注解与XML
注解
注解的作用
Java的注解只是往字节码里增加信息,但Scala的注解可能会影响编译过程。比如
@BeanProperty注解会增加getter与setter方法。
注解语法
主构造器注解
注解放在构造器之前,并加上括号(如果注解没有参数的话):
class Credentials @Inject() (var username: String, var password: String)
对实际类型的注解
对实际类型的注解放在类型名称后面。如为String类型添加了注解:
String @cps[Unit]
类型参数注解
加在类型参数前:
class MyContainer[@specialized T]
表达式注解
还有应用在表达式上的注解,如@unchecked。格式是在表达式后加分号:再加注解:
(e: @unchecked) match {
// non-exhaustive cases...
}
注解完整格式
前面讲的注解形式简单。比较完整的注解格式是:
@annot(exp1, exp2, ...) {val name1=const1, val name2 = cost1, ...}
注解的参数
小括号里与花括号里的都是注解的参数列表。
小括号里的是简单的常量或字面量或是任何简便类型的表达式。如引用作用域内的其他 引用:
@cool val normal = "Hello" @coolerThan(normal) val fonzy = "Heeyyy"
花括号内的是更加复杂、具有可选参数的注解。这些参数可选并且对顺序没有要求(因为是 K-V对应)。但是为了方便处理,等号右边的值必须是常量。
如果参数的名称为value,则可以省略名称:
@Named("creds") val credentials: Credentials = _
如果没有参数,括号也可以省略。
Java注解的参数类型只能是:
- 数值字面量
- 字符串
- 类字面量
- Java枚举
- 其他注解
- 以上类型的数组,但不能是数组的数组
Scala的注解参数可以是任何类型。
标准注解
下面介绍Scala里现有的标准注解。
废弃
@deprecated表示已经被弃用,一希望再被使用的东西:
@deprecated def bigMistake() = //...
这个注解可以被用在任何声明或定义上,如:val、var、def、class、object、
trait、type上。并用于跟随其后的声明或定义整体:
@deprecated class QuickAndDirty {
//...
}
两个参数message和since给出提示信息与废弃的版本:
@deprecated(message = "Use factorial(n: BigInt) instead") def factorial(n: Int): Int = //...
@deprecatedName可以被应用到参数上,并给出一个参数之前用过的名字:
def draw(@deprecatedName('sz) size: Int, sytle: Int = NORMAL)
注意这里的'sz是一个符号。用户还是可能通过draw(sz = 12)来调用,但是会得到一个
过期警告。
自动getter和setter方法
@BeanProperty
Scala里不用显式写getter和setter方法,但有些框架上还是要的。为此,Scala已经提供
了@scala.reflect.BeanProperty注解可以给字段自动加上getter和setter方法。如,对
字段age自动生成getAge和setAge。
注意这里生成的getter和setter方法是在编译之后才产生的。不过问题应该不大,毕竟 Scala里用不着这些getter和setter方法,是为了某些框架而需要的。显然我们不会在 同一时间又编译框架又编译调用框架的代码。
@BooleanBeanProperty产带有is前缀的getter方法,用于Boolean类型。
还有一些不常用的如:@BeanDescription、@BeanDisplayName、@Beaninfo和
@BeanInfoSkip自己RTFM。
标明废弃
警告用户最好不要用某些东西:
@deprecated def bigMistake() = //...
浮点精度
@strictfp对就Java中的strictfp修饰符。表示采用IEEE的双精度值进行浮点运算,而
不是使用Intel处理器默认的80位扩展精度。
@strictfp def calculate(x: Double) = doSth()
本地方法
@native注解对应Java的native修饰符。表示本地调用C或C++的实现的代码:
@native def win32RegKeys(root: Int, path: String): Array[String]
远程调用
@remote注解对应Java的java.rmi.Remote接口。
克隆对象
@cloneable注解对应Java的Cloneable接口。
@cloneable class Employee
易变字段
@volatile警告会被多个线程使用,内容会被其他线程改变。
二进制序列化
Scala没有序列化框架,但准备了三个注解:
-
@serializable表示可序列化(已经过时,应扩展scala.Serializable特质)。 -
@SerialVersionUID(version)标明序列化的版本号。version是数字版本号。 -
@transient标明类里的某个字段不应该被序列化。
@SerialVersionUID(6157032470129384659L) class Employee extends Person with Serializable
不检查
@unchecked标明在模式匹配时不用关心被漏掉的可能性。
@uncheckedVariance忽略与型变相关的错误提示。例如:java.util.Comparator应该是
逆变的。Student是Person的子类,所以在Comparator[Person]可以用来替代
Comparator[Student]。但Java的泛型不支持型变,所以需要声明忽略:
trait COmparator[-T] extends java.lang.Comparator[T @uncheckedVariance]
变长参数
@varargs注解让Java调用Scala带有变长参数的方法。默认情况下变长参数被翻译为序列
:
def process(args: String*) // 等于: def process(args: Seq[String])
为了方便Java调用:
@varargs def process(args: String*)
产对应的Java方法作为中转:
void process(String ... args)
该方法把args数组外包装在Seq中,然后调用实际上的Scala方法。
尾递归
@tailrec提示编译器进行尾递归优化,如果优化不了会报错:
@tailrec def sum(num: Int) = ....
