于Fruit和两个子类Orange和Apple,可以把Orange对象传入
MyQueue[Apple]而返回MyQueue[Fruit]。
scala> class Fruit(val name: String) { override def toString = name }
scala> class Apple(name: String) extends Fruit(name)
scala> class Orange(name: String) extends Fruit(name)
scala> val q0 = new MyQueue(new Apple("Apple 01") :: Nil)
q0: MyQueue[Apple] = List(Apple 01)
scala> val q1: MyQueue[Fruit] = q0
q1: MyQueue[Fruit] = List(Apple 01)
scala> val q2 = q1.append(new Orange("Orange 01"))
q2: MyQueue[Fruit] = List(Orange 01, Apple 01)
scala> val q3 = q1.append(new Fruit("Fruit 01"))
q3: MyQueue[Fruit] = List(Fruit 01, Apple 01)
scala> q1
res14: MyQueue[Fruit] = List(Apple 01)
scala> q2
res15: MyQueue[Fruit] = List(Orange 01, Apple 01)
scala> q3
res16: MyQueue[Fruit] = List(Fruit 01, Apple 01)
从技术角度来看,这里的情况发生了下界的翻转:类型参数U处于逆变点位置(1次翻转)
,而下界U >: T处于协变点的位置(两次翻转)。
可逆变类型在协变点要声明上界
当前类型T对于子类L来说,自己位于上界,格式为:L <: T
class MyClass[-T] {
def func01[L <: T](x: L) = { ... }
}
上界把类型变化的范围限制为某一个类的子类,这样保证具体绑定的类有基本的功能。
与协变相反,逆变就是只能接受逆变类型T自身及其超类而不是子类。
逆变在集合上没有什么实际价值,乍听上去也很难理解,
但是在设计库的时候逆变也是一个重要的工具。
仍然基于水果的背景,我们考虑如下场景:
如果有RedApple extends Apple extends Fruit。
有一把切水果刀,就好象料理机那样,装上水果刀头就能切所有的水果,但是比较粗糙, 装上苹果刀就能切苹果,装好红苹果刀就能把红苹果切成艺术品。一个厨师右手拿水果, 左手去拿刀,如果手里拿的是苹果,显然切苹果的刀和切水果的刀都可以用,而切子类 红苹果的刀反而不能用了,对吗?
class Fruit { def selfIntro() = "Fruit" }
class Apple extends Fruit { override def selfIntro() = "Apple" }
class RedApple extends Apple { override def selfIntro() = "RedApple" }
class Cutter[-T] {
def cut[L <: T](x: L) = x match {
case f: Fruit => Console.println("cut a " + f.selfIntro)
case _ => Console.println("don't know what to do")
}
}
class Chef[T] {
def cutIt(c: Cutter[T], p: T) = c.cut(p)
}
测试结果,切红苹果的刀是不能切苹果的,而且水果的刀是可以的,这正是我们需要的。
scala> new Chef[Apple].cutIt(new Cutter[RedApple], new Apple)
<console>:16: error: type mismatch;
found : Cutter[RedApple]
required: Cutter[Apple]
new Chef[Apple].cutIt(new Cutter[RedApple], new Apple)
从上面的例子可以看出,对于具体的类型:
Chef[Apple].cutIt(c: Cutter[Apple], p: Apple)
不能把Cutter[RedApple]赋值给c: Cutter[Apple]
因为Cutter[-T]声明的是逆变范型参数。
而且就算忽视这一点,对于:
Chef[Apple].cut[L <: Apple](x: L)
把Apple赋值给x: L也不符合类型下界限制L <: Apple。
^
scala> new Chef[Apple].cutIt(new Cutter[Apple], new Apple) cut a Apple scala> new Chef[Apple].cutIt(new Cutter[Fruit], new Apple) cut a Apple
可见这正是我们需要的结果,通过精确的类型定义,我们使得编译器能够检查出用户对库的 不正确使用,提高了库的强壮性。
所以说上界把类型变化的范围限制为某一个类的子类, 这样保证具体绑定的类有基本的功能。再来看一个例子:
比如,Ordered特质实现排序的功能,那么以Ordered特质为上界保证得到的类是可以
排序的。通过把Ordered特质混入到类中并实现抽象比较方法Compare就可以对实例进行
比较:
class Person(val firstName: String, val lastName: String)
extends Ordered[Person] {
def compare(that: Person) = {
val lastNameComparison =
lastName.compareToIgnoreCase(that.lastName)
if (lastNameComparison != 0)
lastNameComparison
else
firstName.compareToIgnoreCase(that.firstName)
}
override def toString = firstName +" "+ lastName
}
这样Person就具有了比较的功能:
scala> val robert = new Person("Robert", "Jones")
robert: Person = Robert Jones
scala> val sally = new Person("Sally", "Smith")
sally: Person = Sally Smith
scala> robert < sally
res0: Boolean = true
