SQL优化
计算非重复结果数目
计算非重复的数目是SQL分析的一个灾难,显然,我们要在第一篇博文上讨论。
首先一点:我们如果有一个很大的数据集而且可以容忍它不精确。一个像HyperLogLog的 概率统计器可能是你的首选(我们在以后的博客中会讲到HyperLogLog ),但是要追求 快速精准的结果,子查询的方法会节省你很多时间。
让我们从一个简单的查询语句开始吧:哪一个dashboard用户访问的最频繁。
SELECT dashboards.name, COUNT(DISTINCT time_on_site_logs.user_id) FROM time_on_site_logs JOIN dashboards ON time_on_site_logs.dashboard_id = dashboards.id GROUP BY name ORDER BY COUNT DESC;
首先,让我们假设在user_id和dashboard_id上都有高效的索引,并且日志行数要比
user_id和dashboard_id多很多。
仅仅一千万行数据,查询语句就花费了48秒的时间。知道为什么吗?让我们看一下明了的 图解吧。
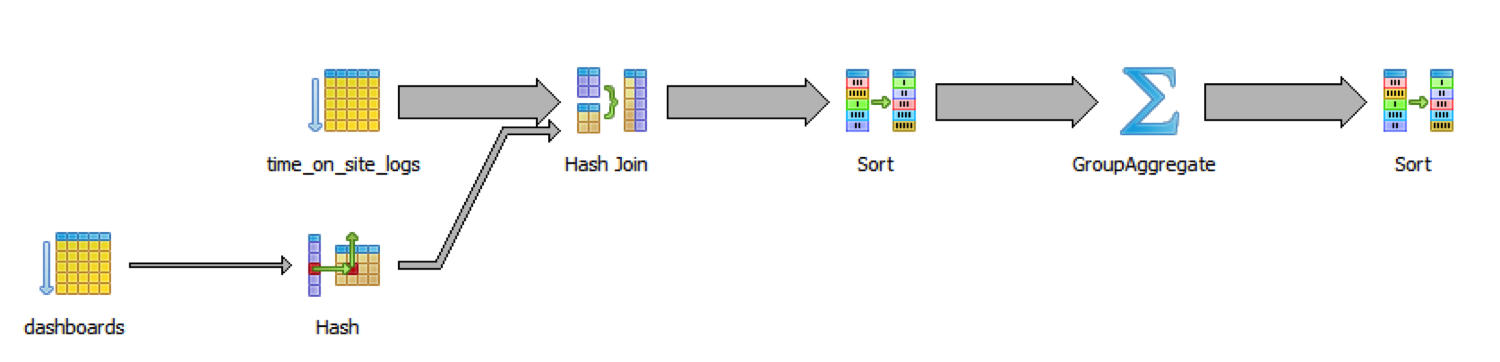
慢的原因是数据库要遍历dashboards表和logs表的所有记录,然后JOIN操作,然后
排序,之后才进行实际需要的分组和聚集操作。
先聚集,然后联合数据表
分组和聚集之后,一切数据库操作的代价都变小了,因为数据的数量变小了。在分组和
聚集的时候,因为我们不需要dashboards.name,所以我们可以在JOIN操作前先进行
聚集操作:
SELECT
dashboards.name,
log_counts.ct
FROM dashboards
JOIN (
SELECT dashboard_id,
COUNT(DISTINCT user_id) AS ct
FROM time_on_site_logs
GROUP BY dashboard_id
) AS log_counts
ON log_counts.dashboard_id = dashboards.id
ORDER BY log_counts.ct DESC;
语句运行了24秒,获得了2.4倍的性能提高。在来看一下,图解可以清楚无误的表明原因。
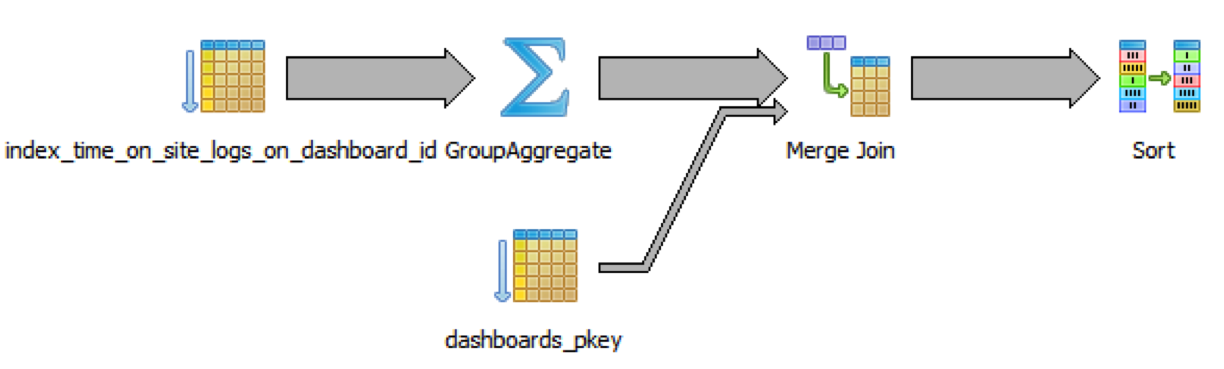
像我们预期地那样,join操作之前先进行了group-and-aggregate操作。快上加快,我们
还可以在time_on_site_logs表上加上索引。
第一步,让你的数据变小
我们还可以做的更好,我们对日志表做group-and-aggregate操作时,我们处理了一些
无关的数据,其实没有必要。我们可以对每个分组上创建一个哈希集合,这样,在每个
哈希桶中让每个dashboard_id挑出那些需要被看到处理的数据。
不用做那么多工作,只用一个哈希集合,我们就可以先去除那些重复的值。然后我们在 这个结果上做聚集操作。
SELECT dashboards.name, log_counts.ct
FROM dashboards
JOIN (
SELECT distinct_logs.dashboard_id,
COUNT(1) AS ct
FROM (
SELECT DISTINCT dashboard_id, user_id FROM time_on_site_logs