跳转表
C++与Java中switch语句可编译成跳转表以取得比if-else表达式更好的性能。@switch
注解让Scala尝试对match语句生成跳转表:
(n: @switch) match {
case 0 => "Zero"
case 1 => "One"
case _ => "?"
}
内联
内联把方法调用转为外部方法的方法体内容。Scala中通过@inline来建议内联或用
@noinlie禁止内联。
通常内联发生在JVM内部,即时编译器自动进行的内联优化的效果已经非常好了。
可省略方法
@elidable注解标记可以在生产环境中移除的方法:
@elidable(500)
def dump(props: Map[String, String]) { doSth() }
编译时加上参数-Xelide-below:
scalac -Xelide-below 800 myprog.scala
elidable对象定义了一些常量值:
-
MAXIMUM或OFF = Int.MaxValue -
ASSERTION = 2000 -
SEVERE = 1000 -
WARNING = 900 -
INFO = 800 -
CONFIG = 700 -
FINE = 500 -
FINER = 400 -
FINEST = 300 -
MINIMUM或ALL = Int.MinValue
注意这里有ALL、OFF有不同的场景:
- 加在注解里的,表示方法「总是被省略」和「永远不会被省略」
- 加在编译参数里的表示「打开所有方法」或「省略所有方法」
这些常量可以在注解中使用:
import scala.annotation.elidable._
@elidable(FINE)
def dump(props: Map[String, String]) { doSth() }
编译时加上参数中也可以这样用:
scalac -Xelide-below INFO myprog.scala
如果没有指定-Xelide-below参数,默认低于1000(也就是低于SEVERE)的方法和断言会
被去除。
Predef模块定义了一个可以被忽略的assert方法。例如我们可以这样写:
def makeMap(keys: Seq[String], values: Seq[String]) = {
assert(keys.length == values.length, "lengths don't match")
// ...
}
默认情况下断言是启用的,-Xelide-below设值2001或MAXIMUM会禁用断言。
基本类型的包装
基本类型的打包和解包操作并不是很高效,但在涉及到泛型操作时又常常会用到。比如:
def fun[T](x: T, y:T) = ...
@specialized注解让编译器添加自动重载的基本类型版本:
def fun[@specialized T](x: T, y:T) = ...
还可以限定类型:
def fun[@specialized(Long, Double) T](x: T, y:T) = ...
可以指定的类型有:Unit、Boolean、Byte、Short、Char、Int、Lang、
Float、Double。
隐式转换失败提示
@implicitNotFound注解在找不到时给出更有意义的提示信息。
实现Scala注解
必须扩展Annotation特质,如unchecked注解:
class unchecked extends annotationAnnotation
注解可以选择扩展自下面两个特质:
-
StaticAnnotation:添加Scala元数据到类文件中。 -
ClassfileAnnotation:添加Java元数据到类文件中。(Scala2.9中还没有支持)
Scala注解扩展作用范围
一般来说注解的作用范围是所在的位置,但有些元数据注解会扩展范围。如:
-
@param -
@field -
@getter、@setter -
@beanGetter、@beanSetter
比较常见的应用场景是,把注解的目标从字段转为字段的getter、setter方法。例如,
deprecated注解的定义:
@getter @setter @beanGetter @beanSetter class deprecated(message: String = "", since: String = "") extends annotation.StaticAnnotation
除了在定义注解时加入元数据注解,在类中也可以加上元数据注解:
@Entity class Credentials {
@(Id @beanGetter)
@(BeanProperty)
var id = 0
因为JPA要求@Id注解要应用的Java的getId()方法,所以这里用@beanGetter注解把
标签的作用扩展到getId()方法上而不是id属性。
使用XML
scala.xml包中有很多xml处理工具,比如单例对象XML。
半结构化数据
就是像XML这样虽然不是二进制但还是有结构的文本之类的数据结构的特点之类的。
XML概览
介绍什么是XML……还是略了吧……
XML字面量
Scala里可以直接给XML写字面量。解释器把从根标签的开始到结束都作为XML字面量:
scala> <a>
| This is some XML.
| Here is a tag: <atag/>
| </a>
res0: scala.xml.Elem =
<a>
This is some XML.