为了让列表类型混入到Ordered中,需要使用上界T <: Ordered[T]。表明类型必须是
Ordered的子类型。比如Person,因为Person混入了Ordered特质:
def orderedMergeSort[T <: Ordered[T]](xs: List[T]): List[T] = {
def merge(xs: List[T], ys: List[T]): List[T] =
(xs, ys) match {
case (Nil, _) => ys
case (_, Nil) => xs
case (x :: xs1, y :: ys1) =>
if (x < y) x :: merge(xs1, ys)
else y :: merge(xs, ys1)
}
val n = xs.length / 2
if (n == 0) xs
else {
val (ys, zs) = xs splitAt n
merge(orderedMergeSort(ys), orderedMergeSort(zs))
}
}
使用:
scala> val people = List(
| new Person("Larry", "Wall"),
| new Person("Anders", "Hejlsberg"),
| new Person("Guido", "van Rossum"),
| new Person("Alan", "Kay"),
| new Person("Yukihiro", "Matsumoto")
| )
people: List[Person] = List(Larry Wall, Anders Hejlsberg,
Guido van Rossum, Alan Kay, Yukihiro Matsumoto)
scala> val sortedPeople = orderedMergeSort(people)
sortedPeople: List[Person] = List(Anders Hejlsberg, Alan Kay,
Yukihiro Matsumoto, Guido van Rossum, Larry Wall)
以上的解决方案还是有限制,比如不能适应整数列表。因为Int不是Ordered[Int]的
子类:
scala> val wontCompile = orderedMergeSort(List(3, 2, 1))
<console>:5: error: inferred type arguments [Int] do
not conform to method orderedMergeSort's type
parameter bounds [T <: Ordered[T]]
val wontCompile = orderedMergeSort(List(3, 2, 1))
^
在以后的「隐式类型转换和参数」的「视图界定」一节中介绍通过采用隐式参数与检查约束来 实现更加通用的方案。
同时指定上界与下界
T >: Lower <: Upper
单例对象不能泛型
单例对象不能添加类型参数。
以一个列表的实现为例子:
abstract class List[+T] {
def isEmpty: Boolean
def head: T
def tail: List[T]
}
这个是结点类,头部是一个元素,其他的元素是尾问列表。其实就相当于Scala已经有的
:::
class Node[T](val head: T, val tail: List[T]) extends List[T] {
def isEmpty = false
}
这是列表结束符,可以理解为一个不能放元素的空列表。其实就相当于Scala里已经有的
Nil:
object Empty extends List[Nothing] {
// It can't be object Empty[T] extends List[T]
// OK to be class Empty[T] extends List[T]
def isEmpty = true
def head = throw new UnsupportedOperationException
def tail = throw new UnsupportedOperationException
}
注意上面的Empty是一个单例对象,而单例对象是不能用泛型的。所以在这里它只能继承
List[Nothing]而不能继承List[T]。
因为Nothing是所有类型的子类,所以可以这样:
val lst = new Node(42, Empty)
因为根据协变规则List[Nothing]可以被转为List[Int]。
再定义一个查看刚刚构造的列表的方法:
scala> def show[T](lst: List[T]) {
| if (!lst.isEmpty) { println(lst.head); show(lst.tail) }
| }
show: [T](lst: List[T])Unit
scala> show(new Node(1729, lst))
1729
42
类型通配符
Java中类型类不可变,但提供了通配符。以对偶为例:
void func01(Pair<? extends Person> people) {} // Person的子类
void func02(Pair<? super Person> people) {} // Person的父类
PECS
PECS指「Producer Extends,Consumer Super」。 以Java为例:
-
如果参数化类型表示一个生产者,就使用
<? extends T> -
如果它表示一个消费者,就使用
<? super T>
public abstract class MyStack<E> {
abstract public boolean isEmpty();
abstract public void push(E e);
abstract public E pop();
public void pushAll(Collection<? extends E> src) {
// 把src提供内容给别人,src是生产者
for (E e: src) this.push(e);
}
public void popAll(Collection<? super E> dst) {
// dst接收别人给的内容,dst是消费者
while (!this.isEmpty()) dst.add(this.pop());
}
}
模拟协变
在Scala中的协变类型用不着通配符,但是如果Queue类型是不可变的:
scala> class Pair[T](var first: T, var second: T) {
| override def toString = "(" + first + "," + second + ")"
| }
defined class Pair
对于父类Person和子类Student:
scala> class Person(val name: String) {
| override def toString = getClass.getName + " " + name
| }
defined class Person
scala> class Student(name: String) extends Person(name)
defined class Student
scala> val fred = new Student("Fred")
fred: Student = Student Fred
scala> val wilma = new Student("Wilma")
wilma: Student = Student Wilma
scala> val studentPair = new Pair(fred, wilma)
studentPair: Pair[Student] = (Student Fred,Student Wilma)
可以定义像协变一样的方法:
scala> def makeFriends(p: Pair[_ <: Person]) =
| p.first.name + " and " + p.second.name + " are now friends."
makeFriends: (p: Pair[_ <: Person])String
scala> makeFriends(studentPair) // OK
res2: String = Fred and Wilma are now friends.
模拟逆变
结合Comparator特质与逆变,实现一个取对偶中较小元素的方法:
scala> import java.util.Comparator
import java.util.Comparator
scala> def min[T](p: Pair[T])(comp: Comparator[_ >: T]) =
| if (comp.compare(p.first, p.second) < 0) p.first else p.second
min: [T](p: Pair[T])(comp: java.util.Comparator[_ >: T])T
注意min方法有要两个柯里化的参数列表,分别是:
-
要进行比较的对偶
p: Pair[T] -
判断大小的方法
comp: Comparator[_ >: T]。
先来看第一个参数,它的类型Pair[T],那我们给它一个Pair[String]。泛型T就具体
化为String:
scala> val p = new Pair("Fred", "Wilma")
p: Pair[String] = (Fred,Wilma)
再来看第二个参数类型Comparator[_ >: T],这里_代表的类必须是T的超类(但也
可以就是T)。因为前面T已经确定为是String,那么这里选用Object。实现
Comparator[Object]:
scala> val sillyHashComp = new Comparator[Object] {
| def compare(a: Object, b: Object) = a.hashCode() - b.hashCode()
| }
sillyHashComp: java.util.Comparator[Object] = $anon$1@1af37801
这样就可以通过类型检查,调用min()方法比较大小了:
scala> min(p)(sillyHashComp) res5: String = Fred
缺陷
Scala的类型通配符还不是很完善,下面的声明在Scala 2.10以前都不行:
scala> def min[T <: Comparable[_ >: T]](p: Pair[T]) =
| if (p.first.compareTo(p.second) < 0) p.first else p.second
<console>:12: error: illegal cyclic reference involving type T
def min[T <: Comparable[_ >: T]](p: Pair[T]) =
^
<console>:13: error: type mismatch;
found : T
required: _$1
if (p.first.compareTo(p.second) < 0) p.first else p.second
解决方案是分成两步定义:
scala> type SuperComparable[T] = Comparable[_ >: T]
defined type alias SuperComparable
scala> def min[T <: SuperComparable[T]](p: Pair[T]) =
| if (p.first.compareTo(p.second) < 0) p.first else p.second
min: [T <: SuperComparable[T]](p: Pair[T])T
举例来说,如果Student <: Comparable[Person]:
scala> class Person(val name: String) extends Comparable[Person] {
| override def toString = getClass.getName + " " + name
| def compareTo(other: Person) = name.compareTo(other.name)
| }
defined class Person
scala> class Student(name: String) extends Person(name)
defined class Student
就实现了从Person到Student的协变:
scala> val fred = new Student("Fred")
fred: Student = Student Fred
scala> val wilma = new Student("Wilma")
wilma: Student = Student Wilma
scala> val studentPair = new Pair(fred, wilma)
studentPair: Pair[Student] = (Student Fred,Student Wilma)
scala> min(studentPair)
res6: Student = Student Fred
这里的类型通配符其实是「存在类型」的语法糖,以后会具体讨论存在类型。
例子:slf4j中的类型问题
A problem here is that Int is an AnyVal which means that it is not an AnyRef/Object Also an Array is not a TraversableOnce.