) AS distinct_logs
GROUP BY distinct_logs.dashboard_id
) AS log_counts
ON log_counts.dashboard_id = dashboards.id
ORDER BY log_counts.ct DESC;
我们让去重和分组聚集一步一步进行,分成两个阶段。首先在(dashboard_id, user_id)
对上去重,然后在这基础上做简单快速的分组计算工作,JOIN操作还是放在最后。

让我们来揭晓最终效果:总共花费了0.7秒,是上一次的28倍,最初的68倍。
一般来说,数据大小和数据位置是很重要的,表中的属性字段的可能取值个数相对很少,
所以才有那么明显的效果,与数据总量相比较,(user_id, dashboard_id)对的不同值
很少。越多的不同的值,各行的数据越分散,所以分组和计算它们花费越长的时间,果然
天下没有白吃的午餐。
也许你下次计算非重复结果需要花费一天的时间,试着用子查询的方法减轻它的负载。
要问一下,你们是何许人也
我们做了Periscope,一个可以使SQL数据分析更快的工具。 我们在这里分享一下我们的工具蕴含的算法和技术。你可以到我们的主页上注册,从而 作为我们的新客户,我们可以通知你相关事宜。
where条件中函数会让索引无效
查询出所有2012年的行:
CREATE INDEX tbl_idx ON tbl (date_column); SELECT text, date_column FROM tbl WHERE TO_CHAR(date_column, 'YYYY') = '2012';
这是「坏实践」,原因是虽然在date_column上有索引,但是在date_column字段上加了
函数以后,索引就失效了。
这是我平时工作中最常见的一个问题,当你在VARCHAR 类型的字段上使用UPPER, TRIM等 函数时同样会碰到这个问题。
MYSQL不支持function-based indexes而Oracle 和 PostgreSQL支持。Function-based
索引允许你使用索引表达式像TO_CHAR(date_column, 'YYYY')
很有效果的改进是不在索引字段上使用函数:
SELECT text, date_column
FROM tbl
WHERE date_column >= TO_DATE('2012-01-01', 'YYYY-MM-DD')
AND date_column < TO_DATE('2013-01-01', 'YYYY-MM-DD');
索引字段不必改变。这种解决方案很灵活,因为它支持广泛的类型——星期或月份。这是 我推荐的解决方案。
索引过之后的TOP-N查询
这个问题看着有性能危险,但其实不是。一般看来order by一定会对数据排序,然而这个 索引,使你没有没有必要对整个数据集排序,所以它就像查询唯一索引键一样快。
我看到人们平时建立缓存表,恰恰为了避免我们介绍这种查询,经常被计划任务填满。 有趣的是这种日常任务经常引起性能问题,因为它需要在很小的时间间隔内确认缓存表中 是否存在新的数据。然而,正确的索引应该是你的第一选择。
我要提一下Oracle 数据库使用者要特别注意一下这个技巧。到12c 版本的Oracle数据库 仍然没有提供像LIMIT or TOP等便利的语法糖。你可以使用ROWNUM的伪式的数据列。
SELECT *
FROM (
SELECT id, date_column