Here is a tag: <atag></atag>
</a>
节点类型
上面的xml类型Elem类,其他一些与XML相关的重要类有:
-
Node类,所有XML节点的抽象。 -
Text类,只有文本的节点。 -
NodeSeq类,就是多个节点的序列。你可以把Node想象成只有一个成员的NodeSeq。
还有一个scala.xml.Null是一个空属性列表,不是scala.Null类型。
还有其他的类型:
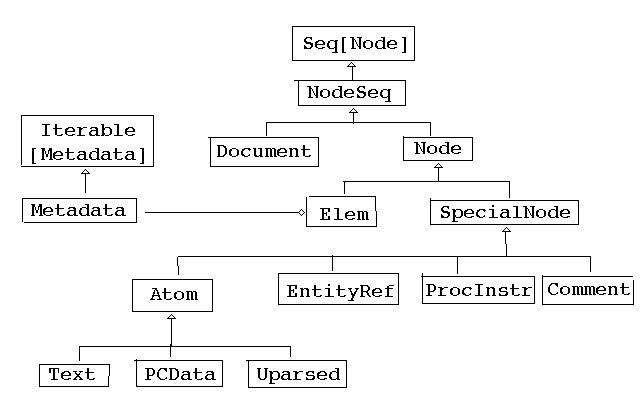
Elem类表示XML元素:
val elem = <a href="http://scala-lang.org">The <em>Scala</em> language</a>
这里得到一个label属性为a的元素,它的child是子节点(两个Text和一个ELem
)
遍历子节点只要:
for (n <- elem.chile) doSth()
对于其他的内容如:注释(<!-- ... -->)、实体引用(&...;)、处理指令(
<?...?>)也有对应的类型。
NodeBuffer
NodeBuffer扩展自ArrayBuffer[Node],可以用来构建节点序列。
scala> import scala.xml._ import scala.xml._ scala> val items = new NodeBuffer items: scala.xml.NodeBuffer = ArrayBuffer() scala> items += <li>Fred</li> res0: items.type = ArrayBuffer(<li>Fred</li>) scala> items += <li>Willma</li> res1: items.type = ArrayBuffer(<li>Fred</li>, <li>Willma</li>)
NodeBuffer是一个Seq[Node]可以被隐式转换为NodeSeq。注意转换以了就就别再改了
。XML节点序列应该是不可变的:
scala> val nodes: NodeSeq = items nodes: scala.xml.NodeSeq = NodeSeq(<li>Fred</li>, <li>Willma</li>)
元素属性
attributes属性取得某个元素属性的键和值,类型为MetaData。可能通过()操作
来访问键的值:
scala> val elem = <a href="http://scala-lang.org/"> The Scala Language</a>
elem: scala.xml.Elem = <a href="http://scala-lang.org/"> The Scala Language</a>
scala> val url = elem.attributes("href")
url: Seq[scala.xml.Node] = http://scala-lang.org/
注意得到的结果类型是Seq[Node],如果内容中有特殊字符的话:
scala> val image = <img alt="San josé state university logo" src="ali.jpg" />
image: scala.xml.Elem = <img alt="San josé state university logo" src="ali.jpg"/>
scala> val alt = image.attributes("alt")
alt: Seq[scala.xml.Node] = San josé state university logo
可以转义特殊字符:
scala> val image = <img alt="San josé state university logo" src="ali.jpg" />
image: scala.xml.Elem = <img alt="San josé state university logo" src="ali.jpg"/>
scala> val alt = image.attributes("alt")
alt: Seq[scala.xml.Node] = San josé state university logo
如果属性中不存在未被解析的实体,可以用test方法转成字符串:
scala> val alt = image.attributes("alt").text
alt: String = San josé state university logo
如果属性不存在,()操作返回null;用get方法可以返回Option[Seq[Node]]。
MetaData类没有getOrElse方法,但可以用get方法对Option类结果应用
getOrElse:
scala> val url = image.attributes.get("href").getOrElse(Text(""))
url: Seq[scala.xml.Node] =
遍历所有属性:
for (attr <- elem.attributes) doSth()
也可以用asAttrmap方法:
scala> val image = <img alt="TODO" src="hamster.jpg"/> image: scala.xml.Elem = <img alt="TODO" src="hamster.jpg"/> scala> val map = image.attributes.asAttrMap map: Map[String,String] = Map(alt -> TODO, src -> hamster.jpg)
内嵌Scala表达式
不仅有字面量,而且还可以用{}来引入Scala代码,如:
scala> <a> {"hello"+", world"} </a>
res1: scala.xml.Elem = <a> hello, world </a>
如果不是要表达式,而就是字面上的花括号,,那连续两个{{}}就可以转义了。
scala> val ms = <p>{{hello}}</p>
ms: scala.xml.Elem = <p>{hello}</p>
表达式可以多层嵌套,在Scala代码与XML字面量中重复切换:
scala> val yearMade = 1955 yearMade: Int = 1955
scala> <a> { if (yearMade < 2000) <old>{yearMade}</old>
| else xml.NodeSeq.Empty }
| </a>
res2: scala.xml.Elem =
<a> <old>1955</old>
</a>
上面有程序if条件来判断有内容还是没有内容。注意没有内容以XML节点表示就是
xml.NodeSeq.Empty。
花括号里表达式不一定要输出XML节点,其他的类型Scala值都会被传为字符串:
scala> <a> {3 + 4} </a>
res3: scala.xml.Elem = <a> 7 </a>
如果输出返回节点,则文本中的<、>和&会被转义:
scala> <a> {"</a>potential security hole<a>"} </a>
