应用基础架构
需求分析
在之前对XMPP基础概念的介绍和对登录过程的详细描述中可以看到当前应用中需要解决的 问题有:
- TCP连接的建立与通讯
- XMPP文本片段的解析
- XMPP文本片段的发送与接收
- 登录验证
各主要功能的依赖关系如图\ref{fig:ch05.base.usecash.png}所示:
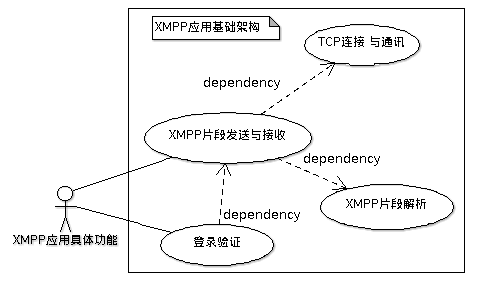
对于上层的应用来说,直接使用到的是「XMPP文本片段发送与接收」和「登录验证」这两个功能。在 「XMPP登录步骤」这一章中已经描述过XMPP协议的登录过程也是基于XMPP片段完成的,所以 登录验证过程是依赖于「消息的发送与接收」这一功能的。
由于XMPP协议是基于TCP连接的,所以实现TCP连接的建立与通讯是实现「消息的发送与接收 」这一功能的基础;而且正确地基于XMPP格式是接收与发送的XMPP片段前提条件,所以消息 的发送与接收也依赖于「XMPP文本信息的解析」这一功能。
概要设计
在完成了功能的需求以后,接下来可以对应用的功能模块进行规划。
如何封装IO模块
首先可以考虑消息的封装方法。在消息的传输过程中,消息实例的处理过程如图 \ref{fig:ch05.msg.process.png}:
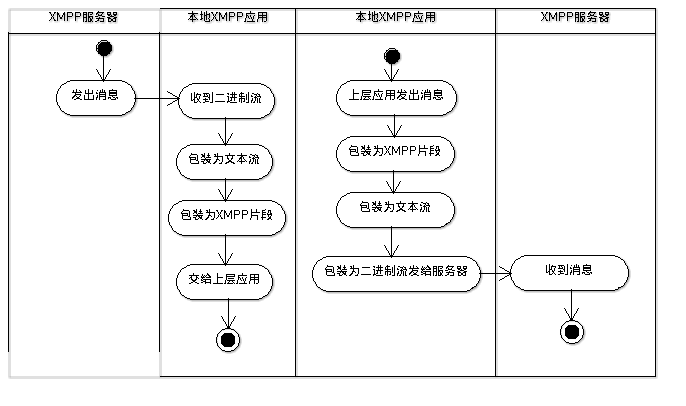
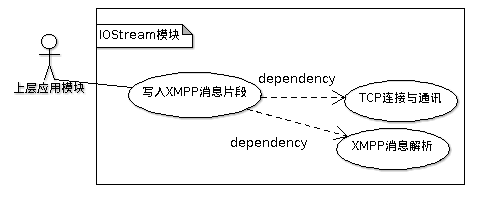
从上面的流程中可以看到,从底层的二进制流开始到转抽象为XMPP片段是一个完整而独立的 流程。因此适合把「TCP连接」、「XMPP文本信息的解析」、「消息的发送与接收」封装为一个 独立的模块IOStream。这样对于上层应用来说,IOStream就可以作为一个如图 \ref{fig:ch05.IOStream.Usecase.png}所示的一个黑箱,只要在需要发送消息时调用它 所开放接口发出XMPP片段即可,而可不用关心它内部的TCP连接与通讯、XMPP片段解析这 两个功能的具体实现,甚至都不需要知道这两个功能的存在。这样的设计符合软件工程中 「高内聚、低耦合」的设计模式\cite{plain:disgPtn}:
如何封装验证模块
验证功能并不用参与到整个XMPP协议的功能过程中。可以单独拿出来作为一个模块
AuthInfo,这样做的的好处是减少了IO模块的复杂性,在IO模块中不用考虑用户
验证的逻辑。
组合整个基础模块
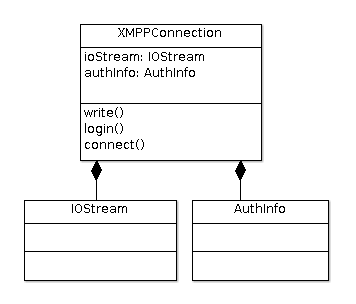
最后,定义一个XMPPConnection模块把IOStream和AuthInfo这两个模块包装越来,
对外统一提供三个方法connect()、login()和write()分别提供建立XMPP连接、
登录和发送XMPP消息片段服务,如图\ref{fig:ch05.base.class.png}所示:
在完成了对于项目整体的概要设计以后,就可以进一步对每个子模块进行详细的概要设计 了。
IOStream模块详细设计
IOStream作为提供网络连接、XMPP消息片段收发与XMPP消息片段解析众多主要功能的基础 模块,不仅是功能最多的模块、同时也是本系统中最复杂的模块。所以在实现过程中的 难度也是最大的。
不过只要对功能进行分割、规划合理,做到化繁为简还是可以成功地实现这个模块的。
连接信息配置:ConnectionConfig
作为实现了网络连接的模块,首先要考虑的就是与网络连接相关的配置信息。为了建立一个 TCP连接所需要提供相关的信息有:
-
serviceName:提供XMPP服务的服务器,可以通过IP地址或是域名指定。 -
port:服务器运行的服务所监听的端口。 -
username:登录服务器时需要的用户名。 -
password:登录服务器时需要的密码。 -
resource:XMPP协议的Resource,代表了一个连接的客户端。
所以需要一个类ConnectionConfig来存放这些配置信息。到目前为止,该类可以用
如下的类图\ref{fig:ch05.des-conn.01.png}描述:

为了真正实现连接配置ConnectionConfig类会需要更多的成员。随着进一步的研究,
这些额外的配置信息会逐渐被添加进去。
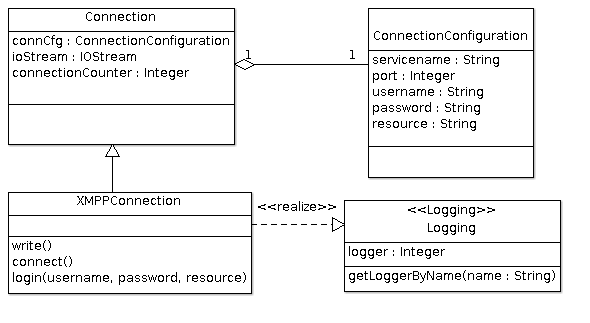
连接类抽象:Connection
ConnectionConfiguration里维护了建立一个XMPP连接所需要的配置信息,而程序运行
过程中所产生的连接实例则抽象为Connection类。Connection类的成员包含了连接
所建立的输入/输出流与连接计数器等内容,还有一个与当前连接所关联的
ConnectionConfiguration配置实例。
Connection作为一个抽象类,它的子类XMPPConnection实现了成员方法write、
connect、login。
Logging模块实现了日志功能的抽象,XMPPConnection通过实现它来得到公用的日志
服务。
这四个类型的关系如以下类图\ref{fig:ch05.des-conn.02.png}所描述:
Scala语言同时兼顾了面向对象与函数式编程的两方面特性。所以在Scala程序中也可以
像其他面向对象的程序一样使用继承机制。在这里XMPPConnection继承了Connection
类,同时这两个类都是抽象类。
Connection作为一个连接的高级抽象:
-
成员
connCfg保存连接服务器的所需要的配置,currHost保存了当前连接的服务器。 -
成员
ioStream保存了当前连接的输入输出流。
XMPPConnection作为子类继承Connection类。增加了主要方法有:
-
wirte()对输出流的写入数据。 -
connect()尝试与服务器建立连接。 -
login()用户登录。
整合日志功能
对于当今的任何应用来说,日志是一个不可缺少的功能。通过日志功能用户不仅可以观察 软件的运行状态,当程序执行发生错误时,还可以通过日志查看程序的执行堆栈信息,从而 发现错误的原因。slf4j是java平台上使用非常广泛的统一日志接口。可以通过配置文件 对日志格式进行配置:
<!-- 配置文件:src/main/resources/logback.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="stdout"
class="ch.qos.logback.core.ConsoleAppender">
<encoder charset="UTF-8">
<pattern>
%d{HH:mm:ss.SSS}[%thread]%-5level %logger{36}:%line-%msg%n