FROM tbl
WHERE a = :a
ORDER BY date_column DESC
)
WHERE rownum <= 1;
另一个争论是如果包含ID列将允许 index-only scan,尽管这是正确的,但我不认为 不这样做就是一个「坏实践」。因为查询的只有一行。index-only scan可以避免单表访问, 很多情况下你可以使用它提高性能,但一般情况下我认为这是一种过早优化,这是只是 我的观点。
但这个争论可以让我们看到PostgreSQL 使用者获得最好的分数。PostgreSQL直到9.2版本 才有index-only scans。在2012年九月才发布这个特性。因此PostgreSQL 没有掉入认为 只有index-only scan才能提高性能的陷阱。
索引列的顺序
CREATE INDEX tbl_idx ON tbl (a, b); SELECT id, a, b FROM tbl WHERE a = ? AND b = ?; SELECT id, a, b FROM tbl WHERE b = ?;
这是一个坏实践,因为第二个查询语句没有正确地使用索引。把索引列的顺序改为
(b, a)可以使两个查询语句都能使用索引从而获得很高的性能。在b上再加一个索引,
从而无缘无故的带来了很大的性能开销。不幸地是我看到很多人都这么做。
这也是一个我每天都遇到的问题,人们就是不知道复合索引是怎么工作的。
不同数据库的使用者的回答很接近,可能是因为(不同数据库)没有很大语法区别和的 特性影响回答的结果。Oracle的不为人知的Skip Scan特性有很小的影响。通常来讲 index-only scan 的意识可能有影响,但这次它的影响是让参与者更有可能回答对问题。
模糊查询
从性能上来看是好的实践还是坏的实践?
查询一个句子:
CREATE INDEX tbl_idx ON tbl (text); SELECT id, text FROM tbl WHERE text LIKE '%TERM%';
有性能危险,因为匹配符中使用了前缀通配符,反之如果使用匹配符TERM%就会更有效率
。大部分人都能回答对这个问题。我可以说大部分人还是知道LIKE 不是用来全文搜索的。
这一次PostgreSQL 使用者会犯错比较多。我们仔细审视一下PostgreSQL 面对的问题就 知道为什么了。
CREATE INDEX tbl_idx ON tbl (text varchar_pattern_ops); SELECT id, text FROM tbl WHERE text LIKE '%TERM%';
注意我们对索引字段的补充修饰(varchar_pattern_ops),在PostgreSQL中这个操作符类 使的索引对后缀通配符无效。我加上这个是想知道人们是否意识到在模糊查询是 前缀通配符会带来问题。没有操作符类,它不工作有两个原因:
- 前缀通配符;
- 没有操作符类,我认为这是显然的。
Index-only scan
第五个问题有点棘手,因为在这个测试开始时,PostgresSQL不支持 index-only scans。因此我稍微调整,两组的这个问题不一样。 MySQL, Oracle and SQL Server中是关于index-only scan。另一个是针对PostgresSQL 使用者出的关于索引列的顺序问题。我把结果都展示在这里。先看关于index-only scans:的问题。
从第一个到第二个查询性能会怎么改变?