res4: scala.xml.Elem = <a> </a>potential security
hole<a> </a>
相反,如果用底层的字符串操作创建XML,可以会因为漏掉转义而出错:
scala> "<a>" + "</a>potential security hole<a>" + "</a>" res5: java.lang.String = <a></a>potential security hole<a></a>
所以还是用XML字面量比较安全。
如果要转义花括号的话,只要在一行里写两次花括号就可以了:
scala> <a> {{{{brace yourself!}}}} </a>
res7: scala.xml.Elem = <a> {{brace yourself!}} </a>
如果表达式产的结果是节点序列会直接添加到XML中,其他类型的结果放到一个Atom[T]
容器中。这样就可以在XML树中放置任何类型的值,并可用Atom节点的data属性取得
这些值。XML保存时这些Atom类型实例会调用data的toString方法转成字符串。
内嵌的字符串不会转成Text节点而是作为Atom[String]节点。保存成文本时没有问题,
但是如果要用Text节点的模式进行模式匹配就匹配不了,因为Text是Atom[String]
的子类。这种情况下应该加入的是Text节点面不是字符串:
<li>{Text("Another item")}</li>
属性中使用表达式
函数返回的字符串直接作为属性值:
<img src={makeURL(fileName)} />
注意不能加引号,不然就原文输出了。如下面这样:
<img src="{makeURL(fileName)}" />
如果要在属性中包含实体引用或是原子,可以在表达式中产出一个节点序列:
<a id={new Atom(1)} ... />
在表达式返回null或None的情况下,属性会不被设置:
<img alt={if (description == "TODO") null else description} ... />
用Option[Seq[Node]]也有同样的效果:
<img alt={if (description == "TODO") None else Some(Text(description))} ... />
特殊结点类型
非XML文本,如XHTML中的JavaScript代码,用CDATA:
scala> val js = <script><![CDATA[if (temp < 0) alert("Cold!")]]></script>
js: scala.xml.Elem = <script>if (temp < 0) alert("Cold!")</script>
但对解析器来说这只是一个Text子节点,不知道它是CDATA。可以用一个PCData节点
类型:
scala> val code = """if (temp < 0) alert("Cold!")"""
code: String = if (temp < 0) alert("Cold!")
scala> val js = <script>{PCData(code)}</script>
js: scala.xml.Elem = <script><![CDATA[if (temp < 0) alert("Cold!")]]></script>
还可以用Unparsed节点包含任意文本,但这样人工输入的XML很容易格式错误,不推荐:
scala> val n1 = <xml:unparsed><&></xml:unparsed>
n1: scala.xml.Unparsed = <&>
scala> val n2 = Unparsed("<&>")
n2: scala.xml.Unparsed = <&>
还可以对节点进行分组:
scala> val g1 = <xml:group><li>Item 1</li><li>Item 2</li></xml:group> g1: scala.xml.Group = <li>Item 1</li><li>Item 2</li> scala> val g2 = Group(Seq(<li>Item 1</li>, <li>Item 2</li>)) g2: scala.xml.Group = <li>Item 1</li><li>Item 2</li>
注意Seq()方法中一定要用逗号与空格分开,不能少。
组里的元素被作为两个元素:
scala> for (n <- <xml:group><li>Item 1</li><li>Item 2</li></xml:group>) yield n res2: scala.xml.NodeSeq = NodeSeq(<li>Item 1</li>, <li>Item 2</li>)
其他情况下:
scala> for (n <- <li>Item 1</li><li>Item 2</li>) yield n res0: scala.collection.mutable.ArrayBuffer[scala.xml.Node] = ArrayBuffer(<li>Item 1</li>, <li>Item 2</li>) scala> for (n <- <ol><li>Item 1</li><li>Item 2</li></ol>) yield n res1: scala.xml.NodeSeq = NodeSeq(<ol><li>Item 1</li><li>Item 2</li></ol>) // 只有一个ol元素
拆解XML
Scala中可以直接用基于XPath语言的工具处理XML。
抽取文本
取得去掉了标签以后的文本:
scala> <a>Sounds <tag/> good</a>.text res8: String = Sounds good
所有的编码字符会自动解码:
scala> <a> input ---> output </a>.text res9: String = input ---> output
抽取子元素
用类似XPath的\()方法查找得第一层子节点:
scala> <a><b><c>hello</c></b></a> \ "b" res10: scala.xml.NodeSeq = <b><c>hello</c></b>
用\\()方法代替\()方法搜索任意深度的子节点:
scala> <a><b><c>hello</c></b></a> \ "c" res11: scala.xml.NodeSeq = scala> <a><b><c>hello</c></b></a> \\ "c" res12: scala.xml.NodeSeq = <c>hello</c> scala> <a><b><c>hello</c></b></a> \ "a" res13: scala.xml.NodeSeq = scala> <a><b><c>hello</c></b></a> \\ "a" res14: scala.xml.NodeSeq = <a><b><c>hello</c></b></a>
Scala用\和\\代替了XPath里的/和//。原因是//会和Scala的注释混淆。
抽取属性
也是用\和\\,不过要加上@:
scala> val joe = <employee
| name="Joe"