</pattern>
</encoder>
</appender>
<root level="DEBUG">
<appender-ref ref="stdout" />
</root>
</configuration>
然后就可以通过Logger类实例来定义logging类:
val logger = LoggerFactory.getLogger(this.getClass)
接下来的问题是如何把日志实例logger整合到现有类中去。
Scala中的特质(trait)类似于Java中的接口,但是Scala中的特质不仅可以声明方法
签名,还可以带有方法的实现。比如下面的特质Logging中的getLoggerByName()方法
就是有着具体实现的方法:
trait Logging {
lazy val logger = LoggerFactory.getLogger(this.getClass)
def getLoggerByName(name: String) = LoggerFactory.getLogger(name)
}
类似于Java类通过关键字implements实现接口,Scala的类与单例对象通过关键字with
「织入」的特质。然后就可以在类中使用特质中的方法与成员了:
abstract class XMPPConnection extends Connection with Logging {
public void doSomething() {
logger.info("doing something ...")
}
}
这样一个新的类XMPPConnection就可以在继承Connection类的同时又继承了Logging
物质的成员与方法。Scala特质与Java接口的区别与优势有:
Java中的抽象类与接口可以包含未实现的方法,它们有以下特征:
- 接口可以多继承,但接口中不能有方法实现。
- 抽象类不能多继续,但可以有方法实现。
这会带来一些限制。例如在需要实现java.util.List接口时,会发现必须实现List接口中 所有的抽象方法,这些方法包括:
- public int size()
- public boolean isEmpty()
- public boolean contains(Object o)
- 等等等
一共有23个抽象方法需要实现。这是作为接口的限制:接口里不能有方法实现。所以即使 有可重用的代码也不能放在接口里,只能放在抽象类中。但是如果用抽象类而不是接口 作为超类,又会遇到抽象类不可多继承的限制。
相反在Scala的特质没有Java接口的限制。一个Scala类可以像Java类实现多个接口一样 织入多个特质,而且每个特质中的方法还可以有默认的实现以便重用代码。所以, 在以后的代码中会看到大量使用Scala特质(trait)作为类型抽象的实现方式。
取得服务器全域名
为了正确连接服务器,通过域名来定位服务器就显得非常重要。\cite{plain:javaNet} 所以接下来要实现的就是域名解析的功能。
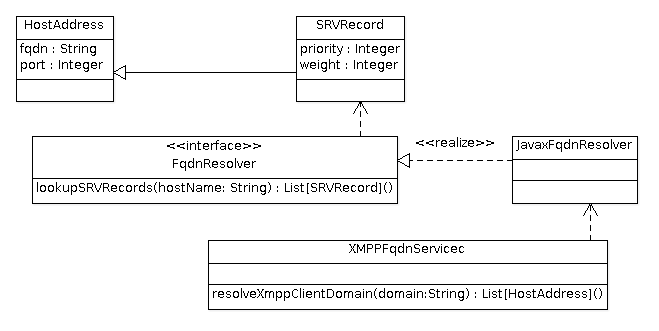
对于服务器的全格式域名(Fully Qualified Domain Name,简称FQDN)解析工作涉及到了 以下的类:
-
HostAddress定义一个地址的模型,包含地址与端口。子类SRVRecord增加了成员 优先级与权重。 -
FqdnResolver特质声明了解域名的接口,实现类是JavaxFqdnResolver。 -
XMPPFqdnService提供了针对XMPP服务的域名解析的功能。
这些类之间的关系如下图\ref{fig:ch05.des-fqdn.01.png}所示:
JavaxFqdnResolver中使用Java自带的InitialDirContext类实例来取得SRV记录。
通过正则表达式配解析SRV文本
在得到了返回的srvRecord文本记录的格式以后,下一个任务是从中提取「优先级」、「权重」 、「端口」和「主机」条部分来创建SRVRecord实例。对于从文本中提取需要的内容,最常用的 方式就是使用正则表达式。因为每一条srvRecord的格式都是固定的:
优先级 权重 端口 主机
因此用正则表达式^(\d+)\s(\d+)\s(\d+)\s(.+[^.])\.?$就可以很方便地取得所需要的
参数。
Scala的字符串原文照排功能
但是使用正则表达式会带来新的问题:对于字符串来说,有很多特殊字符都需要转义
(比如:「"」、「\」等转义字符),而且因为正则表达式语法的特殊性,这些需要
转义的字符在出现的频率还非常地高。所以用字符串来表以下达正则表达式时:
^(\d+)\s(\d+)\s(\d+)\s(.+[^.])\.?$
必须把所有的「\」转义为「\\」,所以就写成了:
^(\\d+)\\s(\\d+)\\s(\\d+)\\s(.+[^.])\.?$
这样无论在编写程序还是阅读源代码时,开发人员都要进行编程语言和正则表达式两层的 语法转义。代码变得复杂晦涩,在降低工作效率的同时,也增加了程序编写错误的可能。
为了增加直观性,Scala中用三个双引号可以表示原文照排字符串,它有一个优点就是不用 转义如换行、双引号、反斜杠之类的特殊字符。这样之前提取SRV记录的正则表达式又可以 直观地写为:
"""^(\d+)\s(\d+)\s(\d+)\s(.+[^.])\.?$"""
而且Scala对字符串增加了r()方法,以下的方法可以直接创建一个正则表达式实例:
val srvRegex= """^(\d+)\s(\d+)\s(\d+)\s(.+[^.])\.?$""".r
模式匹配
模式匹配是Scala中非常强大同时也是应用非常广泛的一项功能,它可以通过各种不同的 模式进行高度定制化的匹配功能。
简单以说,模式匹配类似于其他语言中常见的case语言。但是功能更加强大,几乎可以
用常量、类型、正则表达式等任何表达式作为匹配的条件。比如在本项目中可以直接检查
当前的SRV记录是否匹配指定的正则表达式srcRegex,并且把需要提取的内容存入对应的
局部变量priority、weight、port和host:
val srvRegex= """^(\d+)\s(\d+)\s(\d+)\s(.+[^.])\.?$""".r
srvRecords.next match {
case srvRegex(priority, weight, port, host) => {
result = new SRVRecord(host, port.toInt, priority.toInt,
weight.toInt) :: result
}
case _ => logger.error("SRV rec format error.")