Now in the foo method we pattern match on the varargs.
def foo(msg:String,varargs:AnyRef*) { varargs.toList match {
case (h:TraversableOnce[_]) :: Nil =>
log.info(msg, h.toSeq.asInstanceOf[Seq[AnyRef]]:_*)
case (h:Array[_]) :: Nil =>
log.info(msg, h.toSeq.asInstanceOf[Seq[AnyRef]]:_*)
case _ => log.info(msg,varargs:_*)
}}
There are 3 cases we deal with:
case (h:TraversableOnce[_]) :: Nil => log.info(msg, h.toSeq.asInstanceOf[Seq[AnyRef]]:_*)
TraversableOnce is one of the Scala collections base traits; every collection
I know of extends this (Array is not a collection, it doesn't extend it).
It can contain either AnyVal or AnyRef but the actual items at runtime will be
wrapped primitive (java.lang.Integer, etc.). So we can down cast from Seq[Any]
to Seq[AnyRef] here and we should be okay.
case (h:Array[_]) :: Nil => log.info(msg, h.toSeq.asInstanceOf[Seq[AnyRef]]:_*)
Just like we did with the TraversableOnce, turn it into a Seq and then downcast. The transformation into Seq will wrap any primitives for us.
case _ => log.info(msg,varargs:_*)
The general case in which varargs could be empty, or contain more than one entry.
例:开发纯函数式队列
函数式的队列是不可变的,添加元素操作会返回一个新的队列。三个基本方法:
-
head返回队列的第一个元素。 -
tail返回第一个元素以外的队列。 -
append返回在尾部添加指定元素的列队。
理想情况下,希望三种基本操作都可以在常量时间中完成。
一个实现方案是以List作为功能表达类型,可以用现成的head和tail方法。append
方法调用连接操作:
class SlowAppendQueue[T](elems: List[T]) { // Not efficient
def head = elems.head
def tail = new SlowAppendQueue(elems.tail)
def append(x: T) = new SlowAppendQueue(elems ::: List(x))
}
但这样append操作的时间会按元素的数量而增加,那换一种思路,把列表倒过来排序,
这样会让原来最后加进来的元素出现在列表的最前面:
class SlowHeadQueue[T](smele: List[T]) { // Not efficient
// smele is elems reversed
def head = smele.last
def tail = new SlowHeadQueue(smele.init)
def append(x: T) = new SlowHeadQueue(x :: smele)
}
现在表现也倒过来了:append操作时间为常量,但head和tail耗时与元素数量
成正比了。
试一下结合两种列表的方案:
用两个列表leading放前面一半;trailing放后一半反向排的元素。这样全部内容就是
:
leading ::: trailing.reverse
添加新元素:
i :: trailing
这样常量时间就可以完成。但这样前一半的leading就不放进内容了,所以在对空的
leading进行第一次head或tail操作前都要把trailing反转并复制给leading。
这个操作被定义为mirror。
虽然mirror操作与队列长度成正比,但是这只发生在leading为空时才会被调用。因为
如果leading不为空它将直接返回。head与tail操作会调用到mirror,所以这两个
方法的复杂度与队列长度呈线性关系。然而队列越长,mirror被调用的次数就越以级数
方式递减。
class Queue[T](
private val leading: List[T],
private val trailing: List[T]
) {
private def mirror =
if (leading.isEmpty)
new Queue(trailing.reverse, Nil)
else
this
def head = mirror.leading.head
def tail = {
val q = mirror
new Queue(q.leading.tail, q.trailing)