| rank="code monkey"
| serial="123"/>
joe: scala.xml.Elem = <employee rank="code monkey" name="Joe"
serial="123"></employee>
scala> joe \ "@name"
res15: scala.xml.NodeSeq = Joe
scala> joe \ "@serial"
res16: scala.xml.NodeSeq = 123
属性不能用通配符,如:
img \ "@_"
是什么也查不到的。
与XPath不同,\()方法不能从多个节点里取得属性,下面这样:
doc \\ "img" \ "@src"
如果遇到有多个img元素的不行的,要用:
doc \\ "img" \\ "@src"
结果是序列
\()与\\()方法得到的结果是序列类型的。所以除非确信只有一个匹配的结果,否则
应该用遍历的方式来处理返回的结果:
for (n <- doc \\ "img") doSth()
如果对结果调用text会把文本串成一起
scala> (<img src="aa.jpg"/><img src="bb.jpg"/> \\ "@src").text res3: String = aa.jpgbb.jpg
对象与XML转换
序列化
从Scala内部结构到XML转换的例子。
以一个收集古董可口可乐温度计的数据库为例子。下面的内部类以目录形式保存条目。记录 了生产时间,购入时间,购买费用:
abstract class CCTherm {
val description: String
val yearMade: Int
val dateObtained: String
val bookPrice: Int // in US cents
val purchasePrice: Int // in US cents
val condition: Int // 1 to 10
override def toString = description
}
只要添加了toXML方法就可以把实例转为XML:
abstract class CCTherm {
...
def toXML =
<cctherm>
<description>{description}</description>
<yearMade>{yearMade}</yearMade>
<dateObtained>{dateObtained}</dateObtained>
<bookPrice>{bookPrice}</bookPrice>
<purchasePrice>{purchasePrice}</purchasePrice>
<condition>{condition}</condition>
</cctherm>
}
实际操作中的执行效果如下:
val therm = new CCTherm {
val description = "hot dog #5"
val yearMade = 1952
val dateObtained = "March 14, 2006"
val bookPrice = 2199
val purchasePrice = 500
val condition = 9
}
scala> val therm = new CCTherm {
| val description = "hot dog #5"
| val yearMade = 1952
| val dateObtained = "March 14, 2006"
| val bookPrice = 2199
| val purchasePrice = 500
| val condition = 9
| }
therm: CCTherm = hot dog #5
scala> therm.toXML
res6: scala.xml.Elem =
<cctherm>
<description>hot dog #5</description>
<yearMade>1952</yearMade>
<dateObtained>March 14, 2006</dateObtained>
<bookPrice>2199</bookPrice>
<purchasePrice>500</purchasePrice>
<condition>9</condition>
</cctherm>
注意,虽然CCTherm是抽象类,但是new CCTherm还是可以正常工作,因为这样的语法
实际上是实例化了CCTherm的匿名子类。
反序列化
把XML解析回对象:
def fromXML(node: scala.xml.Node): CCTherm =
new CCTherm {
val description = (node \ "description").text
val yearMade = (node \ "yearMade").text.toInt
val dateObtained = (node \ "dateObtained").text
val bookPrice = (node \ "bookPrice").text.toInt
val purchasePrice = (node \ "purchasePrice").text.toInt
val condition = (node \ "condition").text.toInt
}
使用时的效果:
scala> val node = therm.toXML
node: scala.xml.Elem =
<cctherm>
<description>hot dog #5</description>
<yearMade>1952</yearMade>
<dateObtained>March 14, 2006</dateObtained>
<bookPrice>2199</bookPrice>
<purchasePrice>500</purchasePrice>
<condition>9</condition>
</cctherm>
scala> fromXML(node)
res15: CCTherm = hot dog #5
读取和保存
保存
把XML转为字符串只要调用toString方法。
如果要把XML转换为字节文件可以使用XML.saveFull命令。参数:
- 文件名、
- 要保存的节点、
- 采用的字符编码、
- 是否在文件头上写上包含字符编码的XML声明、
-
XML的文档类型
scala.xml.dtd.DocType(null表示任意类型这里不深入讨论)。
例子:
scala.xml.XML.saveFull("therm1.xml", node, "UTF-8", true, null)
therml.xml的内容:
<?xml version='1.0' encoding='UTF-8'?>
<cctherm>
<description>hot dog #5</description>
<yearMade>1952</yearMade>
<dateObtained>March 14, 2006</dateObtained>
<bookPrice>2199</bookPrice>
<purchasePrice>500</purchasePrice>
<condition>9</condition>
</cctherm>