}
以上的代码中直接根据提取出来的变量创建了SRVRecord实例。case _表示匹配所有
情况,在不匹配前一个条件(正则表达式)的情况下,则case _一定会被匹配,在这里
直接用日志记录发生错误。
加上子域名
这样,在组合使用了字符串原文照、正则表达式和模式匹配的方式以后。用非常简洁的
代码就可以完成从SRV文本记录中提取参数创建SRVRecord实例的目标。最后要注意的是,
要在域名上加上子域名,就可以得到服务器的完整域名。服务器端的子域名为
_xmpp-client._tcp。比如:
JavaxFqdnResolver.lookupSRVRecords("_xmpp-server._tcp" +
"." + domain)
建立Socket连接
在确定了服务器主机与服务所监听的端口以后,就可以建立Socket连接。建立连接最
简单的方法可以直接调用JDK自带的工厂类java.net.SocketFactory。
\cite{plain:sockJava}
图\ref{fig:ch05.socket.png}所示DirectSocketFactory是对工厂类的包装。
因为在本应用中用不到代理等复杂的配置:
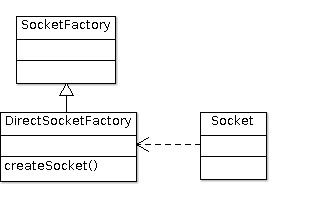
这样封装的目的是为了简化调用,通过方法:
def createSocket(host: String, port: Int): Socket
作为统一的接口创建Socket实例。
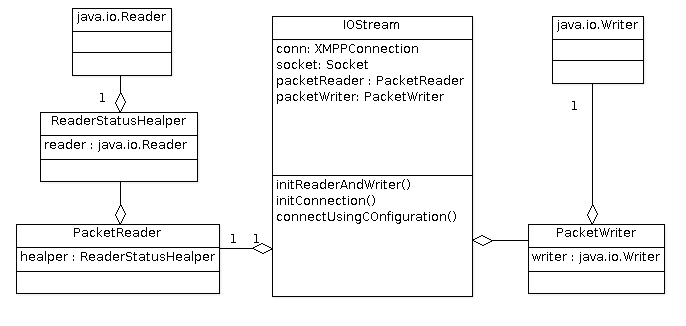
读写工具模块
读写模块的组成如图\ref{fig:ch05.des-io.01.png}核心是IOStream类,它的作用是
封装了XMPP消息报文的读写工具PacketReader和PackerWriter。
-
PacketWriter直接把需要发送的报文输出到
java.io.Writer。 -
PackerReader的作用是读取来自服务器的报文。但是在从
java.io.Reader取得的文本 必须要通过RdaderStatusHelper的处理才能被包装为XMPP报文。
判断XML是否读取完整
对于PackerWriter来说,因为需要发送的内容是自己产生的,所以知道消息的长度。
但是对于PackerReader来说,如果不检查所收到的文本就不知道服务器的报文是否已经
发送完毕。由于java.io.Reader的读取操作是阻塞式的,如果当服务器已经发送完报文
以后还继续执行读取操作会造成阻塞。这样造成的后果非常严重:整个消息的接收流程
被阻塞住了。所以在第一次从输入流中成功读取数据的以后都要马上检查当前读取的所有
内容是否已经是一个完整的XMPP消息片段。
ReaderStatusHelper是一个检查收到的文本是否符合XML语言格式的工具类。对于从
服务器收到的每一个字符它都结合已经收到的内容检查是否构成完整合法的XML文档:
-
如果已经收到的文本内容不能构成完整的XML文档,但也没有违反XML语法的,则
视为服务器还没有发完整个报文,继续从
java.io.Reader中读取更多文本。 - 如果已经收到的文本内容已经违反了XML语言的语法,则视为错误,抛弃已经收到内容 重新建立XMPP Stream。
- 如果收到的文本已经构成了完整的XML文档,就将这个文档作为XMPP报文进行解析。
ReaderStatusHelper的工作方式类似于一个有限状态机。状态变化如下图 \ref{fig:ch05.FSM-PackerStatehelper.png}所示:
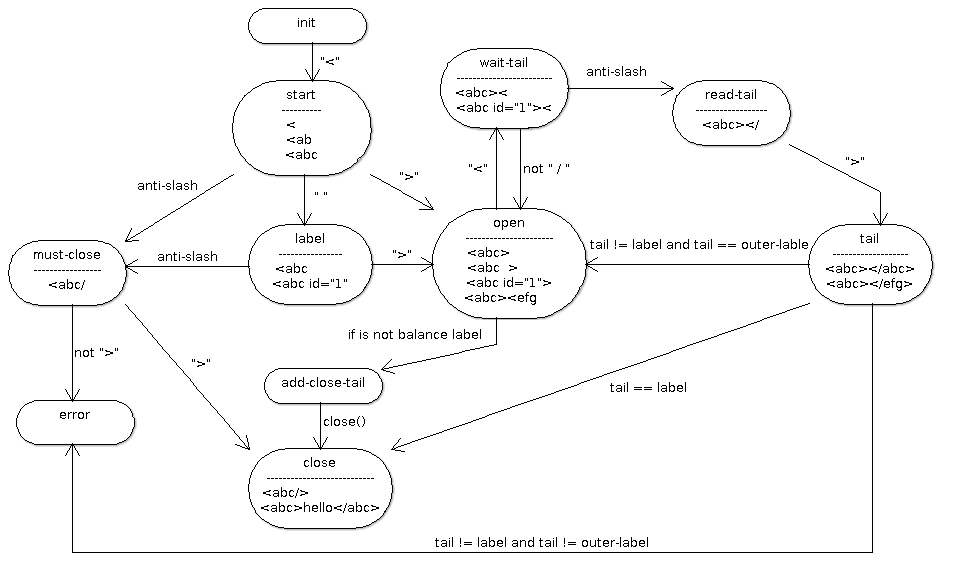
实现读取器辅助读取服务器消息
图\ref{fig:ch05.FSM-PackerStatehelper.png}中所描述的各种状态可以通过枚举类型
MsgStat来表示,枚举类型中定义的值有:
-
Start:XML开始。例如:「
<」 -
Label:正在接收开始标签。例如: 「
<msg」 -
Open:得到完整标签。例如: 「
<msg ...>」, 「<msg>」 -
WaitTail:等待标签结束。例如:「
<abc><」 -
ReadTail:已经开始接收结束标签。例如:「
<abc></」, 「<abc></efg」, 「<abc></abc」 -
Tail:结束标签接收中。例如:「
<abc></abc」, 「<abc></dfg」, 「<abc></abc」 -
MustClose:自关闭标签一定要关的状态。例如: 「
<msg/」, 「<msg /」, 「<msg id='5' /」 -
Close:标签结束,已经是一条完整的消息。例如:「
<msg>.....</msg>」, 「<msg/>」, 「<msg />」, 「<msg id='55' />」
主要逻辑在ReaderStatusHelper类的processBuffer()方法中。该方法按顺序逐个检查
读取的缓存中的内容,判断是否能构成完整的XML文档:
class ReaderStatusHelper (var reader: Reader, val processer: MessageProcesser)
extends Logging
{
/* process msg in buffer */
private[this] def processBuffer(buffer: Array[Char], len: Int)
}
processer是一个XMPP报文的处理器集合。从上面的代码中可以看到当状态为
MsgStat.Close时表示XML文档已经完整,processer会把这个完整的文档交给对应的
处理器进行下一步的处理。
并行执行任务
网络应用是典型的多个任务并行执行场景。以图\ref{fig:ch05.msg.process.png}所描述 的消息发送与接收流程为例,这两个操作就是相互独立的并行作业。如果不以并行作业的 方式而是以按照顺序执行的方式实现消息的接收与发送,那么一个操作就必须等待前一个 操作执行完毕才能执行。这样如果在执行消息接收操作时服务端没有消息发送过来,就会 阻塞了之后的所有操作,从而导致整个程序的执行都会被阻塞。所以消息的发送与接收 任务的执行方式必须采用并行执行。