}
def append(x: T) =
new Queue(leading, x :: trailing)
}
信息隐藏
前面的Queue实现暴露了太多实现细节,比如构造器的两个参数还有一个是反转的。
私有构造器及工厂方法
为了不让外部了解构造器的实现,可以把构造器作为隐藏的:
class Queue[T] private (
private val leading: List[T],
private val trailing: List[T]
)
这样防止外部调用主构造器:
scala> new Queue(List(1, 2), List(3))
<console>:6: error: constructor Queue cannot be accessed in
object $iw
new Queue(List(1, 2), List(3))
^
客户代码只能调用辅助构造器:
def this() = this(Nil, Nil)
改良一下,让它可以带上初始队列元素列表:
def this(elems: T*) = this(elems.toList, Nil)
其中的T*是重复参数标记,在前面「函数与闭包」一章中已经介绍。
还有一种让客户代码构造的方法是在类定义同一个文件内建立伴生类的工厂方法:
object Queue {
// constructs a queue with initial elements `xs'
def apply[T](xs: T*) = new Queue[T](xs.toList, Nil)
}
可选方案:私有类
除了私有构造器和私有成员,还可以直接隐藏掉类本身,只提供暴露类公共接口的特质:
trait Queue[T] {
def head: T
def tail: Queue[T]
def append(x: T): Queue[T]
}
object Queue {
def apply[T](xs: T*): Queue[T] =
new QueueImpl[T](xs.toList, Nil)
private class QueueImpl[T](
private val leading: List[T],
private val trailing: List[T]
) extends Queue[T] {
def mirror =
if (leading.isEmpty)
new QueueImpl(trailing.reverse, Nil)
else
this
def head: T = mirror.leading.head
def tail: QueueImpl[T] = {
val q = mirror
new QueueImpl(q.leading.tail, q.trailing)
}
def append(x: T) =
new QueueImpl(leading, x :: trailing)
}
}
对象私有数据
之前的Queue类待改进内容:当leading列表为空时如果重复调用head,那么mirror
操作会重复地把trailing复制到leading列表。
改动:
leading和trailing都是可变变量,mirror操作在当前列表上产生副作用而不是返回
新的队列。由于它们都是对外不可见的私有变量,所以Queue还是算纯函数对象。
class Queue[+T] private (
private[this] var leading: List[T],
private[this] var trailing: List[T]
) {
private def mirror() =
if (leading.isEmpty) {
while (!trailing.isEmpty) {
leading = trailing.head :: leading
trailing = trailing.tail
}
}
def head: T = {
mirror()
leading.head
}
def tail: Queue[T] = {
mirror()
new Queue(leading.tail, trailing)
}
def append[U >: T](x: U) =
new Queue[U](leading, x :: trailing)
}
在两个可变私有成员变量的情况下Queue还可以使用协变。因为对于对象的私有值访问
来说不可能有比定义的对象类型更弱的静态类型对象引用。
所以Scala的类型变化检查对于对象私有成员,在遇到带有+或-的类型参数只出现在
具有相同变化型分类的位置上时,会被忽略。
所以如果去掉private修饰符的[this]限定会编译不过:
Queues.scala:1: error: covariant type T occurs in
contravariant position in type List[T] of parameter of
setter leading_=
class Queue[+T] private (private var leading: List[T],
^
Queues.scala:1: error: covariant type T occurs in
contravariant position in type List[T] of parameter of
setter trailing_=
private var trailing: List[T]) {
^
上面分别报错的原因是:协变类型T出现在setter函数leading_=类型参数List[T]的
逆变位置上;协变类型T出现在setter函数trailing_=类型参数List[T]的逆变位置
上。