如果要保存一个XHTML,典型的例子是:
scala.xml.XML.saveFull("therm1.xml", node, "UTF-8", true,
DocType("html", PublicID( "-//W3C//DTD XHTML 1.0 Strict//EN",
"http://www.w3.org/TR/xhtml1/DTD/xhtml11-strict.dtd"), Nil)
)
把空节点写为自结束标签:
scala> val image = <img src="logo.jpg"></img> image: scala.xml.Elem = <img src="logo.jpg"></img> scala> val str = xml.Utility.toXML(image, minimizeTags = true) warning: there were 1 deprecation warning(s); re-run with -deprecation for details str: StringBuilder = <img src="logo.jpg"/>
PrettyPrinter类可提供更加美观的格式:
scala> val printer = new PrettyPrinter(width = 100, step = 4) printer: scala.xml.PrettyPrinter = scala.xml.PrettyPrinter@73aa0439 scala> val str = printer.formatNodes(image) str: String = <img src="logo.jpg"></img>
加载
读取文件比保存简单,只要调用xml.XML对象的loadFile方法并传入文件名:
scala> val loadnode = xml.XML.loadFile("therm1.xml")
loadnode: scala.xml.Elem =
<cctherm>
<description>hot dog #5</description>
<yearMade>1952</yearMade>
<dateObtained>March 14, 2006</dateObtained>
<bookPrice>2199</bookPrice>
<purchasePrice>500</purchasePrice>
<condition>9</condition>
</cctherm>
scala> fromXML(loadnode)
res14: CCTherm = hot dog #5
也可以从java.io.InputStream、java.io.Reader或URL加载:
val root2 = XML.load(new FileInputStream("myfile.xml"))
val root3 = XML.load(new InputStreamReader(
new FileInputStream("myfile.xml"),"UTF-8"))
val root4 = XML.load(new URL("http;//horstmann.com/index.html"))
例子:读取保存多条记录
数据文件:
<symbols> <symbol ticker="AAPL"><units>200</units></symbol> <symbol ticker="ADBE"><units>125</units></symbol> <symbol ticker="ALU"><units>150</units></symbol> <symbol ticker="AMD"><units>150</units></symbol> <symbol ticker="CSCO"><units>250</units></symbol> <symbol ticker="HPQ"><units>225</units></symbol> <symbol ticker="IBM"><units>215</units></symbol> <symbol ticker="INTC"><units>160</units></symbol> <symbol ticker="MSFT"><units>190</units></symbol> <symbol ticker="NSM"><units>200</units></symbol> <symbol ticker="ORCL"><units>200</units></symbol> <symbol ticker="SYMC"><units>230</units></symbol> <symbol ticker="TXN"><units>190</units></symbol> <symbol ticker="VRSN"><units>200</units></symbol> <symbol ticker="XRX"><units>240</units></symbol> </symbols>
加载:
import scala.xml._
val stocksAndUnits = XML.load("stocks.xml")
println(stocksAndUnits.getClass())
println("Loaded file has " + (stocksAndUnits \\ "symbol").size +
" symbol elements")
解析数据到一个Map里:
import scala.collection.mutable.Map
val stocksAndUnitsMap =
(Map[String, Int]() /: (stocksAndUnits \ "symbol")) { (map , symbolNode) =>
val ticker = (symbolNode \ "@ticker").toString
val units = (symbolNode \ "units").text.toInt
map(ticker) = units //Creates and returns a new Map
map
}
println("Number of symbol elements found is " + stocksAndUnitsMap.size)
生成新的xml,每条记录的值加1:
def updateUnitsAndCreateXML(element : (String, Int)) = {
val (ticker, units) = element
<symbol ticker={ticker}>
<units>{units + 1}</units>
</symbol>
}
val updatedStocksAndUnitsXML =
<symbols>{ stocksAndUnitsMap.map { updateUnitsAndCreateXML } }</symbols>
保存到文件:
XML save ("stocks2.xml", updatedStocksAndUnitsXML)
println("The saved file contains " + (XML.load("stocks2.xml") \\ "symbol").size
+ " symbol elements")
解析器