为了实现并行执行任务有两个可选的方案:
- 传统的Java线程模型。
- 新兴的Actor模式。
Java线程模型的缺点
长久以来在Java平台上实现多任务并行执行的方式是使用Java语言所提供的线程模型: 为每一个需要并行执行的任务分配一个线程。然后通过Java语言所提供的API控制各个 线程之间的协同操作。
虽然JVM虚拟机屏蔽了底层操作系统了差异,通过统一的Java线程API简化了对线程的操作。 但是多线程应用本身还是非常复杂:
- 因为需要多个线程相互协作,所以需要控制一个线程执行到一半时暂停等待其他线程 完成特定任务的场景。当其他线程执行完成以后,还要再次唤醒某个暂停的线程。
- 因为有多个线程在并行执行,所以当有多个线程对同一个变量进行读写操作时,需要 保证该变量包存储数据的完整性。
由于以上所说的这些多个线程操作本身所具有的复杂性,在线程实践中很容易引发各种 错误,包括:内存栅栏、非原子性操作和线程死锁。\cite{plain:javaCurr}
内存栅栏
对于Java虚拟机来说,每个线程并不会直接操作所需要访问的变量,而是会对每个访问 的变量建立一个在当前线程中的副本(比如只是缓存在寄存器中)。所以当多个线程同时 对同一个变量进行操作时,由于直接操作的都是不同的副本,并不能看到其他线程对同 一个变量的操作后值的变化。这种不可见性被称为「内存栅栏」。\cite{plain:intoJVM}
非原子性操作
原子性操作是指不可被分割为多个子操作的最小操作单位。源代码中的一条语句在运行 时通常并不是一个单一的操作,比如在Java中对于一个64位长度的变量(比如long类型 或double类型)进行赋值操作会被JVM分解为两个32位变量的操作。
这在单个线程的运行环境中没有问题,因为这两个32位变量操作是顺序执行的。但是到了 多线程运行的场景下,就很有可能在第一个32位操作执行完成以后,CPU执行了另外一个 线程的指令,如果另外一个线程的指令是读取当前这个64位变量,那么它所读到的内容 就是错误的。
所以当多个线程操作同一个变量时,就必须保证这些线程操作的原子性。如果有非原子性 操作就很有可能会发生错误。
线程死错问题
因为有内存栅栏和非原子性问题的存在,必须要执行额外的操作以保证多线程环境下的 数据一致性和完整性:
- 在对变量进行修改与读取前都要对变量加锁,防止其他线程写入破坏数据,或是其他 线程读取了当前线程写入到一半的数据。
- 对变量的一系列操作完整执行以后,要及时释放锁。这样可以让其他需要访问该变量的 线程可以继续执行,并且释放锁的过程也会把当前线程缓存的变量值写回内存,防止 因为内存栅栏所导致各线程所持有的变量数据不一致。
- 当前线程执行的任务需要其他线程所执行的任务配合时,需要暂停当前线程等待其他 线程执行。其他线程执行完成后还要能再次唤醒本线程。
综上所述,为了让多个线程相互协调,需要让每个线程在如图\ref{fig:ch05.java.thd.png} 所示的不同的状态之间转换:
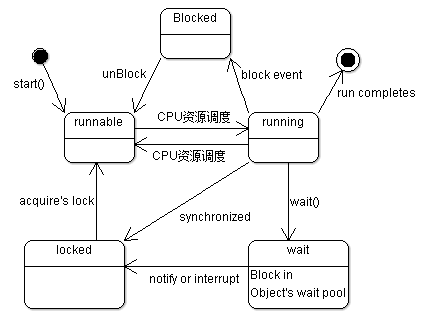
在这些复杂的操作过程中,最容易引发错误的环节就是对锁的取得与释放:
- 锁被其他线程占用时需要等待释放
- sleep()睡眠时,保持对象锁,仍然占有该锁;
- wait()睡眠时,释放对象锁。
如果存在多个线程相互等待已经被加锁的资源,就会造成死锁。而且一旦发生死锁开发人员 往往很难找到发生的原因。因为以多线程并发的场景中,各种线程执行的顺序并不能完全 确定,所以需要花费很大的精力梳理与排查各个线程之间的调用关系,才能查找到发生死锁 的原因,或是在开发过程中避免死锁。
用Actor模式代替线程操作
上一节已经介绍过,通过JVM的线程模型控制多线程操作的过程非常复杂。如果处理不当很 容易生成脏数据甚至是锁死的错误。相比之下,在Scala中引入的Actor模式能更加方便地 实现在多线程环境下的程序开发。
Actor模式推崇的哲学是「一切皆是Actor」,这与面向对象编程的「一切皆是对象」类似, 但是面向对象编程通常是顺序执行的,而Actor模式是并行执行的。 \cite{plain:scalaJvm}
Actor是一个运算实体,回应接收到的消息,同时并行地做到:
- 发送有限数量的消息给其他Actor;
- 创建有限数量的新Actor;
- 指定接收到下一个消息时的行为。
以上操作不含有顺序执行的假设,因此可以并行进行。
发送者与已经发送的消息解耦,是Actor模式的根本优势。这允许进行异步通信,同时满足 消息传递的控制结构。
消息接收者是通过地址区分的,有时也被称作「邮件地址」。因此Actor只能和它拥有地址 的Actor通信。它可以通过接收到的信息获取地址,或者获取它创建的Actor的地址。
Actor模式的特征是,Actor内部或之间进行并行计算,Actor可以动态创建,Actor地址 包含在消息中,交互只有通过直接的异步消息通信,不限制消息到达的顺序。
使用Actor实现并行作业
首先,在Actor模式中,每个Actor的实例都可以理解为一个与其他作业相独立的、
可以并行运行的作业。在Scala中创建一个Actor是非常方便的,只要织入
scala.actors.Action特质就可以了。Actor特质有一个act()方法,方法中的内容
就是一个独立的作业。
比如下面的例子,通过织入Actor特质实现了Job1和Job2两个作业,分别身终端输出五次
aaa和bbb。这两个作业是并行执行的:
import scala.actors.Actor
object Job1 extends Actor {
def act() {
var i = 5
while (i > 0) {
println("aaa")
i = i -1
Thread.sleep(5 * 1000)
}
}
}
object Job1 extends Actor {
def act() {
var i = 5
while (i > 0) {
println("bbb")
i = i -1
Thread.sleep(3 * 1000)
}
}
}
Job1.start()