从一百万行中选出一百行:
CREATE INDEX tab_idx ON tbl (a, date_column); SELECT date_column, count(*) FROM tbl WHERE a = 123 GROUP BY date_column;
从一百万行中选出十行
SELECT date_column, count(*) FROM tbl WHERE a = 123 AND b = 42 GROUP BY date_column;
这个问题有点不同,因为我给了四个答案:
- 查询性能大体相同
- 依赖数据的不同
- 查询会变很慢(影响>10%)
- 查询会变很快(影响>10%)
在我出这个测试的时候,我十分晓得五五分的答案没有什么意义,要在让参与者快速抓住 要点并回答和给出准确答案之间做权衡。
简单来说,正确答案是查询会变的很慢,因为原来的查询使用了index-only scan,这个 查询只使用了索引中的数据就能给出答案而不需要到实际的表中获取数据。第二个查询 需要检查数据列B,而数据列B不在索引中,因此数据库要花费多余的开销到拿出候选的行 来判断是否符合条件,它要从表中取出100行,这正是第一个查询中要返回的数据行数。 因为有group by操作,估计要取出更多的数据行,会使查询变的很慢。
因为有多个选项,总体分数明显下降,掉到了比「随便蒙」低39% or 14%。
我会说有39%的参与者知道正确答案这个结论是错误的,它们虽然给出了正确答案,但是我估计有25% 的人是蒙的。
分开各种数据库使用者后,结果更是无聊。
但是,我们仍然要看一下人们是怎么回答的:
我非常吃惊,「大体相同」 和 「依赖具体的数据」这两个选项都获得了25%的选择——它们可能 都是猜的。这是否表明一半的参与者只是在胡乱猜。还是因为这是最后一个问题,很多人 都想快点做完看看答案,恩,很有可能。然而正确答案「会变的很慢」获得了38.8%的选择, 导致只有10.9%的人选择「会变的很快」选项。
我的本意是把人误导选择「会变的很快」,因为后者数据量更少——只有使用了 index-only scan的情况下会变得不同,但是我假设我得到这个结果是因为人们通常会认为 很明显的答案肯定是错的。这样的话,我想验证多少人会知道index-only scan的本意根本 没有得到证明。
索引列顺序和范围操作符
这个问题只是给PostgreSQL 使用者的。
从性能上来看是好的实践还是坏的实践?
查询状态的X并且不超过五年的实体。
CREATE INDEX tbl_idx ON tbl (date_column, state); SELECT id, date_column, state FROM tbl WHERE date_column >= CURRENT_DATE - INTERVAL '5' YEAR AND state = 'X';
(365 rows)
数据分布如下:
SELECT count(*) FROM tbl WHERE date_column >= CURRENT_DATE - INTERVAL '5' YEAR; count ------- 1826 SELECT count(*) FROM tbl WHERE state = 'X'; count ------- 10000
参与者有两个选项:
- 好的实践 ,没有大的性能改进可以采用了。
- 坏的实践,有大的性能改进可以采用。
正确答案是「坏实践」,因为索引的数据列的顺序不对。通常的索引列排序是规律是,如果等号运算符放在左边就经常有很高的性能,过滤之后,再使用范围操作符也很有效率。然而,如果范围操作符放在左边,就会丧失索引的好处,之后的的索引列也不能高效率的使用。
像以上没有修改的查询语句,我们要在索引中找出1826个实体(它们都符合date_column 列的过滤),然后对它们进行state 列过滤。如果过滤顺序改变一下,数据库就使得两次过滤都很有效,直接把要过滤的行数限制在了365 行内。
人们不仅对次没有意识,而且大多数人都有了错误的理解。然而我得承认这个」大多数「是有水分的。当我运行这个例子时,快的不只是一倍,竟然加速了70%。