默认的加载工具是Java的SAX解析器,它不会从本地编目而是从w3c.org读取DTD。尤其是 处理XHTML时会这种行为花非常长的时间。
JDK的com.sun.org.apache.xml.internal.resolver.tools包中的CatelogResolver类或
Apache Commons Resolver提供的版本:
http://xml.apache.org/commons/components/resolver/resolver-article.html
XML对象没有接口可以用来安装实体解析器,只能通过后门来达到目的:
val res = new CatalogResolver
val doc = new factory.XMLLoader[Elem] {
override def adapter = new parsing.NoBindingFactoryAdapter() {
override def resolveEntity(publicId: String, systemId: String) = {
res.resolveEntry(publicId, systemId)
}
}
}.load(new URL("http://horstmann.com/index.html"))
命名空间
和Java或Scala中的包一样,XML通过xmlns属性指定命名空间,其形式类似URI:
<html xmlns="http://www.w3.org/1999/xhtml"> <head></head> <body></body> </html>
html元素和所有的子元素(head、body等)都是在命令空间中的。子元素也可以导入
自己的命名空间:
<svg xmlns="http://www.w3.org/2000/svg" width="100" height="100"> <rect x="25" y="25" width="50" height="50" fill="#ff000000" /> </svg>
混用多个命名空间时,可以用「命令空间前缀」来给长长的命名空间起别名:
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:svg="http://www.w3.org/2000/svg" >
用svg来代替http://www.w3.org/2000/svg,所有svg:开关的都代表该命名空间:
<svg:svg width="100" height="100"> <svg:rect x="25" y="25" width="50" height="50" fill="#ff000000" /> </svg:svg>
每个Elem对象都有prefix和scope值,解析器会自动设置这些值。然后可以用
scope.uri得到命名空间。代码创建里的XML元素要手动设置prefix和scope:
scala> val scope = new NamespaceBinding("svg", "http://www.w3.org/2000/svg",
| TopScope)
scope: scala.xml.NamespaceBinding = xmlns:svg="http://www.w3.org/2000/svg"
scala> val attrs = Attribute(null, "width", "100", Attribute(
| null, "height", "100", Null))
attrs: scala.xml.Attribute = width="100" height="100"
scala> val elem = Elem(null, "body", Null, TopScope, Elem(
| "svg", "svg", attrs, scope))
warning: there were 2 deprecation warning(s); re-run with -deprecation for details
elem: scala.xml.Elem = <body><svg:svg width="100" height="100"
xmlns:svg="http://www.w3.org/2000/svg"/></body>
XML的模式匹配
XML的模式很像字面量,差别在于如果加入转义花括号,那么花括号里的不是表达式而是
模式。{}里的模式可以使用所有的Scala模式语言,包括绑定新变量、执行类型检查、
使用_和_*忽略内容。例如:
def proc(node: scala.xml.Node): String =
node match {
case <a>{contents}</a> => "It's an a: "+ contents
case <b>{contents}</b> => "It's a b: "+ contents
case _ => "It's something else."
}
上面的代码前两个把a和b标签的内容放到变量contents里。最后一个匹配以外的所有
情况。调用的效果如下:
scala> proc(<a>apple</a>) res16: String = It's an a: apple scala> proc(<b>banana</b>) res17: String = It's a b: banana scala> proc(<c>cherry</c>) res18: String = It's something else.
如果是嵌套的标签:
scala> proc(<a>a <em>red</em> apple</a>) res19: String = It's something else. scala> proc(<a/>) res20: String = It's something else.
这样的情况要执行对节点序列而不是单个节点的匹配。「任意序列」XML节点的模式写为_*
,看起来这个像是通配模式_后加上正则表达式风格的克莱尼星号(Kleene star)。
更新后的函数用子元素序列的匹配取代了对单个子元素的匹配:
def proc(node: scala.xml.Node): String =
node match {
case <a>{contents @ _*}</a> => "It's an a: "+ contents
case <b>{contents @ _*}</b> => "It's a b: "+ contents
case _ => "It's something else."
}
注意_*的结果是通过使用@模式绑定到了contents变量。执行效果如下:
scala> proc(<a>a <em>red</em> apple</a>)
res21: String = It's an a: ArrayBuffer(a ,
<em>red</em>, apple)
scala> proc(<a/>)
res22: String = It's an a: Array()
只能处理单个节点
case语句中只能处理一个结点,下面的形式是不可以的:
case <p>{_*}</p><br /> => ...
没有子结点
匹配可能属性,但不能有子节点的标签:
node match {
case <img/> => ...
...