Job2.start()
多个Actor之间实现协作
然后,是协作问题。虽然之前的例子显示了每个Actor代表的作业是如何并行执行的, 但是如果各个并行执行的作业之间无法相互通信的话,是没有办法让它们协同合作完成 复杂任务的。
scala.actors.Actor类的的成员方法「!()」就是用来实现作业间相互通信的。对于每一个
Actor实例来说,内部都有一个消息队列。对某个Actor实例调用!()方法就会发着一个
消息给它,所有的消息都放在消息队列里等待被处理:
Job1.!("Hello!")
对于方法调用,Scala允许在不引起歧义的情况下省略括号与点号。所以上面的语句可以 简写为:
Job1 ! "Hello!"
好处是让成员方法「!()」看起来更加像是一个操作符「!」而不是一个函数。这种简化
写法在Scala程序中被广泛地使用。
Actor实例会把所有发给它的消息都放到自己的消息队列里,如果要对这些消息作出
处理,就要通过receive方法从消息队列中取出消息:
object Job3 extends Actor {
def act() {
while (true) {
receive {
case msg => println("received message: "+ msg)
}
}
}
}
Job3 ! "Hello there"
以上代码演示了一个典型的Actor实例的工作方法:以一个无限循环不断读取消息队列, 如果有消息就做出对应的处理。
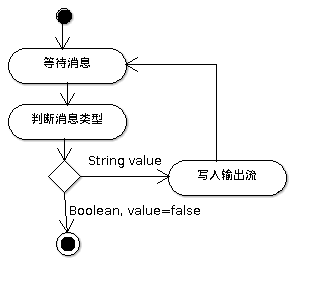
通过Actor模式实现异步的读写工具
结合到当前应用中,为了实现XMPP报文的发送,应用中需要PacketWriter作为一个
并行的作业不断检查它的消息队列里是否有收到消息。然后根据所收到消息的类型采取
对应的操作:
-
如果是布尔类型,根据其值为
true还是false来决定是不继续监听消息。 -
如果有字符串类型的消息
PacketWriter会把字符串的内容写入输入流。
类似的,需要把PacketReader作为一个Actor形成一个并行的作业不断地尝试从
输入流(也就是服务器)读取更多内容:
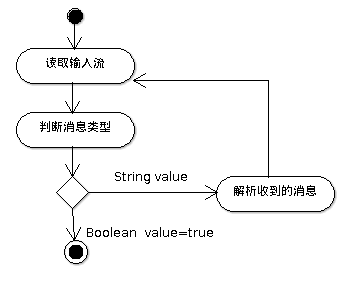
ReaderStatusHelper之前已经介绍过了,它会不断检查所读取的内容能否构成完整的
XML文档。
Scala对XML字面量的支持
到目前为止,PacketReader和ReaderStatusHelper已经完成了从输入流读取完整XML
文档的功能。接下来对于XML文档的解析功能比较简单,因为Scala本身提供了解析XML
的功能。
对于Scala语言,XML和Int、String一样可以简单地用字面量表示:
scala> val msg = <user><id>001</id><name>Tom</name></user> msg: scala.xml.Elem = <user><id>001</id><name>Tom</name></user>
Scala会自动根据XML字面量自动生成scala.xml.Elem的实例。
不仅有字面量,而且还可以用{}来引入Scala代码,如:
scala> <a> {"hello"+", world"} </a>
res1: scala.xml.Elem = <a> hello, world </a>
花括号里表达式不一定要输出XML节点,其他的类型Scala值都会被传为字符串:
scala> <a> {3 + 4} </a>
res3: scala.xml.Elem = <a> 7 </a>
解析XML
抽取子元素可以用类似XPath的\()方法查找得第一层子节点:
scala> <a><b><c>hello</c></b></a> \ "b" res10: scala.xml.NodeSeq = <b><c>hello</c></b>
用\\()方法代替\()方法搜索任意深度的子节点:
scala> <a><b><c>hello</c></b></a> \ "c" res11: scala.xml.NodeSeq = scala> <a><b><c>hello</c></b></a> \\ "c" res12: scala.xml.NodeSeq = <c>hello</c> scala> <a><b><c>hello</c></b></a> \ "a" res13: scala.xml.NodeSeq = scala> <a><b><c>hello</c></b></a> \\ "a" res14: scala.xml.NodeSeq = <a><b><c>hello</c></b></a>
Scala用\和\\代替了XPath里的/和//。原因是//会和Scala的注释混淆。
抽取属性也是用\和\\,不过要加上@:
scala> val joe = <employee
| name="Joe"
| rank="code monkey"
| serial="123"/>
joe: scala.xml.Elem = <employee rank="code monkey" name="Joe"
serial="123"></employee>
scala> joe \ "@name"
res15: scala.xml.NodeSeq = Joe
scala> joe \ "@serial"
res16: scala.xml.NodeSeq = 123
验证模块
Base64算法
Base64常用于处理文本数据的场合,表示、传输、存储一些二进制数据。是一种把 二进制数据转换为可显示字符串的数据序列化算法:
- 一般对于二进制数据都是用字节数组来表示的,因为每个字节有8位,所以一共有256种 可能性,无法用可显示的字符来表示每一个字节。
- Base64以每6个二进制位作为一个单元,这样只要64个字符就可以代表一个单元的所有 可能性。这样就实现了通过可显示文本来表示二进制数据的方式。
具体64个字符的映射规则如下:
-
0到25对应大写字母
A到Z -
26到51对应小写字母
a到z -
52到61对应数字
0到9 -
62和63分别对应符号