}
只有一个子节点
匹配只有一个子节点:
case <li>{_}</li> => doSth() // 非法
多个子节点
匹配有多个子节点,如:
<li>An <em>important</em> item</li>
可用:
case <li>{_*}</li> => doSth()
绑定变量
用变量取得匹配的内容:
case <li>{child}</li> => child.text
匹配一个文本节点:
case <li>{Text(item)}</li> => item
绑定节点序列到变量
绑定节点序列到变量:
case <li>{children @ _*}</li> => for (c <- children) yield c
匹配属性
XML模式匹配不能有属性:
case <img alt="TODO"/> => doSth() // 非法
匹配属性要结合守卫模式:
case n @ <img/> if (n.attributes("alt").text == "TODO") => doSth()
要注意XML模式能很好地与for表达式一起工作,迭代XML结构树的某些部分而忽略其他部分 。例如希望在下面的XML结构中路过记录之间的空白:
val catalog =
<catalog>
<cctherm>
<description>hot dog #5</description>
<yearMade>1952</yearMade>
<dateObtained>March 14, 2006</dateObtained>
<bookPrice>2199</bookPrice>
<purchasePrice>500</purchasePrice>
<condition>9</condition>
</cctherm>
<cctherm>
<description>Sprite Boy</description>
<yearMade>1964</yearMade>
<dateObtained>April 28, 2003</dateObtained>
<bookPrice>1695</bookPrice>
<purchasePrice>595</purchasePrice>
<condition>5</condition>
</cctherm>
</catalog>
看起来好像catalog元素有两个节点,实际上所有的空白字符也是作为节点的。所以还有
前面的、后面的、以及两个元素之间的空白,实际上有五个!如果没有注意到这些空白,
或许会错误地像下面这样处理温度计的记录:
catalog match {
case <catalog>{therms @ _*}</catalog> =>
for (therm <- therms)
println("processing: "+
(therm \ "description").text)
}
processing:
processing: hot dog #5
processing:
processing: Sprite Boy
processing:
可以发现所有的代码行都在尝试把空白当作记录处理,而实际上应该只处理在cctherm
元素之间的子节点。模式<ccterm>{_*}</ccterm>可以描述这个子集,并限制for表达式
枚举能够匹配这个模式的条目:
catalog match {
case <catalog>{therms @ _*}</catalog> =>
for (therm @ <cctherm>{_*}</cctherm> <- therms)
println("processing: "+
(therm \ "description").text)
}
processing: hot dog #5
processing: Sprite Boy
还有一个统计真实元素个数的方法:
(catalog \\ "cctherm").size
修改元素和属性
Scala中XML节点和节点序列都是不可变的,要copy方法编辑复本。copy方法有五个参数
:
- lable
- attributes
- child
- prefix
- scop
不传值给参数会把原来的元素复制过来,也可以通过传名参数指定参数的值:
scala> val list = <ul><li>Fred</li><li>Wilma</li></ul> list: scala.xml.Elem = <ul><li>Fred</li><li>Wilma</li></ul> scala> val list2 = list.copy() list2: scala.xml.Elem = <ul><li>Fred</li><li>Wilma</li></ul> scala> val list2 = list.copy(label = "ol") list2: scala.xml.Elem = <ol><li>Fred</li><li>Wilma</li></ol>
添加子节点:
scala> list.copy(child = list.child ++ <li>Another item</li>) res0: scala.xml.Elem = <ul><li>Fred</li><li>Wilma</li><li>Another item</li></ul>
修改或添加属性用操作符%添加Attribute实例。Attribute的构造方法格式为:
Attribute(命名空间, 属性, 值, 额外的元数据列表)
scala> import scala.xml._ import scala.xml._ scala> val image = <img src="hamster.jpg"/> image: scala.xml.Elem = <img src="hamster.jpg"/> scala> val image2 = image % Attribute(null, "alt", "An image of a hamster", Null) image2: scala.xml.Elem = <img alt="An image of a hamster" src="hamster.jpg"/>
注意:scala.xml.Null是一个空属性列表,不是scala.Null类型
添加多个属性,放在最后一个参数里:
scala> val image3 = image % Attribute(null, "alt", "An image of a hamster",
| Attribute(null, "alt", "An image of a hamster", Null))
image3: scala.xml.Elem = <img alt="An image of a hamster" src="hamster.jpg"/>
同一个属性只能有一个值,新的值会覆盖前一个值。
批量XML变化
RuleTransformer类批量重写符合指定条件的后代。把一个或多个RewriteRule实例应用
到某个节点及其子节点。
例如,把ul节点修改为ol,可以定义一个RewriteRule并重写transform方法:
scala> import scala.xml.transform._
import scala.xml.transform._
scala> val rule1 = new RewriteRule {
| override def transform(n: Node) = n match {
| case e @ <ul>{_*}</ul> => e.asInstanceOf[Elem].copy(label = "ol")
| case _ => n
| }
| }
rule1: scala.xml.transform.RewriteRule = <function1>
应用:
scala> val root = <ul><li>item 1</li></ul> root: scala.xml.Elem = <ul><li>item 1</li></ul> scala> val transformed = new RuleTransformer(rule1).transform(root) transformed: Seq[scala.xml.Node] = List(<ol><li>item 1</li></ol>)
RuleTransformer的构造器中可以传入多个规则作为参数:
new RuleTransformer(rule1, rule2, rule3)