+和-
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法 进行处理:
先使用0字节值在末尾补足,使其能够被3整除,然后再进行Base64的编码。在编码后的 Base64文本后加上一个或两个'='号,代表补足的字节数。也就是说:
- 当最后剩余一个字节(byte)时,最后一个6位的Base64字节块有四位是0值, 最后附加上两个等号;
- 如果最后剩余两个字节(byte)时,最后一个6位的Base64字节块有两位是0值, 最后附加一个等号。
举个例子说明:
对于ASCII字符串「Manu」分别代表ASCII码77、97、110、117,用24位二进制表示为 「01001101、01100001、01101110、01110101」。
Base64重新以6位作为一个单元分割为「010011、010110、000101、101110、011101、 010000」,最后一段是「01」补上四个「0」,值分别为19、22、5、46、29、16。对应的 字符为「TWFudQ==」。
Scala程序调用Java代码
由于Base64算法是一种被广泛使用的代码,所以已经有很多开源的实现。而且由于本身 算法非常简单,没有做进一步研究的必要。可以直接使用现有的Base64实现。
Scala作为基于JVM虚拟机的语言对于Java程序的兼容性非常良好。可以方便地调用现成的 Java程序以实现代码重用。尤其是得益于Java在当今具有非常大的普及程度,有大量开源 的基础库可以使用,这给基于Scala的程序开发带来了非常大的便利。
对于Base64算法实现,在这里选择了用Java语言实现的开源工具net.iharder.Base64。
在Scala中重用Java程序的方法也和普通的Scala程序一样,用import导入对应的包就 可以:
import net.iharder.Base64
def encodeBase64(data: Array[Byte], offset: Int, len: Int,
lineBreaks: Boolean): String =
{
Base64.encodeBytes(data, offset, len, Base64.DONT_BREAK_LINES)
}
SSL相关配置
除了上述服务器、端口、用户名、密码等内容,为了实现安全连接,配置信息里还需要
包含用于SSL连接的TrustStore和KeyStore都放在这个连接信息的配置类
ConnectionConfiguration里。所需要对应的证书都可以直接用JDK中所自带的证书,
不用另外再生成,与证书相关的参数也都可以使用默认的值:
-
trustStorePath =
$JAVA_HOME/lib/security/cacerts - truststoreType = "jks";
- truststorePassword = "changeit"
- keystorePath = System.getProperty("javax.net.ssl.keyStore")
- keystoreType = "jks"
- pkcs11Library = "pkcs11.config"
ConnectionConfiguration类成员如图\ref{fig:ch05.cert.png}所示:

SASL认证
XMPP允许使用SASL认证方式与非SASL认证两种方式。所以为了结构清晰,先抽象一个超类
UserAuthentication,然后通过它的两个子类:
-
NonSASLAuthentication代表不使用SASL验证。 -
SASLAuthentication代表使用SASL验证。
在使用SASLAuthentication的情况下,还要考虑到具体实现SASL认证的机制。所以在这里
使用一个抽象类SASLMechanism来作为所有具体实现机制的超类。然后通过扩展出各个
子类来实现具体的SASL验证方式:
- SASLPain
- SASLCramMD5
- SASLDigestMD5
- SASLExtenal
- SASLGSSAPI
- SASLAnony
类图的结构如图\ref{fig:ch05.auth.class.png}所示:
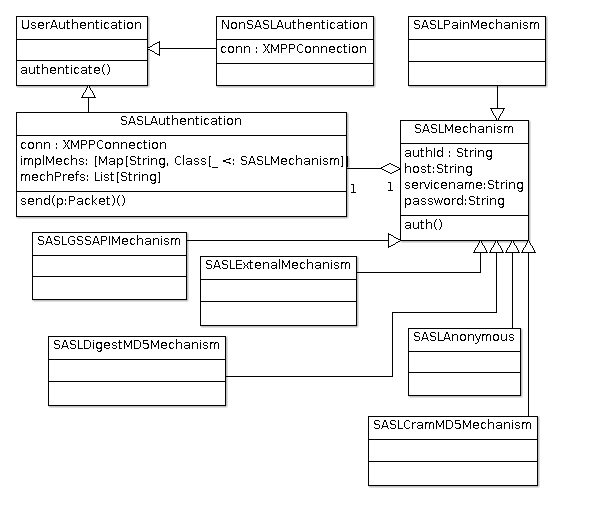
SASL验证的主要工作在类SASLAuthentication中,它的成员mechPerfs是一个字符串
列表,定义了当前客户端所支持的实现机制。
implMech使用一个Map建立的每种机制的名称与实现类之间的映射关系。Map的类型是
Class[_ <: SASLMechanism]表示值的成员是SASLMechanism类的子类类型。
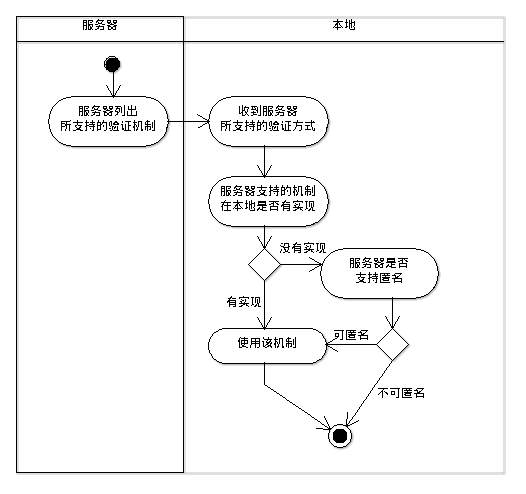
接下来要完成对SASL认证实现机制的选择,总体的逻辑是:
-
mechanismsPreferences列表中列出了本地实现的机制。 - 服务器会返回一个列表,列出了服务器端支持的机制。
- 在两个集合的交集中选一个作为当前连接的实现机制。
-
hasAnonmousAuthentication()检查服务器支持的实现机制中是否包含匿名方式。 -
hasNonAnonymousAuthentication()在确认服务器不支持匿名方式,但包含其他实现 机制的情况下,表示服务器不允许匿名登录。 -
defaultMechanism()方法定义了当存在多个可用的实现机制时,默认采用DIGEST-MD5。
SASLAuthentication的成员方法authenticate()会调用当前所选用的实现机制的
authenticate()方法来实现具体的认证工作:
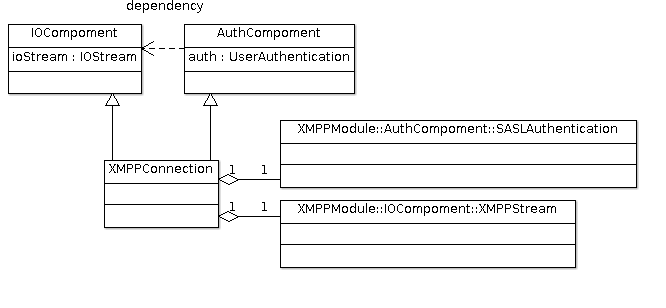
依赖注入
依赖注入是在模块化开发程序时经常被使用的一种编程模式。从结构上来看,本应用的 XMPP模块可以分成如图\ref{fig:ch05.jit.png}所示的「IO组件」和「验证组件」两部分。 而验证组件在验证登录的过程中,肯定要依赖于IO组件才能与服务器进行通信:
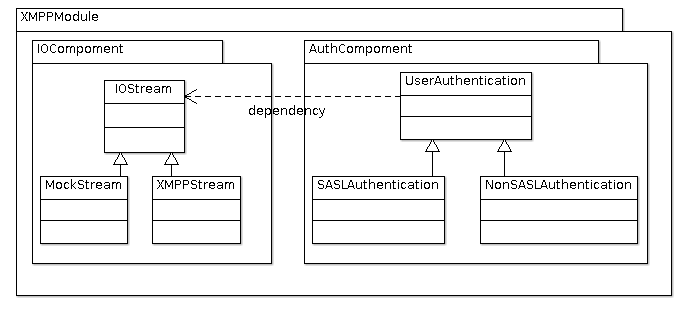
IOStream是代表着输入输出流的接口,它有两个实现类MockStream和XMPPStream:
-
MockStream是用来进行单元测试的,没有实现具体的功能。 -
XMPPStream是在XMPP应用中对输入输出流的封装,在实际应用中注入的是这个实现。
UserAuthentication是登录验证功能的抽象接口,它也有两个类:
-
NonSASLAuthentication实现了不带SASL验证的功能 -
SASLAuthentication实现了带SASL验证的功能。
但并不是所有的编程语言本身都可以支持依赖注入的实现方式。比如Java语言就需要依靠 Spring这样的第三方库才可以实现依赖注入的组织方式。而Scala可以通过自身语言所带的 语法直接实现依赖注入。
通过Spring框架实现注入
在Java中实现注入的方式是组合加上第三方库:
-
组合是指把
IOStream类和UwerAuthentication类作为XMPPConnection类的内部 成员。 -
因为Java语言不支持注入的语法,需要用到第三方库(比如:Spring)在程序初始化
过程中把指定的实例赋值给成员变量(比如把
XMPPStream类型的实例赋值给XMPPConnection中的ioStream)。
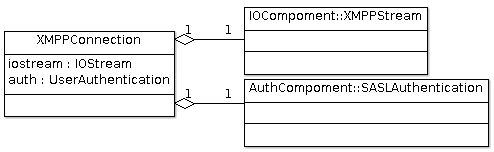
但是在使用Spring框架实现注入而不是使用编程语言本身的语法来实现注入,就会失去 源代码编译阶段的类型检查。
如果在Java程序中把MockStream类型的实例赋值给UserAuthentication类型变量
是肯定无法通过编译的,因为MockStream类型不是UserAuthentication的子类:
UserAuthentication auth = new MokeStream() // compile error
但是在使用Spring框架进行注入操作的时候,源代码中没有赋值的操作,赋值操作是发生
在程序运行过程中的初始化Spring容器阶段。所以说如果在Spring注入配置时错误地把
MockStream类型的实例赋值给XMPPConnection类的UserAuthentication类型成员
auth,源代码还是可以通过编译,但是会在程序运行的时候报错,带来了安全隐患。
通过Scala语法实现注入
而在Scala语言中,只要依赖语法中的:特质(Trait)、抽象成员与自身类 这三个语法特性,就可以实现依赖注入的组织方式。
用特质抽象接口
Scala中的特质(trait)类似于Java中的接口,是一种抽象的手段。但是特质比接口更加 灵活,不仅可以包含方法的声明,还可以包含方法的实现和成员变量。 \cite{plain:scalsForImp}
在这里IOCompoment和AuthCompoment可以定义为两个特质,ioStream和auth分别
是它们的成员:
trait IOCompoment {
val ioStream: IOStream
}
trait AuthCompoment {
val auth: UserAuthtication
}
和Java中类可以实现多个接口一样,Scala类中类可以继承多个特质。在Scala中这种继承
操作被称为「混入」,用关键字with表示。如图ref{fig:ch05.ijt.scala.png}所示,
XMPPConnection就混入了IOCompoment和AuthCompoment两个特质。代码为:
Object XMPPConnection extends IOCompoment with AuthCompoment
虽然混入特质用的是关键字with,但是跟在类名后的第一个特质要用关键字extends。
用自身类型定义依赖关系
Scala中的自身类型是为了限制「特质AuthCompoment只能被混入到IOCompoment类型或是 它的子类中」。语法为:
trait AuthCompoment { this: IOCompoment =>
val auth: UserAuthtication
}
因为AuthCompoment只能被混入到IOCompoment类型或是它的子类中,所以
AuthCompoment肯定也能访问到IOCompoment的成员ioStream。这样就确定了
AuthCompoment必须依赖于IOCompoment。
用抽象成员表示需要注入的成员
Scala中不仅可以指定方法为抽象,还可以声明字段甚至抽象类型为类和特质的成员。
如果不知道类中定义的确切内容,但是每个实例的值都是不可变的,那么可以使用抽象的
val声明。
以IOCompoment为例:
-
它的成员
ioStream是一个IOStream类型的抽象成员,而IOSteam有两个子类:MockStream和XMPPStream。在创建用于单元测试的IOCompoment实例时,它的isStream被赋值为MockStream类型实例;而在创建用于真实连接场景的IOCompoment实例时,它的isStream被赋值为的XMPPStream类型的实例。 -
同样它的成员
auth是一个UserAuthentication类型的抽象成员。根据不同的场景 也可以选择带有SASL验证的SASLAuthentication和不带SASL验证的NonSASLAuthentication。
从模块设计的角度来看,抽象类型的「不确定性」可以提供更多的可能性:
-
IOCompoment即可以用于测试也可以用于真实的连接。所以 它的ioStream成员的具体类型是不确定的。所以ioStream是抽象成员。 -
IOCompoment即可以用于带SASL也可以用于非SASL认证,所以它的auth成员具体类型 也是不确定的,所以auth也是抽象成员。
而到了具体的应用场景,成员的类型又是确定的。比如在用测试用例进行登录逻辑测试的
时候,要用假的MockStram来模拟与服务器的IO操作,而把带有SASL验证功能的
SASLAuthentication注入:
Object XMPPConnection extends IOCompoment with AuthCompoment {
val ioStream: IOStream = new MockStream
val auth: UserAuthtication = new SASLAuthentication
}
类似地,在最终发布的代码里,可以用真正的输入输出流实现类XMPPStream注入:
Object XMPPConnection extends IOCompoment with AuthCompoment {
val ioStream: IOStream = new XMPPStream
val auth: UserAuthtication = new SASLAuthentication
}
通过以上的介绍可以看到通过Scala语法所实现的依赖注入方式不仅具有和Spring框架同样 的灵活性,而且通过把需要注入的成员定义为抽象成员有以下两个优点:
- 抽象成员必须被实现,不然类就无法实例化。这样的编译源代码的阶段就可以防止有 变量被漏掉忘记注入的情况。
- 注入动作由Spring的配置操作改为Scala语言的赋值操作,如果注入的类型错误,在 编译时就可以被发现。
面向切面编程
如果说依赖注入解决了对程序中各个组件的划分与组装的问题,那么面向切面编程所要解决 的就是程序中各个业务逻辑的划分与组装问题。如图\ref{fig:ch05.aop.png}所展示的业务 流程为例,登录的过程分为:记录开始登录、执行登录逻辑、记录登录结果三步。
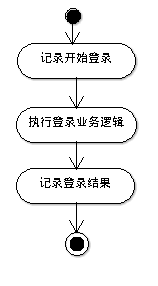
如果不把执行登录逻辑与记录日志的操作分开,那么每当日志输出的目标有变化,比如把 日志输出的目标从控制台改为文本文件或数据库,就要重新定义整个登录的过程。 所以为了提供代码的灵活性与可重用性,就有必要通过面向切面编程的方式对代码进行 解耦。
在Scala中实现面向切面的编程非常方便,因为Scala中的每一个特质都可以是一个切分业务
流程的切面。之前已经介绍过,Scala中的类可以通过混入多个特质实现多继承,而在每个
特质中,可以通过super()方法来取得左边的特质。
还是以登录功能为例:
trait UserAuthentication {
def authentication()
}
trait SASLAuthentication extends UserAuthentication {
def authentication() {
/* main auth logic */
}
}
trait AuthLogger extends UserAuthentication {
def authentication() {
prinln("before authentication")
super.authentication()
prinln("before authentication")
}
}
object DefaultAuthextends SASLAuthentication with AuthLogger
以上的代码在定义DefaultAuth时,SASLAuthentication的位置在AuthLogger
的左边,所以AuthLogger中调用的super.authentication()其实就是左边
SASLAuthentication的authentication()方法。
从Scala序列化为XML文档
XML文档非常适用于在网络传输与人类阅读;相反对于程序来说,处理与业务逻辑 相对应的类要比直接解析XML文本更加方便与高效。对于从服务器发送过来的文本在 客户端这一方可以把它视为一个只读的数据,并没有任何修改的必要,只要按需求 提取相关的XML命名空间、标签名、属性等内容的值即可。在之前的章节中已经看到 仅仅使用Scala语言本身对XML操作就可以很好地完成这样的工作。但是对于从本地 发送到服务器的XML文本因为内容是要在本地生成的,其中的各部分的值可能需要由 不同的业务模块产生。在这样的场景下重复地修改与传递字符串文本不仅操作麻烦而且 代码的可读性也不好,所以先用Scala类进行处理,然后等所有的处理逻辑都完成了以后 再序列化为XML文本发送到网络的工作方式会更加合适。
为XMPP报文抽象类
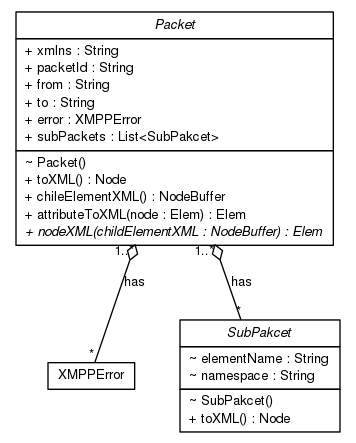
XMPP协议中会用到很多不同种类的XML标签,有些是自己作为顶级的标签,另外一些是
被包含在其他标签内部。这两种标签在本项目中分别被抽象为Packet和SubPacket
两种不同的类型。还有一种类型XMPPError也是Packet中的成员,它表示XMPP报文中
所包含的错误信息。类型结构如图\ref{fig:ch06.pkg.class.png}所示:
序列化为XML的过程如下图\ref{fig:ch06.toxml.png}所示:
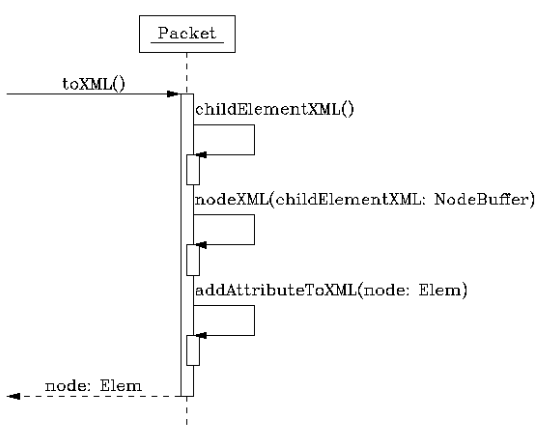
-
childElementXML()方法把Packet类中的子标签都转为XML文本。 -
nodeXML()方法生成标签主体。 -
addAttributeToXML()把几个大多数标签中都通用的属性添加到当前的标签中。
nodeXML()方法是一个虚方法,子类中可以通过实现这个方法完成当前标签。以iq标签
为例,直接把子元素的序列化的XML文档嵌入到iq标签中:
def nodeXML(childElementXML: NodeBuffer): Elem = {
<iq>{childElementXML}</iq>
}
iq标签会有额外的两个属性id和type,通过覆盖addAttributeToXML()方法来添加
这两个属性。nodeXML()方法定义了如何生成iqXML标签的行为。
override def addAttributeToXML(node: Elem): Elem = {
super.addAttributeToXML(node) %
Attribute(None, "id", newTextAttr(id),
Attribute(None, "type", newTextAttr(msgType.toString), Null))
}